

Databázové procedury jsou jednou z vývojářských praktik, na kterou většina aplikačních vývojářů, podle mého názoru, hledí se značným despektem. Jsou využívány u velkých aplikací v bankovnictví nebo telekomunikacích, ale u menších a středně velkých aplikací současné trendy spíše směřují k objektově-relačnímu přístupu (ORM). Kde to jen jde, je snaha „zadrátovat“ práci s daty do aplikační vrstvy. Kámen úrazu ale většinou nastane, pokud se nároky na zátěž aplikace zvýší nebo je včleněna do podnikové infrastruktury.
Výkon, bezpečnost a závislost
Díky separování práce s daty a vlastních dat mezi různé vrstvy (aplikační/prezentační a datová) jsou přenášeny zbytečné objemy dat, které přitom mohly zůstat v databázi. Slabou stránkou v tuto chvíli je nejen vysoká zátěž způsobená přenosem po síti, ale také bezpečnost, protože databáze nechává napospas klientské aplikaci celou svoji strukturu (aniž by to bylo vůbec potřeba). Jakmile začne aplikace růst, obvykle se ozývají hlasy, že databáze je pomalá a nestíhá s výkonem. Opak je pravdou – databáze je rychlá, pouze díky velmi špatnému návrhu aplikace musí pracovat s větším objemem dat, než je nutné. Po stránce bezpečnosti mají databázové procedury ještě další výhodu. Obsahují typovou kontrolu a díky tomu jsou odolné vůči útoku script-injection, o kterém je v poslední době slyšet poměrně často.
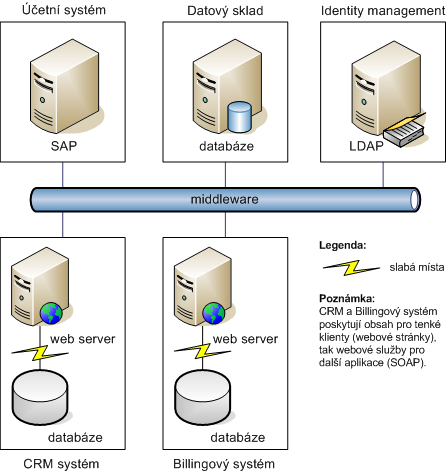
U rozsáhlejšího systému je velkou výhodou centralizovaná logika. Změny výpočetních algoritmů můžete provádět na jednom místě (v databázi), aniž musíte zjišťovat, kde všude je logika „zadrátovaná“. Také je asi zřejmé, že pokud je pomalá práce s daty, bude pomalý i celý zbytek systému. Jistě lze namítnout, že logiku můžeme centralizovat přímo v aplikaci a v rámci firemní struktury ji poskytovat jako webovou službu. To je sice možné, ale stále se nezbavíme velkého objemu zpracovaných a přenášených dat (úzké hrdlo architektury je zobrazeno na obrázku).
Výhody databázových procedur
Smyslem databázových procedur je přenesení logiky, která pracuje s daty, na stranu databáze. V rámci jednoho volání z aplikační vrstvy tak máme možnost s daty provést všechny potřebné operace a předat pouze výsledek, který je okamžitě použitelný. Zároveň se nám nabízí velmi široký arzenál funkcí, který můžeme v databázi aplikovat – počínaje analytickými funkcemi pro statistické výpočty, logování, auditování a konče nepřebernými technikami ladění. Aplikační vrstvě zůstává tato logika zcela skryta a je jí poskytnuta pouze služba ve formě rozhraní (API), přes které databázi volá.
Pro názornost uvažujme aplikaci mobilního operátora, která plní funkci účetního systému evidujícího zaúčtované operace (volání, SMS, MMS atd.). Periodicky je generován report složený z více dotazů, který je formou faktury zaslán zákazníkovi nebo je zpřístupněn na webu. To vše samozřejmě v hromadném zpracování (dávce), vždy pro část zákazníků se stejným zúčtovacím obdobím. Je rozumné všechna data zpracovávat na aplikační vrstvě nebo dávku zpracovat v databázi a aplikační vrstvu nechat výsledek pouze využít? Odpověď je asi zřejmá. U velkých objemů dat může takováto operace trvat i několik hodin a osobně se domnívám, že čím méně vrstev do tohoto zpracování zasahuje, tím lépe. S tím souvisí i stabilita databázového spojení, kterou je potřeba udržet, protože při jeho „vytuhnutí“ provede databáze automaticky zrušení celé transakce.
Velkou výhodou je skutečnost, že jednotlivé vrstvy zajišťují pouze to, k čemu jsou určeny: aplikační vrstva aplikační logiku a datová vrstva práci s daty. Optimalizace tak může probíhat na jednotlivých vrstvách nezávisle a je jedno, jestli v databázi uplatníme refaktoring procedur, provedeme denormalizaci tabulek nebo zvolíme jiné techniky ladění (přístup optimalizátoru, materializované pohledy, partitioning atd.).
Druhá strana mince
Jednou z častých výtek bývá příliš velká závislost na databázi, protože každý databázový systém poskytuje jiný soubor funkcí a zároveň se liší i jednotlivé postupy při ladění. Je-li naším cílem vytvořit obecný přístup, který bude fungovat na více platformách, zpravidla se ochuzujeme (ať záměrně nebo ne) o výkonné funkce, které jsou závislé na konkrétní databázi. Ani základní vlastnost, jako je inkrementace primárního klíče, není implementována na všech platformách stejně (jedna využívá typ increment, další zase sekvence). U složitějších funkcí, které ovšem přinášejí největší výkonový rozdíl, je to podobné.
Pro zákazníka není důležité, jestli aplikaci může nasadit na více databázích. Zajímá ho, jestli dobře (a dostatečně rychle) funguje na té jeho.
Vývoj aplikace pro více databázových systémů není jednoduchý a vůbec ne levný, proto si položím filozofické otázky:
- Jaká je pravděpodobnost, že naše aplikace bude využita na jiných databázových platformách? (U velkých organizací téměř mizivá. I menší projekty fungují stabilně na jedné databázi, ať už se jedná o MySQL nebo PostgreSQL, a jejich portace na jinou platformu je spíš výjimkou.)
- Vyvíjíme krabicový produkt, který budeme nabízet zákazníkům využívající rozdílné databáze? (Skutečně si můžeme dovolit luxus, abychom aplikaci činili takto přenositelnou?)
Porovnání přístupů
Volání SQL dotazů
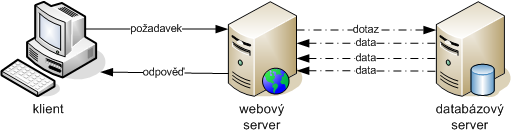
Výhody:
- jednoduché na naučení (žádné znalosti kromě základních SQL příkazů),
- nezávislost na databázi (relativní).
Nevýhody:
- přenášení/zpracování velkého objemu dat,
- nízká bezpečnost (script injection, přenášení nadbytečných dat pro mezivýsledky),
- malé možnosti pro ladění a refaktoring,
- nižší výkon v porovnání s databázovými procedurami.
Volání databázových procedur
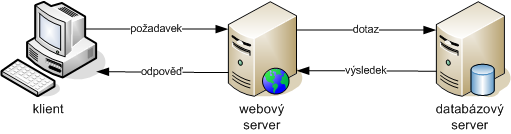
Výhody:
- přenášení pouze výsledku,
- vysoká bezpečnost (typová kontrola, struktura databáze a dat skryta další vrstvě),
- nástroje pro ladění často dostupné přímo od výrobce, zároveň ladíme odděleně podle vrstev,
- provádění refaktoringu nezávisle na klientech a jiných částech systému,
- vysoký výkon (možnost použití nativního zpracování),
- možnost vyžití funkcí databázového serveru (analytické funkce, audit, práce s XML a další),
- kontrola závislostí mezi objekty v době překladu (nikoliv runtime).
Nevýhody:
- složitější na naučení (se znalostí základních SQL příkazů si nevystačíme),
- závislost na databázi daného výrobce (Oracle PL/SQL, Microsoft T-SQL a další).
Závěr
Samozřejmě ani databázové procedury nejsou optimální za všech okolností. Třeba práce s objekty v postrelačních databázích není vůbec jednoduchá a celý proces ještě více znepříjemňuje mapování objektů mezi aplikační a datovou vrstvou. Například v databázi Oracle je nutné vytvořit pro objekty tzv. deskriptory, o kterých toho v české literatuře mnoho nenaleznete. Jestli jsou databázové procedury tou správnou volbou, závisí především na rozsahu a využití konkrétní aplikace. Příkladem, že databázové procedury nemusí být vhodné ani pro velké projekty, je třeba aukční portál eBay [ http://www.addsimplicity.com.nyud.net:8080/downloads/eBaySDForum2006-11-29.pdf ]. (Nejedná se o výjimku potvrzující pravidlo?)