 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
laik
On zase Google nefunguje? Mně tedy ano – http://www.google.com/search?q=how+to+read+ini+c%2B%2B.
Příspěvky odeslané z IP adresy 85.70.13.–
Sony
nevíte někdo o nějakém způsobu jak se vyhnout psaní spousty funkcí kde každá vrací jednu svoji nějakou privátní proměnnou?
Zaprvé bych zkusil zvážit, jestli je opravdu potřeba tolika privátních proměnných. A pokud by to opravdu potřeba bylo, použil bych nějaké automatické generování těch metod – doporučuji si přečíst knihu Code Generation in Action (dá se sehnat její PDF verze ke stažení).
DaveX
Zkus phpinfo()[1], to ti poví víc. Pokud v seznamu extzenzí cURL není, nemají ji tam nainstalovanou.
[1] http://php.net/phpinfo
BB
Kde je přesně problém? Jelikož se nepokoušíš ani o implementaci, tak to vypadá, že vůbec v návrhu programu. Je to jednoduché – v první části získáváš údaje, nebo-li posíláš na výstup otázky a čteš vstup. Doporučuji nějaký začátečnický tutoriál, aka Hello world!, a pár lekcí po něm. Údaje o velikosti jednotlivých koeficientů bych načetl do nějaké dynamické lineární struktury (spojový seznam), nebo dynamicky alokované pole.
Součet je ještě jednodušší – v cyklu se projedou obě struktury a prostě se jen posčítají odpovídající koeficienty. Zase umístit do odpovídající lineární struktury.
Na součin je jednoduché pravidlo – „každý s každým“. Každý člen prvního polynomu v cyklu vynásob se všechmi členy druhého polynomu a výsledek opět ulož do nějaké lineární struktury (pozor na výsledný stupeň členu).
S výstupem si můžeš pohrát dle libosti.
puainthecity
na mém PC mi překladač vyhodí error, ale na jednom počítači to úplně stejný překladač překompiloval zcela bez problému...
A co kód kolem? Jakou chybu překladač přesně vyhazuje?
spousta velmi pokročilých Céčkařů neví čím to je
:o)
crAzY^
myslím že system() funguje jen na win
system() je ve standardu C, takže to není windows-only záležitost.
jenoc
Proč mi program vypíše 0,12,18,20 když jsem odebral programu tuto paměť? Mám to chápat tak, že sice programu odeberu paměť, ale hodnoty stále v paměti jsou?
Nač hodnoty v paměti něčím přemazávat (nulovat kupříkladu)? Alokováním paměti se ubere blok, uvolněním se vrátí libc, která se o to stará. Většinou jsou adresy navrácených bloků ukládány na tzv. free list. A pokud se pokusíš alokovat znovu, libc se nejdříve koukne na free list, jestli se tam nachází blok potřebné velikosti, a jestli ano, tak ti ho vrátí.
Proč se tedy smaže 5?
Bůhví; záleží na implementaci alokátoru.
Nebo pouze dělám něco špatně?
Jen jedno doporučení, které s tímhle problémem moc nesouvisí: vždy kontroluj, jestli malloc() nevrací NULL ;o)
D-Fox
SimpleXML[1]?
[1] http://php.net/simplexml
Guga
jak zajistit aby dvě úplně odlišné třídy byly schopné přímo ovlivňovat navzájem svá soukromá data, aniž by ze sebe něco dědily
Určitě by to podle mě šlo pomocí pointerů. Ale zrovna moc dobré se mi to nezdá – odporuje to objektovému principu zapouzdření.
soudruh
ale v Opeře se vrátí pouze admin.php to za otazníkem již ne
Pořádně bych to otestoval, a jestli se to opravdu takhle chová, nahlásil bych bug.
Jinak v location.href by měla být adresa celá, z níž by to mělo jít regulárem vyseparovat,
herys
no odkazy mam v poradku na strankach timto neni
Věř mi, že tím, či nečím pododbným, to přesně bude. Roboti, i ten Googlu, jsou jenom stroje -- oni si prostě nemohou vymyslet, že to udělají takhle. Nějaký odkaz s toutu adresou někde na internetu je aroboti si ho vybrali jako ten nekdůvěryhodnější.
A presmerovani s hlavickou 301 znamena co prosim?
Ale no tak, lidi, naučte se už používat ten Google. Snad vás napsat těch pár písmenek nezabije? Nasypu tam pár klíčových slov a už to jede: http 301[1].
[1] http://www.google.cz/search?q=http+301
soudruh
Google > javascript url get anchor[1].
[1] http://www.google.cz/search?q=javascript+url+get+anchor
KIIV
kdyztak v pripade nejednoznacnosti by to vyhodilo chybovou hlasku
Na tuto možnost vývojáři PHP řekli ne kvůli autoloadingu – musely by se vždy načíst, mnohdy zbytečně, třídy, kde by mohl nastat problém.
namespace by se hodil treba do {} neco jako {one::step}::two()
Byl návrh, že jako zvýraznění toho, že se jedná o namespace by se provedlo pomocí „špiček“ (< a >). Takže např. <foo>::<bar>::baz() by jasně říkalo, že foo a bar jsou názvy namespaces. Současně by se ponechala možnost tyto závorky neuvádět a pak rozhodl by engine. Ale to někteří vývojáři odsoudili s tím, že se nechtějí podobat Perlu, kdy pro jednu věc existuje více možností zápisu.
ffmpeg – naproto bezproblémový, multiplatformní, velká podpora nejrůznějších formátů. Win32 Buildy – http://tripp.arrozcru.org/.
DragonBehemont
Když se na to podívám, tak vím, že je tam několik věcí špatně, ale zatím nemám ty zkušenosti, abych dokázal přesně určit, co je na tom špatně.
Zkus se podívat po internetu, prohlédnout si „CSS galerie“ apod. Hned uvidíš, kde a co se dělá jinak, a jestli se ti líbí více tamto nebo to tvoje. Porovnávej, dívej se, „inspiruj se“.
Nj, jenže, když ten text byl obyčejný, tak zase nešel přečíst. :-(
Opět, když se podíváš, kolik promile webů má všechno tučně? Tučné písmo se používá pro zvýraznění, vyzdvižení nějaké důležité informace, pro normální text se nehodí. A když to není písmem, tak bych se spíše díval na pozadí. Pokud má písmo na podkladu špatný kontrast, ztučnění moc nepomáhá.
DragonBehemont
Naprosto tragické. Můžu mít dotaz? Když se na to podíváš, líbí se ti to (snaž se oprostit od toho, že jsi to dělal, tudíž k tomu máš nějaký citový vztah)? Dokázal bys na takovémhle webu trávit čas, něco si tam přečíst? Mně osobně by, tedy krom té grafiky, kterou již zmínil pawlik, třebas velice vadilo, že ten text ke čtení je tučně.
jiM.sTREET
tak se mi to automaticky presmeruje
Jak přesně myslíš „přesměruje“? A děje se to „přesměrování“ už v rámci TCP/IP, nebo až na úrovni HTTP? Kdyby to bylo na té nižší úrovni, tedy TCP/IP, nejspíš by se jednalo o špatné přiřazení IP k doméně, kterou požaduješ. Zjisti si IP adresu daného serveru (např. tady je něco narychlo spíchnuté[1]) a zjisti, jakou adresu získáš u tebe (např. ping ukazuje, když dáš hostname, jakou získal IP adresu). Pokud by se jednalo o záležitost HTTP, IP adresa bude dobře, ale prohlížeč dostane odpověď, že má jít jinam. Chce to sledovat HTTP hlavičky (např. ve FF je na to rozšíření LiveHTTPHeaders[2]).
[1] http://publix.phorum.cz/resolve.php
[2] https://addons.mozilla.org/cs/firefox/addon/3829
*EDIT: jsem pomalý.
mirecekp
A kde je problém? Něco o PHP[1] a MySQL[2] se dá najít na linuxsoftu. O zjišťování věku z data narození se můžeš dozvědět třebas u Jakuba Vrány[3].
Jedna možnost, jak v MySQL zjistit, za kolik dní bude mít dotyčný narozeniny:
TO_DAYS(
CONCAT(YEAR(CURDATE()), '-',
MONTH(datum_narozeni), '-',
DAY(datum_narozeni)))
- TO_DAYS(CURDATE())Nejdříve se vytvoří datum, kolikátého by člověk měl narozeniny tento rok. Pak toto datum a dnešní datum převedeme pomocí fce TO_DAYS()[4] na počet dní od nějakého počátečního datumu, který je v MySQL nastaven. A rozdílem tohoto počtu dní je za kolik dní bude mít dotyčný narozeniny.
[1] http://linuxsoft.cz
[2] http://www.linuxsoft.cz/article_list.php?id_kategory=232
[3] http://php.vrana.cz/zjisteni-veku-z-data-narozeni.php
[4] http://dev.mysql.com/doc/refman/5.0/en/date-and-time-functions.html#function_to-days
lolik
Funguje ti síťová karta, resp. vytvoří nějaký interface? (Co vypisuje # ifconfig -a?) Jestli ne, bude potřeba se podívat po driverech.
Objevuje se ten interface ve výpisu # ifconfig? Jestli ne, je potřeba interface „pozvednout“ – # ifconfig eth0 up, kde za eth0 dosaď interface tvé karty.
Počítám s tím, že ten D-Link (jako většina těchto routerů) přiděluje IP adresy pomocí DHCP, takže funguje DHCP (má počítač přidělenou adresu)? Jestli ne, # dhcpcd eth0 (měl bys mít jedno z dhcpcd či dhclient; místo eth0 opět daný interface síťové karty).
Dokážeš router propingnout ($ ping ip-adresa-routeru)?
Jestli se všechno z toho daří, bude asi špatně nastaven router.
stepfun
Potrebujem mat zaroven turectinu(ISO8859-9) a slovencinu(ISO8859-2).
Tak to se obávám, že aby každá část souboru byla interpretována podle jiného kódování (! iso-8859-x, cp1250, UTF-8 atp. jsou kódování (znakové sady), nikoli jazyky), nelze.
Ak pouzijem UTF-8, tak to vobec nepomoze - turectina sa aj tak nezobrazuje spravne.
Zkus na tom pořádně zapracovat. Jsem si jistý, že znaky pro turecké písmo v Unicode určitě jsou.
Případně můžeš zvolit jedno kódování a ostaní znaky, které v něm nebudou, zapisovat pomocí HTML entit.
Peter P.
Pro MySQL:
http://php.net/mysql_query – podívej se na příklady, něco užitečného možná bude i v komentářích (nepročítal jsem je).
http://linuxsoft.cz – pročti si díly zabývající se prací s databází.
Sony
v praxi si můžou všechny objekty dané třídy navzájem číst soukromé proměnné
Pokud se jedná o třídní (statické, či jak se tomu v C++ nadává) proměnné, tak je mohou číst všechny objekty dané třídy, většinou slouží ke sdílení dat mezi více objekty, korigování chování jednotlivých instancí, nastavení globálního chování všech objektů dané třídy, či podobně. Objektové proměnné nejsou sdíleny všemi objekty dané třídy, ale každý objekt má svoje. Vyjadřují momentální stav objektu.
jde to udělat nějak aby to nešlo nebo si prostě musím vytvořit další třídu?
Nějak nechápu otázku. U třídních proměnných jde o to, že je mohou číst všechny objekty dané třídy, a objektové proměnné má každý objekt své.
aTTix
nemůžu za to, že jsem začátečník
Nevymlouvej se na to, že jsi začátečník. Za tohle by každý, kdo se takhle vykecává, zasloužil poslat do určitých míst... :o)
Určitě by ti neuškodilo si přečíst, jak se správně ptát[1]. A také bych nezapomínal na Google. Na SRP dotazu s kusem chybové hlášky[2] (či jiným kusem) bys něco najít mohl.
[1] http://www.hash.cz/inferno/otazky.html
[2] http://www.google.com/search?q=%22Error+result+-1073741515+returned+from%22
spartan13
Kurňa a já už myslel, že centrování s margin: 0 auto; je tak profláklé... No, asi ne. Podívej se třebas sem[1], je to první výsledek na dotaz css body center[2]. Všechno umisťuješ do toho obalovacího <div>u. Nastavením position: relative; přesuneš počátek systému souřadnic.
[1] http://www.bluerobot.com/web/css/center1.html
[2] http://www.google.com/search?q=css+body+center
spartan13
Prostě, aby to pozicování bylo jen v rámci těla (<body>) a tělo se vždy zarovnalo na střed.
Tělo zarovnej na prostředek normálně pomocí margin: 0 auto; (či podobně) a nastav mu position: relative;, čímž počátky souřadnicového systému jeho potomků již nebudou v rozích prohlížeče, ale v rozích tohoto elementu.
Hacky
<?php
$nadpis = "blablabl"; // původní nadpis, který nemusí být jedinečný
$jedinecny_nadpis = $nadpis;
$x = 1; // úvodní přidávané "počitadlo"
// ověřujeme ve smyčce, jestli nadpis existuje, a pokud ano,
while (nadpis_existuje($jedinecny_nadpis)) {
$jedinecny_nadpis = // tak vytvoříme nový
$nadpis . "-" .
$x++; // (se zvýšením koncovým číslem)
}
/**************/
// ověří, jestli nadpis existuje vybráním z databáze
function nadpis_existuje($nadpis)
{
return (bool) mysql_result(
mysql_query(
sprintf("SELECT COUNT(*) FROM tabulka WHERE nadpis = '%s'",
mysql_real_escape_string($nadpis)
)
),
0, 0
);
}PHP manuál:
konstrukt while - http://php.net/while
mysql_query() - http://php.net/mysql_query
mysql_result() - http://php.net/mysql_result
mysql_real_escape_string() - http://php.net/mysql_real_escape_string
sprintf() - http://php.net/sprintf
Sir_E
Jen mi není jasné, proč to musí být obráceně
Kompilátor asi nevyužívá Inteláckou, ale AT&T syntax (nebo obráceně, teď si nejsem jistý). (Neříkej hned, že je to špatně, je to prostě možnost.)
Také užité proměnné musí mít globální rozsah, což mi přijde poněkud "nešťastné".
U GCC např. jde určit, jaké hodnoty budou vstupními a výstupními (viz [1]).
[1] http://www.ibm.com/developerworks/linux/library/l-ia.html
Al
první nejbliží datum k aktuálnímu datu
where datum > $dnes
Jedná se tedy o první nejbližší (ať již budoucí, nebo v minulosti) datum, nebo o první nejbližíš a zároveň budoucí?
V první případě bych asi použil DATEDIFF()[1] a řadil podle něj. V druhém by se dalo použít to, co tu máš. Ale dávej si pozor na escapování hodnot (v MySQL musí být datum v apostrofech jako řetězec) a pořadí klauzulí v dotazu (WHERE musí být před ORDER BY) apod. A vždycky, bez výjimky, si vypisuj mysql_error()[2]! :o)
PS. Existují lepší možnosti, než si datum ,,připravovat`` v PHP. Což takhle NOW()[3]?
[1] http://dev.mysql.com/doc/refman/5.0/en/date-and-time-functions.html#function_datediff
[2] http://php.net/mysql_error
[3] http://dev.mysql.com/doc/refman/5.0/en/date-and-time-functions.html#function_now
dannyk, yaqwsx
Je to C-čkovská definice inline f-cí.
Není, inline funkce se definují pomocí klíčkového slova inline, #define definuje makro ;o)
v zápisu #define ... by neměl být na více řádků.
Ano, přesně tak.
Ykita
Řádky se však dají oescapovat pomocí zpětného lomítka (o což se tady v kódu asi někdo snažil), ale takhle olomítkovaný musí být každý řádek, bez výjimky.
#define ClampValue(VAL, min, max) { \
if (VAL < min) { \
VAL = min; \
} else if (VAL > max) { \
VAL = max; \
}(Dej si pozor, při kopírování kódu do schránky. Nevím proč, ale vždycky se mezi každý řádek vloží ještě jeden navíc. Vymaž je.)
*EDIT: imcold byl rychlejší :o)
UrbiCZ
Nejjednodušší podle mě bude buď absolutní pozicování (#menu li#prvni { position: absolute; left: 0; } #menu li#druha { position: absolute; left: 100px; ... } atd. atp.), nebo lépe display: inline-block;[1] a pozadí nenastavovat pro celé #menu, ale pro položku.
[1] http://bukaj.netuje.cz/know-how/horizontalni-menu-pomoci-display-inline-block/
marc_ramin
Což takhle cURL[1]?
[1] http://curl.haxx.se/libcurl/
Janina
existuje nějaký program, který zmenší velikost celé ikony ( anmované)
Zkusil bych GIMP[1] ;o)
[1] http://gimp.org/
Proc nas kurva komunikaci neuci ve skole?
Je to v myšlení lidí. Škola to jsou prostě vědomosti. Napráskat toho do hlavy co nejvíc, to je to hlavní. A vůbec, kdo by podle tebe takovou komunikaci měl učit? Dám příklad, co učí u nás na škole. Náš třídní, mladej kluk (možná už ženatej, ale nejsem si jistej), je velkej fanda biologie a zeměpisu, spíše tedy té biologie. Má našprtány velice důkladně poznávací znaky pár rostlin, co se dají najít v českých luzích a hájích. Jeho styl učení předmětu je takový, že si přečte učebnici, či nějaké svoje skripta z „výšky“ a co se tam dočte, nám předává. Zdá se mi, že to prostě jenom papouškuje bez hlubšího porozumění. Jak by takovýto člověk měl učit komunikaci, když vlastně sám ani neví, co mu „leze z huby“? :o) Další příklad je zase naše profesorka na ZSV. Ta akorát něco mele, přiblble se pousmívá a řekl bych, že neví která bije :o) Je to zástupkyně ředitele, takže jí spíš jde administrativa apod. věc. Bohužel se snaží i učit, a tak to vypadá, jak to vypadá.
Jiná věc jsou zase náš profesor dějepisu a naše češtinářka. U nich je prostě vidět, že je to učení baví, že o tom, o čem mluví, něco vědí a to, co vědí, předávají nám. Možná, že je to tím, že jsou prostě „ze staré školy“, ale na jejich hodiny se člověk jeden i těší – protože i když mě tyhle humanitní vědy moc nezajímají, tihle kantoři alespoň dokáží udržet mou pozornost. Ale zase, oni se soustředí na faktickou stránku věci (a tu ovládají moc dobře), učit komunikaci by nemohli.
Pak pomyslnou třetí skupinou by byli kantoři těch vědních předmětů (chemie, fyzika, matematika). Ty také ovládají, co vykládají, na jejich hodiny se i těším, ale obávám se, že na to, aby učili komunikaci, jsou také tak trochu „postiženi“ :o)
Shrnuto a podtrženo, bylo by dobré, kdyby na škole byl nějaké předmět komunikace. Nesměl by se ale zabývat tou faktickou stránkou věci (takhle se zdraví, takhle se loučí), ale samotnou komunikací, zkoušením, kritizováním, co by se dalo zlepšit apod. Ale hlavní problém podle mě je v tom, že není, kdo by to učil.
Umite komunikovat, manipulovat s lidmi?
Manipulovat asi ne, i když někdy si rád s lidmi pohrávám, když vím, na jakou strunu brnknout :o) Komunikace mi stejně Spectatorovi nědělá problém s opačným pohlavím. Nějak nechápu proč, ale připadá mi, že s ženami si mám víc co říct než s muži (alespoň těmi, co nejsou stejně „postiženi“ :o)). Když se někdo začne bavit o tom, jak dopadl včerejší fotbal (či si dosaďte jakýkoli jiný sport), automaticky vypínám :o)
insider
Můžeš se podívat např. na to, jak se kompiluje phpMinAdmin[1]. Taky něco o tomto tématu vyšlo na latríně[2].
[1] http://php.vrana.cz/phpminadmin-kompilace.php
[2] http://latrine.dgx.cz/jak-zredukovat-php-skripty
marioff
zatial som to pochopil tak ze v tej prvej premennej v RewriteRule je cesta ku suboru ktora je v URL…. (cize logicky subdomena/priecinky/)
Nejspíš máš na nějaké „vyšší“ úrovni udělané, pro URL sudomena.domena.tld se podstrčí domena.tld/sudomena, ne? Může to být někde výš v .htaccess, v .htaccess na vyšší úrovni či přímo v nastavení serveru (<VirtualHost …> … </VirtualHost>). (Možná, že se to nastavuje v nějaké aplikaci hostera?)
Mně na localhostu fungovalo i to, co jsem posílal poprvé. Používání té prvné části cesty jako sudomény bude závislé hosting od hostingu.
ale ako urobit aby sa ta tej subdomene podhodila (nie presmerovat 301) adresa v roote, teda test.com/index.php?…
Ale tohle, co jsi poslal, by mělo normálně pouze podstrčit, ne přesměrovávat. Zkusil bych přidat flagy [QSA,L] (první kvůli tomu, že jinak by v $_GET nebyl přístup k předaným proměnným; druhý, aby se již nic více nepřepisovalo).
maral
Tim, ze vytvorim instanci Menu, spustim celou aplikaci, a jednou z metod teto instance nasledne vytvorim i StartLevel
Zajímavý návrh aplikace :o)
No, pokud se mi udela StartLevel, tak uz jsem ve hre, hraju hraju, prohraju a tim se vratim do menu tak, ze se vytvori dalsi instance Menu...
Chápu správně, že ty vytváříš novou instanci Menu ve stejné metodě, kde vytváříš instanci StartLevel?
maral
jak se da trida znicit
Co to je za blbost ničit třídu? :o)
ktera vytvori novou tridu na menu, pak novou na hru […]
Ale fuj, jestli děláš opravdu tohle! Na začátku nadefinuješ třídy a jejich metody. A pak vytváříš instance tříd a těm nastavuješ vlastnosti. Pokud už objekt (instanci třídy) využívat nepotřebuješ, přestaneš ji referencovat a paměť se uvolní sama.
kezalb
O Zendu se můžeš dočíst např. na intervalu[1], o Caku zase jinde[2]. Ale proboha, říká ti vůbec něco pojem Google[3]? :o)
Pro širší náhled mezi PHP frameworky (nejen Cake a Zend) se můžeš podívat třebas na root[4].
A rada na závěr, nauč se anglicky číst (opravdu stačí jenom číst) alespoň na úrovni dokumentace ;o)
[1] http://php.interval.cz/zend-framework/
[2] http://ims.rockretail.com/
[3] http://google.com
[4] http://www.root.cz/serialy/velky-test-php-frameworku/
hrach
jak oproti prvnimu reseni jednodusi. ANO, NE?
Podle mě áno, podle mě je to i správnější a méně to zatěžuje databázi :o) U řešení vybrat to sakumprdum mě zase moc nepřitahuje to si hlídat, co teď mám, či nemám za post a nějak nechápu, jak by v tom seekování mohlo pomoci? Efektivní použití síkování by znamenalo si nejdříve vybrat, kolik má který post komentářů, ne? Nebo máš na to nějaký lepší fígl? :o)
Navíc, pokud jde o to vybrat posty a k nim komentáře, nebudeme přeci vybírat komentáře s informacemi o postu, ne? (Čistě teoreticky, jeden záznam v relaci odpovídá jednomu objektu. Ty vlastně chceš vybrat objekty typu Post, které budou mít, řekněme, vlasnost comments, která bude pole komentářů (objektů typu Comment). Ale když se to dá do jednoho dotazu, vyleze z toho vlastně objekt typu CommentWithInformationsAboutPost, a ne požadované posty.)
Řekl bych, že výkonostně to bude ztrácet při výběru hodně „širokých“ tabulek, či velké sady dat – bude se přenášet hodně redundancí.
A když budeš chtít vybrat posty s informacemi o jejich autorech (autorů může být více) společně s komentáři (komentářů samozřejmě také může být více) a odkazovat na komentáře, které na něj odpovídají (těch samozřejmě může být také více), budeš to všechno spojovat do jedné obrovské relace – hlavně aby to byl jeden dotaz?
lolik
sa da do apache na localhoste neieco stiahnut aby my islo fopen?
fopen()[1] chodí úplně normálně snad na každé instalaci Apache s PHP, nic dalšího se dostahovávat/doinstalovávat nemusí. Nebude spíše problém s chmod()em[2], či allow_url_fopen[3]?
[1] http://php.net/fopen
[2] http://php.net/chmod
[3] http://php.net/manual/en/filesystem.configuration.php#ini.allow-url-fopen
hrach
pokud provadím nějaký "asociační post-render" (= na jeden řádek použiji jich více) … Chci dotaz rozsirit na vyber 10 postu vcetne jejich komentaru.
Proč nepoužít 2 dotazy – proč nejdříve nevybrat posty a potom komentáže k nim? Proč to rvát celé do jednoho?
nughett
Nemůžu dohledat na internetu emulátor, který by emuloval soubory z macu.
Co to má umět ten „emulátor“? :o) DMG je diskový obraz, který obsahuje v adresářové struktuře zkompilované binárky, a pokud vím, žádný emulátor Macu pro Windows neexistuje.
Pokud jde jen o otevření, existuje utilita dmg2iso[1], která ti vytvoří iso obraz, který pak můžeš přimountovat např. pomocí Daemon tools[2] a soubory obsažené v obrazu si prohlížet, zkopírovat apod.
[1] http://vu1tur.eu.org/tools/
[2] http://www.stahuj.centrum.cz/multimedia/vypalovani_cd/daemon-tools/?g[hledano]=daemon%20tools&g[oz]=4.30.1
lolik
k com sluzi rss
http://en.wikipedia.org/wiki/RSS
aby sa tam ukazovaly prispevky s fora
Zaleží na konekrétní implementaci. Pokud se jedná o nějaké hotové řešení odněkud stažené, většinou je to zařízeno pomocí pluginů, či podobně.
KIIV
ja zminuju virtualni pamet proto ze na win swap neni
Swapu by na Windows odpovídal stránkovací soubor, nikoli celý mechanismus virtuální paměti. Pojem virtuální paměť, jak jsem psal, shrnuje mnohem více věci, než je pouhé odkládání na disk ;o)
beru jako virtualni to co neni v ram
Dobře, mně je to jedno – používej si co chceš. Pouze mi šlo o to, až si tohle někdo někdy, kdo o virtuální paměti neslyšel, přečte, aby nenabyl dojmu, že je pojem „virtuální paměť“ správné používat jen v tom úzkém významu, v jakém to chápeš ty.
Ale tohle je už dost OT…
KIIV
Virtuální paměť neznamená jenom to, že pokud je potřeba více operační paměti než v počítači fyzicky je, že se odkládá na disk. Virtuální paměť je jeden ze záklaních částí dnešních OS, který v praxi umožňuje vůbec to, aby na počítačí mohlo bezpečně běžeti více procesů najednou. Kernel (jádro systému) má neomezený přístup do celé paměti, kterou rozděluje na stránky.
Když se dá příkaz ke spuštění programu, zavede jádro jeho funkční kód a další data uložená v binárce do jedné, či více stránek v paměti. Takhle vznikne proces, což je jedna instance programu. Proces vidí, jako by pro sebe měl celou paměť (4GB na 32bitech) – tohle je virtuální, lépe řečeno logická* paměť. Ta je stejně jako fyzická rozdělena na bloky, na bloky stejné délky jako ty ve fyzické. A tyhle bloky se mohou nacházet kdekoli ve fyzické operační paměti, nebo klidně i na tom disku.
Principem virtuální paměti není to, že se odkládá na disk, ale to, že procesy mohou adresovat jenom svojí logickou paměť, která se fyzicky může nacházet kdekoli. A taky to, že procesy mohou využívat pouze adresy v této logické/virtuální paměti – fyzicky adresovat nemohou, to může jenom kernel.
Ta tvá definice je neúplná. Z Wikipedie, či nápovědy Windows? Odhaduji správně?
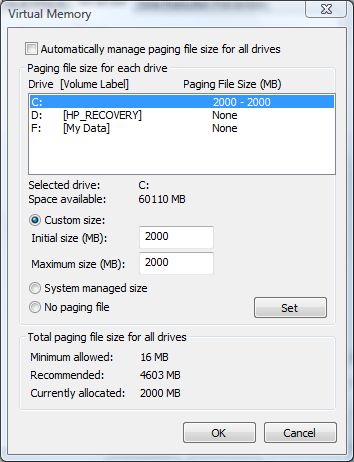
v nastaveni winu je to tam i jako nastaveni virtualni pameti nadepsano
Myslíš tento dialog, či jiný? Protože v tomhle se nikde nepíše o vypnutí virtuální paměti, ale pouze o nepoužívání stránkovacího souboru.
* Kvůli tomu, že virtuální paměť tu již používám jako označení její správy v kernelu.
djanosik
a také mohou ovlivnit výstup takového zvýrazňovače
Co je tím myšleno? Co může zvýrazňovač na výstupu změnit? Barvy?
to může člověka zbytečně ovlivnit ...
ale mimo ní tam může být ještě hromada featurek, které mohou vývojářům značně zpříjemnit práci / nabídnout jim více možností
Jasně, taky se na to ovlivňování někdy vymlouvám :o) Mohl bys tedy na konci (až nasbíráš dost nápadů) uveřejnit nějaký seznam, co by to mělo být za ty užitečné fičurky?
dannyk
K tomu bych pouzil asi binarni strom … Ale na to by se dal opet pouzit nejaky binarni strom v tom samem principu.
Ty jsi asi hodně zatížený na binární stromy, že? :o) Binární strom by navíc při přidávání měl složitost O(log N), normální hash O(1). Seřazení by podle mě nejjednodušší bylo procházet hash a použít heapsort (doufám, že to říkám správně; takové to třídění, jak tam „zaplouvá“ jeden prvek za druhým, čímž se řadí :o)).
velurex, KIIV
hash, hashmapa, map, mapa, slovník, dictionary, table (v Lue[1], i když tam je to kombinace hashe a pole)… Není to všechno jedno a to samé? :o)
[1] http://lua.org/
djanosik
Nějak nechápu, co bys chtěl do zvýrazňovače dávat jiného než nějaké barevné odlišení rezervovaných slov, operátorů, čísel, řetězců apod.? Samozřejmě by bylo hezké, aby dokázal zvýrazňovat několik různých ..jazyků“ v jednom dokumentu (např. PHP, ASP, ERb v HTML, doc-komentáře apod.).
Nechci zveřejňovat detaily.
Tajnůstkáři :o)
Garret Raziel
jednoduše bych do nastavení dal, aby si uživatel vybral, chce li, aby se závorky doplňovali, či ne
Tohle je jednoznačně funkce editoru, či podobného programu. Doplňování má od zvýrazňování hodně daleko. Jediná věc, co se by byla v kompetenci zvýrazňovače by bylo ukazovat odpovídající závorky (najedeš kurzorem na složenou na začátku ifu a zvýrazní ti to uzavírací).
Laik
ako to urobiťaby mi to vypísalo výsledok a aby sa mi to nevyplo?...
Když píšeš konzolové aplikace, pouštěj je normálně z konzoly (příkazového řádku), ne poklepáním, či podobně ;o)
dannyk
Pred return 0; napis 2x cin.get();Nebo by melo jit pouzit myslim i system("pause");
Ale fuj!
soudruh
seo_url nemusí být jedinečná, protože je tu ještě kategorie
Pak hodit UNIQUE index na sloupce seo_url a kategorie (UNIQUE (seo_url, kategorie)).
a zbytek je ošetřen v administraci.
Ale mít to ošetřené v databázi je jistota ;o)
klíčová slova jsou pro keywords i pro vyhledávání, takže dát do zvláštní tabulky?
Každopádně. V každé buňce tabulky by měly být jen atomické hodnoty. Takže pokud klicova_slova nebereš jako atom, měla by se rozdělit.
Dawblazen
Bujak
Hromy na tebe! :o)
Intepretery na "ručních" zařízeních žádný DTD parser znát nepotřebují.Stačí jim jen ten XML.
V tom případě, ale neparsují XHTML, ale jenom čisté XML.
Ale všechna zařízení všechno dohromady umět nemůžou.
V tom případě by stálo za zvážení, jestli nějaké ty specializované jazyky (WML) nebudou pro jejich účely lepší, protože když každé zařízení bude umět jen něco, nelze se na ně spoléhat. Lepší když ovládnou nějakou jinou specifikaci a to komplet, než z nějaké bude každé zařízení umět kousek.
Nemyslel jsem konkrétně velikost písmen, ale pravidla nevlídné syntaxe celkově.
Aha. Ale pokud vím, nevycházejí náhodou HTML a XML (tedy i XHTML) ze stejného značkovacího jazyka (SGML)? To je opravdu to, že je syntaxe HTML trochu „volnější“ tak hrozné? :o)
Kdyby se HTML 5 nevynořilo z hrobu, měli bychom ty nové vychytávky bezesporu i v XHTML.
HTML5 a vynořilo z hrobu? To snad už nemyslíš vážně :o) To spíše XHTML se snaží vyškrábat z hrobu pomocí XHTML2. Nejdříve to byl velký boom, „úplně nová“ technologie s X v názvu, prostě trhák. Když ale někteří zjistili, že je to akorát HTML4 s aplikací v XML, a tudíž nic nového nepřináší, přišlo velké vystřízlivění…
Když vidím lenochodí podporu CSS 2.1 tak si říkám, že vlastně ani není tak na škodu, když těch nových věcí bude v XHTML 2 méně než v HTML 5.
Kdybys věděl něco o schvalovacím procesu WHATWG a jak probíhá přijímání nových věcí do HTML5, tak bys tohle neříkal. HTML5 zavádí nové věci jen v případě, že vědí, že to prohlížeče implementují. Ian Hickson se již někokolikrát vyjádřil v tom smyslu, že do specifikace nechce dávat něco, co by stejně nikdo neimplementoval – aby to tam jen tak neleželo a stejně nešlo využívat. A pokud vím správně, mají kvótu, že musí být u každé věci alespoň dvě nezávislé implementace, než může být zahrnuta do závěrečné specifikace. Ale HTML5 hlavně upřesňuje hodně věcí, co si až doposud mohlo dělat každé jádro, jak chtělo.
Prohlížeč musí nejdřív celý dokument stánout, provést "parsaci" a pak se starat o skripty. Z principu fungování parseru nejde takhle za běhu načítání vkládat libovolný obsah.
Proto by mě zajímlo, jak se může parsování zjednodušit :o) Skript stejně proběhně až po parsování a to v každém případě. U document.write se akorát bude muset parser spustit vícekrát – nijak ho to ale nezjednoduší.
soudruh
tabulka s články mi příde příliš neoptimalizovaná
Jak podle tebe vypadá optimalizovaná tabulka? :o) A co přesně myslíš tou optimalizací?
Jinak, do sloupce klicova_slova se ukládá řetězec klíčových slov oddělných nějakým oddělovačem, že? Pokud je možné vyhledávání podle klíčkových slov určitě by měla jít do další tabulky, které by byla s touhle ve vazbě M:N. Pokud se ale používají jen např. do <meta name="keywords">, není to podle mě nutné.
Sloupce kategorie, autor a sablona jsou cizí klíče (foreign keys)? Hodil bych na ně samostané indexy.
Na sloupec seo_url by podle mě bylo dobré hodit UNIQUE index, aby dva články nemohly mít stejnou seo_url, což by znemožnilo hledání podle ní. Pokud se ale hledá podle id a seo_url slouží jenom jako předvypočítaná hodnota, není to potřeba.
KEY `seo_url` (`seo_url`,`kategorie`,`zobrazit`,`autor`,`precteni`,`klicova_slova`,`datum_vydani`,`datum_vytvoreni`)
Pro vytváříš jeden index nad tolika sloupci? :o)
Dawblazen
XHTML je jednodušší pro interpretaci
Podle mě mýtus. Nechce se mi psát něco, co již bylo jednou napsáno. Viz http://latrine.dgx.cz/konecne-pravda-o-xhtml-a-html#toc-mytus-parsovani-xhtml-je-mnohem-snazsi.
XHTML Basic je ořezán o spoustu tagů a to záměrně
Pořád mi uniká význam tohoto vykastrování XHTML… :o)
XHTML je rozdělené do modulů, které umožňují vymezit určité druhy tagů, je třeba aby prohlížeče na daných zařízeních (mobil, TV, monitor…) podporovaly.
Aha. Takže jestli to chápu, tak třebas výrobce mobilů si řekne, že bude podporovat tenhle a tenhle modul, v televizi to bude zase tenhle, tenhle a jestě tenhle modul… Každé zařízení bude podporovat vždycky pár modulů, ale žádné všechny. Takže stejně nebudu mít zaruřeno, že stránky, které napíši, se mi zobrazí na mém mobilu i televizi. Ke správnému zobrazování na různých zařízeních stejně bude potřeba, aby se implementovaly moduly všechny.
A jestli je ve specifikaci, že tenhle typ zařízení musí podporovat tenhle a tenhle modul, jiný typ zase tyhle moduly, XHTML se akorát rozvětvuje na víc „podjazyků“, kdy každý umí trochu, ale dohromady umí prd :o)
Mám takový divný pocit, že dokavad tu bude HTML vždy tu bude takové to "nepříjemné dusno" které tu panovalo v dobách HTML 3.2. Mám strach, že se to bude opakovat. Ale to je asi můj individuální názor - nevím, ale nějak mi to "dusno" s XHTML nejde dohromady..
Tak to by mě dosti zajímalo, co je přesně myšleno tím „dusnem“?
XHTML má jistá syntaktická pravidla, která je třeba dodržovat bez vzniku chyby (i blbá velikost písmen). Ta pravidla v HTML jsou prostě hnus.
Teď by se tady měl objevit někdo, kdo programuje ve Visual Basicu :o) Či prostě někdo, kdo používá Windows. Jelikož Windows je, co se týče názvů souborů, „case-insensitive“, je to automaticky hnus? ;o)
XHTML je jednodušší na naučení, než HTML
XHTML je přísnější, dává menší prostor, resp. nedává žádný (metodika oko za celou tvou rodinu :o)), pro nějakou chybu. A v začátku člověk dělá hodně chyb. Proto bych spíše řekl opak. Podle mě se nedá tvrdit o jakémkoli jazyku, že je jednodušší na naučení než jiný.
Tagy v HTML 5 by mohly být stejně tak přidány do XHTML 2.0
Mohly, ale nebudou. Hlavní rozdíl je, že v na HTML5 se aktivně pracuje, pořád přibývají nové nápady a do specifikace se dostávají věci, které dříve nebyly specifikovány a každý prohlížeč se v nich choval trochu jinak.
V XHTML 1.1 nefunguje document.write, což je jedině dobře - a je to opět z důvodu parsování.
Aha. Takže bez document.write bude parsování zase o chlup jednodušší? :o)
Dawblazen
syntaktický řád (když vidím některý zdrojový HTML kódy chce se mi zvracet)
Mně taky. Což ale není chyba HTML, ale toho, kdo to píše. Ale je pravda, že HTML je v těchto věcech hodně benevolentní.
jsem zásadně proti nesémantickým tagům,kterých je v HTML mraky a pochybuju,že to bude řešit pětková verze HTML
A stejně tak jich jsou mraky v XHTML ;o) A budeš se možná divit, ale HTML5 přináší dost nových sémantických značek. Doporučuji si o něm něco přečíst.
jak řeší HTML 5 podporu v mobilních prohlížečích (viz XHTML Basic)?
Jestli jsem to pochopil, není XHTML Basic akorát XHTML osekané o nějaké prvky? V čem je to tak skvělé? :o)
a tak bych mohl pokračovat...
Jen pokračuj ;o)
Ykita
./configure tu nemám mám tu jen soubory pro make. Což bych řekl, že je asi problem.?
Není, sice to nepoužívá autotool, což by hodně práci usnadnilo, ale konec světa to také není. Holt se asi budeš muset pohrabat v těch Makefilech.
Většina těchto erroru je z includu bych řekl.
S tím bych souhlasil. Něco se neincluduje a hned tam naskáčou ty chyby v deklaracích.
Na Počítači společnosti od které mám tento projekt to prý jede..
Tak to jim můžeš vyřídit, že to je sice hezké, ale tobě k h*vnu :o)
Proto se ptám zda-li to nejde nějak obejít?
Těžko. Nejjednodušší je nastavit kompilátoru správné cesty ;o)
Jinak bez toho kódu, Makefileů a dalších věcí jen těžko říct, co by mohlo být špatně. To je pak už jenom zbytečné hádání.
Beranek
ze pokud se ve sloupci opakujou hodnoty tak se pro ne vytvori nova tabulka
Já to ještě jednou zopakuji: „hodně záleží, o co se jedná a čeho chceš dosáhnout“.
Řekněme že máme tabulku články se sloupci název (typu varchar), text článku (text), vydáno (datime) a povolit komentáře (booleovská hodnota). Jak je vidět, sloupec povolit komentáře může nabývat jen dvou hodnot (TRUE, FALSE), které se tam budou pořád opakovat (v jakém poměru závisí na ukázněnosti komentátorů :o)). Myslíš, že by se pro takové hodnoty měla vytvořit další tabulka?
Chvíle na rozmyšlenou…
Ne, samozřejmě, že ne. Za Á by to bylo zbytečné, za Bé to nemá žádný důvod. U normalizace nezáleží na tom, jestli a kolikrát se hodnoty ve sloupci opakují, nebo ne. Zkus si pořádně přečíst ten odkazovaný článek a i jiné, co najdeš.
Beranek
Podívej se třebas na článek o databázové normalizaci[1] a snaž se vecpat do co nejvyšší normální formy, jiný lék neexistuje. Taky hodně záleží, o co se jedná a čeho chceš dosáhnout – někdy může být nižší normální forma mnohem lepší na práci s ní a její výkon.
atributy provedeni,druh a material budou stale nabyvat priblizne 3 hodnot.takze se budou opakovat.
Pokud jsou závislé jen na primárním klíči, na celém klíči a na ničem jiném než klíči, je úplně jedno, kolika budou nabývat hodnot.
[1] http://programujte.com/index.php?akce=clanek&cl=2008071900-normalizace-relacnich-databazi
balaam
C jako neobjektově zaměřený jazyk bych nedoporučoval
Co si budeme povídat, ono to ÓÓPé taky není všechno :o)
Navíc, stejně jako v objektově orientovaných jazycích (jako je kupř. Java (, Smalltalk, i když tam to zase zas tak dobře nepůjde :o))) lze všechno patlat procedurálně, v jazycích, které jsou procedurální a nemají žádnou podporu pro objekty (jako je kupř. Céčko), lze psát kód, který se „objektově“ chová (viz kupř. taková Glib[1]).
OOP podle mě není o jazyku, ale o způsobu myšlení ;o)
[1] http://cs.wikipedia.org/wiki/GLib
petran
Doporučuji ti si pustit video o bootování linuxového kernelu na x86[1], u ostatních kernelů to bude pracovat na podobném principu. Pak snad pochopíš, co se ti Garret Raziel snaží říct.
Pokud jsi zkompiloval na Windows nějaký zdroják do spustitelné binárky (*.exe), s největší pravděpodobností se jedná o binárku formátu PE[2]. A k jejímu spuštění nejdříve musíš nabootvat nějaký kernel (ať se jedná o její spouštění přímo, či pomocí emulátoru).
To místo na disku, o kterém Garret Raziel mluví, se říká MBR (Master boot record)[3]. Jsou tam uloženy čistě a jenom zkompilované instrukce (tzn. že binárku formátu PE tam dát nemůžeš ;o)). Snad každý operační systém má svůj vlastní bootloader, ale existují i „samostatné bootloadery“, např. GRUB[4]. GRUB se zoděluje na dvě tzv. „stage“, kdy první, jak můžeš vidět v tom videu, se umisťuje do toho MBR, je malá kompaktní, musí být v Assembleru, druhá se stará o věci jako jsou video, filesystémy atd., ta už může být v Céčku (či nějakém vyšším-nižším jazyku). Stage2 tedy načte jádro operačního systému a to by teoreticky teprve pak mohlo načíst tvůj zkompilovaný kód ve formátu PE.
[1] http://excess.org/article/2008/08/oclug-august-kernel-walkthrough-boot-process/
[2] http://en.wikipedia.org/wiki/Portable_Executable
[3] http://en.wikipedia.org/wiki/Master_boot_record
[4] http://en.wikipedia.org/wiki/GRUB
mholec
mysql_spojeni("localhost","root","","db");
Používáš na ostrém serveru doufám správné údaje přidělené provozovatelem hostingu a ne tohle, že?
Nefunguje mi žádný mysql dotaz v index.php ani v ostatních include souborech.
Jak se to přesně projevuje? Vypisuje to nějakou chybu? Nevypisuje? Pak si vypiš po každém dotazu mysql_error()[1], to prozradí více.
[1] http://php.net/mysql_error
bugisoft
hlavne ma zaujima ten border ovalny
Google > css rounded corners[1].
a tiez odraz a shadow
Nejjednodušeji nějakým elementem s obrázkovým pozadím, který správně umístíš.
[1] http://www.google.com/search?ie=UTF-8&oe=UTF-8&sourceid=navclient&gfns=1&q=css+rounded+corners
Dusan R.
K temto parametrum potrebuju pristupovat i z jinych souboru a trid, proto jsem se rozhodl vytvorit globalni promennou
Dobře, ale nač to kopírování? Vždyť by stačilo vytvořit hlavičkový soubor, řekněme params.h:
extern int global_argc;
extern char **global_argv;A v souboru s main() pak akorát incializuješ:
#include "params.h"
int main(int argc, char **argv)
{
global_argc = argc;
global_argv = argv;
...
}Přikládám archiv s kódem pro větší názornost.
JannyM
Cannot send session cache limiter - headers already sent
Nauč se používat Google[1] ;o)
[1] http://www.google.com/search?hl=cs&q=Cannot+send+session+cache+limiter+-+headers+already+sent&btnG=Hledat&lr=
Dusan R.
do ktereho bych v metode main prekopiroval parametry dane pri spusteni pomoci prikazove radky
Nějak nechápu účel takového pole :o) Vždyť ty parametry už jsou jednou uložené. Mohu se zeptat, k čemu je potřebuješ mít ještě někde jinde?
Pote je treba pole inicializovat - to prave nevim jak.
Alokuješ pole, např. pomocí malloc()[1], následně každou jeho pozici pro řetězec, který tam potřebuješ dát (strlen()[2] ti vrátí velikost původního řetězce bez posledního nulového bytu, alokace zase např. pomocí malloc()), a nakonec překopíruješ pomocí strcpy() (což už vlastně máš) řetězce z původních pozic do nových. Plus to bude chtít ošetření, kdyby nebyl dostatek paměti (malloc() vrátil NULL).
[1] http://www.cplusplus.com/reference/clibrary/cstdlib/malloc.html
[2] http://www.cplusplus.com/reference/clibrary/cstring/strlen.html
Ykita
main.cpp:13:20: error: config.h: není souborem ani adresářem
main.cpp:14:24: error: confparser.h: není souborem ani adresářem
…
Tak to se nedivím, že se to nechce zkompilovat, když nemáš hlavičkové soubory :o)
Ty soubory co to píše, že schází tu mám, ale i tak to hází stejné chybky.
Když se v tom postupu píše o CVS, tak předpokládám, že se zdrojáky získávají checkoutováním repozitáře, že? A pak by problém mohl být v tom, že Makefile je sestavený na jiném stroji – tzn. s jinými cestami apod.
Teď záleží, kde ty soubory máš? V jakých složkách?
make běží podle všeho ve složce /home/lab22/Desktop/linux a cesty k hlavičkovým souborům pro g++ jsou:
-I/mnt/rot/Dev -I/usr/local/pgsql/include -I/mnt/rot/Dev/LINUX/common/include -I/mnt/rot/Dev/LINUX/login_svrPředpokládám, že ten projekt využívá „klasické“ GNU Autotools[1], pak by mělo stačit použít „svatou trojkombinaci“:
./configure ; make ; make install[1] http://en.wikipedia.org/wiki/Autotools
PS. Pouštět $ make -i nemá v tomto případě smysl. Když se něco builduje, prakticky vždy hodně, hodně vadí, když se něco nezkompiluje ;o)
PPS. Tyhle dlouhatánské chybové logy ukládej do souboru, který pak připojíš ke svému příspěvku. Tohle je strašné.
Ykita
Hlavně nechápu poslední dva body nevím jak to zkompilovat.
Tak přesně napiš, co nechápeš ;o)
Jestli nějak stím cvs nebo tak nevim..
S CVS budeš jen těžko kompilovat. Už z názvu (Concurrent Version System) je vidět, že to není žádný kompilátor :o)
Když to kompiluju samostaně přes gcc nebo make tak to nějak nejde..
Pak to asi bude rozbitý ;o)
Nezlob se, ale tvůj popis problému je k ničemu. Doporučuji si přečíst, jak se správně ptát[1]. Je sice hezké, že jsi sem zkopíroval celý návod, jak něco udělat, ale že bys taky napsal, o co vlastně jde (nějaká hra?), nebo odkud ten návod je, to ne. Taky napsat, že s „gcc nebo make to nějak nejde“ je k ničemu. Jestli to nejde, tak to pravděpodobně vypisuje nějakou chybu, ne? A jestli ano, tak tu chybu pošli. A hlavně zkus nejdřív pořádně Googlit[2], jestli nenajdeš nějaký lepší návod, nebo řešení té které chyby při postupování podle toho v návodu, který jsi sem zkopíroval.
[1] http://www.hash.cz/inferno/otazky.html
[2] http://google.com
Petr
umísťuju zde toto vlákno protože si myslím, že by se to dalo dělat pomocí php.
Tak to jseš vedla, jak ta jedle :o) Tady se bez Javascriptu jen těžko obejdeš.
mám checkbox a chci udělat aby tlačítko bylo neaktivní pokud checkbox nebude zaškrtnutý a jakmile checkbox někdo zaškrtne, tak tlačítko bude aktivní
Na nějakou smysluplnou událost (např. onclick) toho checkboxu navážeš svou fci, která zkontroluje vlastnost checked checkboxu a podle toho se nastaví vlastnost disabled tlačítka.
Paja2
Ale fuj. Kdo se v tom má vyznat? Doporučuji se podívat na řešení layoutů např. na positioniseverything[1] či wellstyled.com[2].
[1] http://www.positioniseverything.net/articles/onetruelayout/anyorder
[2] http://wellstyled.com/css-2col-fluid-layout.html
DAF-IT
slysel jsem ze s tim ma neco spolecneho mysql ale ted se dozvidam ze mam zmaknout php...
V tom bude ten problém, no :o) Doporučuji si přečíst seriál na linuxsoftu o PHP[1] (pokud to tedy chceš dělat v PHP; ale podle mě je pro nějaké jednoduché věci nejlepší) a navázat na to seriálem o MySQL[2]. V rámci sebepropagace jsem přidám ještě odkaz na článek o normalizaci relačních databází[3], kde se doufám dozvíš, jak se vyvarovat těch nejčastějších chyb při návrhu databáze.
[1] http://linuxsoft.cz/php
[2] http://www.linuxsoft.cz/article_list.php?id_kategory=232
[3] http://programujte.com/?akce=clanek&cl=2008071900-normalizace-relacnich-databazi
Jenda_CZ
ale co je mi platný když třeba nevím co mám doplnit místo "//akce, co má funkce provést"?
Trochu přemýšlej. Neboj, i když hodně lidí tvrdí, že ano, tak to nebolí ;o) Řekni si: „Co chci udělat?“ — „Pokud se změní obsah políčka pro kraj a je tam platný kraj, chci načíst do jiného políčka všechna města v tom kraji.“
Takže realizace může být následující:
1, Sleduješ událost onchange prvku, který obsahuje kraj. Pokud se kraj změní, zavolá se fce, kterou nadefinuješ, aby tu událost sledovala.
2, V té fce zjistíš, jestli je ve formulářovém poli platný kraj (takže třebas ověření, aby tam nebyla hodnota "Vyberte kraj") a je-li, zavoláš AJAXový požadavek na skript, řekněme, PHP skript.
3, V POST datech předáš skriptu proměnnou kraj. Ten ji využije a vybere z databáze všechny města, u nichž je takovýto kraj, a ty města potom vypíše (nejlépe v nějakém dobře zpracovatelném formátu jako je JSON, nebo XML).
4, Teď se „výpočet“ vrací zpět ke klientovi a tady se právě uplatní ta fce, kde je „//akce, co má funkce provést“. Znovu si řekni co potřebuješ („zpracovat a zobrazit data“). Takže data načteš (což je závislé na použitém formátu) a jelikož potřebuješ je všechny dát jako položky nějakého formulářového výběru, odstraníš všechny položky, co tam byly teď a postupně tam nastrkáš ty nové.
Jak jednoduché. Jenom stačí trochu přemýšlet ;o)
Jenda_CZ
Hned tady na programujte je seriál týkající se AJAXu[1]. Ten jsi si jistě také přečetl, že? ;o)
[1] http://programujte.com/index.php?rubrika=296-webdesign&sekce=362-ajax&kategorie=363-kurz-ajax
Ospalý Stanislav
Inspiruj se[1] ;o)
[1] http://www.colourlovers.com/
Smokie
Tych 9 riadkov, ktore som tu skopiroval som stale opakuju ... ze ten clovek s menom Aivar Raudkepp skoncil na 3. mieste (1. riadok) a kvalifikoval sa ...
To jsem přesně potřeboval vědět! :o) Pak tedy, pokud vstup rozdělíš vždy po těch devíti řádcích, můžeš použít k „parsování“ nějaký „jednoduchý“ regulární výraz jako:
preg_match("~^\s*
(?<umisteni>\d+)\s*
(?<kvalifikace>\d+)\s*\[(?<neco>[^\]]+)\]\s*(?<jmeno>[A-Za-z0-9 ]+)\s*
(?<body>\d+)\s*points?\s*
(?<tym>[A-Za-z0-9 ]+)\s*
(?<float>(?:\+|-)?\d+\.\d*)\s*(?<dalsi_jmeno>[A-Za-z0-9 ]+)\s*
(?<auto>[A-Za-z0-9 ]+)\s*
(?<druhy_tym>[A-Za-z0-9 ]+)\s*(?<dalsi_float>(?:\+|-)?\d+\.\d*)\s*
(?<treti_float>(?:\+|-)?\d+\.\d*)\s*
(?<stopy>\d+)\s*stops?\s*$~x",
$record,
$parsed
);
var_dump($parsed);Vezme to data z proměnné $record a naseká je do $parsed. Doporučuji poupravovat, co se může vyskytnout jinak, názvy výsledných indexů apod. Taky to zkusit pustit na nějaký větší set záznamů, jestli to dělá, co se od toho očekává.
Smokie
Pochop, že parser nemůže parsovat něco, co nemá žádnou specifikaci, žádný tvar. Tohle není formát, ale kopa znaků. Jestli je ta hra někde veřejně přístupná, hodil by se odkaz na ní, lépe na zdroj, odkud data bereš, ještě na specifikaci výstupního formátu, nejlépe na všechno. Jinak těžko něco říct. Když tak pošli, co zatím na „parsování“ máš, z toho se taky bude dát hádat, jaký to má vlastně tvar.
MZetko
Mám totiž ten doctype v samostatném souboru ... Meta tag a title jsou také načítany ze zvláštních php
To je právě ten problém. V každém souboru je BOM, takže nakonec se ocitnou tam, kde nemají. Zkusil bych nějaký pořádný editor (jediný opravdový editor je vim :o)), který ukládá UTF-8 bez BOM. Třebas takový SciTE jsem používal a tam se to dá nastavit, nebo PsPad by taky měl apod. Popř. otevřít soubor v nějakém hexa editoru a nežádoucí znaky ze začátků odstranit.
utajeny007
Slovník[1] používat neumíme? Máš blbé přihlašovací údaje. Co jsem našel, tak by pro ten balík PHP Home měly být nasledující:
host/server/atp.: localhost
login/uživatelské jméno/user name/atp.: root
heslo: rootJestli nenudou správné -- Google[2].
[1] http://slovnik.cz
[2] http://google.com
MZetko
Řekl bych, že BOM[1] :o) Stránku jsem si uložil, otevřel ve vimu a co nevidím:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<feff><feff><html xmlns="http://www.w3.org/1999/xhtml" xml:lang="cs">
<head>
<feff><feff><meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
...
<feff><feff><title>NewGame.cz - Pravý český herní portál</title>
...Ty zvýrazněné „tagy“ jsou způsob, jak vim informuje o tom, že tam je nějaký znak, který nemůže zobrazit. Takže se ti tam nějakým způsobem ocitly BOM signatury pro UTF-16, tam kde nemají, co dělat. (Docela by mě zajímalo, jak se to ti povedlo udělat :o)) Po jejich odstranění je dokument validní.
[1] http://en.wikipedia.org/wiki/Byte_Order_Mark
