

V další části povídání o garbage collection se zmíníme o nějakých těch základních algoritmech, které jsou používány pro stanovení živosti objektů a jejich uvolňování.
Pro zopakování, „garbage collection“ je termín používaný pro techniky automatické správy paměti. „Garbage collectorem“ pak nazývejme konkrétní způsob takové správy, konkrétní algoritmus, který se bude o paměť starat. V tomto článku si implementace těch základních popíšeme. Budeme k tomu využívat „pseudojazyk“, protože nám nejde o žádnou konkrétní implementaci, ale o pochopení principu. Jediné důležité, co zmínit o tomto jazyku, je asi to, že pro zjednodušení bude moci být návratová hodnota z funkce použita jako tzv. „l-value“ (levá hodnota, může být použita vlevo od přiřazovacího operátoru), komentář bude uvozen dvěma spojovníky (--) a ukončen koncem řádku, bloky se uvozují odsazováním (podobně jako v Pythonu), možnost několikanásobného přiřazení (a, b = b, a – prohodí a s b). (Pozn. Příklady algoritmů použité v článku jsou s menšími či většími úpravami přebrané z knihy Garbage Collection Algorithms For Automatic Dynamic Memory Management od Richarda Jonese.)
V podstatě existují dva typy takových collectorů – ty, které stanovují „živost“ objektů pomocí počítaní referencí (reference counting), a ty, které ji stanovují pomocí sledování referencí z objektu na objekt (tzv. „tracing“ algoritmy). Na první pohled se zdají oba termíny (počítání i sledování) velice podobné, ale jedná se o dosti odlišené druhy algoritmů. Počítací algoritmy mají pouze jednoho svého zástupce – ano, je nazýván reference counting. Samozřejmě existují různé pokročilé verze tohoto algoritmu, ale vždy se o něm mluví jako o reference countingu. Sledovací algoritmy, které si v tomto článku popíšeme a které jsou ty tzv. „základní“, jsou tzv. „mark & sweep“ a „copying“ (kopírovací) garbage collector.
Nadále v textu budou používány termíny jako „reference“ a „objekt“. Bylo by dobré si tedy osvětlit, co se pod nimi skrývá. Jako referenci tedy označme uloženou adresu objektu, pomocí níž můžeme k objektu přistoupit, objektem pak již alokované místo v paměti, na které ukazují reference. Jako referenci tedy můžeme označit například ukazatel známý z C, ale také adresu objektu nahranou v registru procesoru.
Tyto hodnoty (v registrech, adresy uložené na zásobníku) jsou označovány jako tzv. „rooty“ (kořeny) grafu objektů. (Pozn. Viz Graf [ http://cs.wikipedia.org/wiki/Graf_(teorie_graf%C5%AF) ].) Pokud na objekt vede nějaká reference z kořene (nemusí být přímá, ale i skrz jiný objekt), je objekt považován za dosažitelný, a tedy „živý“. Zato objekty, které nejsou jakýmkoli způsobem z kořenů dosažitelné, jsou „mrtvé“.
Reference counting
Jediným příkladem počítacího algoritmu (a nejspíše i jediným algoritmem toho typu, když nebereme v potaz jeho odvozeniny) je reference counting. My si zde představíme jeho nejjednodušší formu. Jak již název praví, je založen na počítaní referencí (reference count, zkráceně RC). Na začátku si představme haldu pomyslně jako jeden velký objekt. Jelikož na něj nijak neodkazujeme, má čítač referencí roven nule. Proto je tento „objekt“ uložen na tzv. „free-listu“ (implementačně se povětšinou jedná o lineární seznam). Každý objekt, jehož počet referencí je nulový, je ukládán na free-list. Reference z free-listu se nezapočítává do počtu referencí.
alloc(n) = -- najde místo pro objekt velkosti n
O = free_list
while O and not fit(O, n)
O = next(O)
return O
new(n) = -- alokuje objekt velikosti n
O = alloc(n)
if O is nil
error("Not enough memory")
RC(O) = 1
return O
Pro vytvoření objektu velikosti n pak voláme funkci new(n), která se pokusí alokovat potřebné místo pomocí objektů uložených na free-listu, nepodaří-li se najít dostatečné místo, vyvolá se chyba "Not enough memory", v případě úspěchu funkce vrací adresu právě alokované paměti. Jak lze vidět, o alokaci se nestará ani tak new() jako spíše alloc(). Na začátku se v cyklu prochází free-list a hledá se místo pomocí fit(), která nedělá nic jiného než, že zjišťuje, je-li položka seznamu dostatečně velká (tzn. velikosti n, či více). Také se v cyklu ověřuje, není-li už náhodou konec seznamu. Konec seznamu znamená, že není žádné volné místo. (Resp. v paměti mohou být volné objekty, ale
nejsou dostatečně velké.) Na konci je vrácena adresa objektu. Tato implementace alloc() je tzv. „first-fit“, což znamená, že hledá první (nemusí se však jednat o nejlepší) možnost.
ref(O) = -- referencuje objekt O
RC(O) = RC(O) + 1
return O
free(O) = -- navrátí objekt na free-list
next(O) = free_list
free_list = O
delete(O) = -- uvolní referenci na objekt O
RC(O) = RC(O) - 1
if RC(O) == 0
for C in children(O)
delete(C)
free(O)
ref() nám zde slouží pro inkrementaci počítadla. Pouze tedy zvýší reference count předaného objektu o jedna a vrátí objekt. Takže se dá říci, že ref() nám objekt udržuje při životě. delete() zde slouží naopak k uvolnění reference na objekt. Pokud je počítadlo na nule, je nejprve potřeba uvolnit reference na všechny „děti“ uvolňovaného objektu, následně můžeme objekt odalokovat, což v této implementaci je to samé jako navrátit objekt na free-list, o což se stará free().
Tento algoritmus popsaný v pseudokódu je velikým zjednodušením, co dělají dokonce i ty nejjednodušší collectory založené na reference countingu. Například zde vůbec není řešen případ, kdy velikost nalezeného objektu na free-listu je větší než požadovaná. (Čistě teoreticky na začátku programu obsahuje free-list, jak již bylo psáno, pouze jeden objekt, objekt velikosti celé haldy. Po první alokaci by tedy byl odstraněn, seznam by zůstal prázdný a žádná další alokace by nebyla možná.) Dále by stálo také za zvážení, jestli by se nevyplatilo do seznamu vkládat objekty seřazené podle adresy, čímž by se dalo umožnit jejich slučování (tj. pokud máme objekt na adrese x velikosti 10 a objekt na adrese x + 10, můžeme je sloučit do jednoho, čímž dostaneme objekt větší, takže je větší pravděpodobnost, že bude vyhovovat při další alokaci).
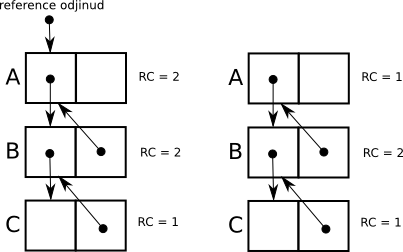
Reference counting je jistě zajímavým řešením pro garbage collection. Jeho implementace je také velice jednoduchá. Někdy je též uváděn jako tzv. „naivní algoritmus“. Což je ovšem spíše zapříčiněno důvody, které ho odsuzují (alespoň v této nejjednodušší formě) nevhodným pro dnešní aplikace. Jeho největším problémem je nemožnost uvolnit cyklické objekty. Po uvolnění všech referencí z vně cyklu reference count objektů uvnitř nemůže nikdy klesnout na nulu, ale objekty nejsou dosažitelné z kořenů, tudíž mrtvé, tudíž by měly být uvolněny.
Problém ale také může být ve vysoké náročnosti na procesorový čas i paměť. Ostatní algoritmy se spouští pouze tehdy, je-li jich opravdu potřeba, zatímco reference counting něco spotřebuje při každém referencování i uvolňování objektu. Na druhou stranu čas strávený na správě paměti je, dá se říci, rovnoměrně rozložen po celý běh našeho programu, proto je vhodnější do systémů, kde je potřeba stále stejná odezva – „real-time“ systémů. Paměť pro uložení počítadla by také měla být stejně velká jako šířka jednoho slova, protože teoreticky mohou na objekt vést reference z celé paměti. Ve většině případů ovšem stačí menší velikost.
Mark & sweep
Prvním algoritmem pro garbage collection vůbec byl mark & sweep, který dokázal předběhnout i „primitivnější“ reference counting. Jeho první použití se může datovat do roku 1960, kdy John McCarthy potřeboval collector pro svou implementaci Lispu. (Pozn.: Do té doby měl Lisp, i když se to nezdá (kromě mraku závorek je první věcí, která se mi, když se řekne Lisp, vybaví, je právě garbage collection), správu manuální.)
new(n) =
O = alloc(n)
if O is nil
mark_sweep()
O = alloc(n)
if O is nil
error("Not enough memory")
return O
Základní funkcí, která nám vrátí alokovaný objekt, je pro změnu opět new(). Pro jednoduchost je znovu použita funkce alloc() z příkladu na reference counting – z čehož plyne, že uvolněné objekty se zase skladují na free-listu. Když se poprvé nepodaří objekt alokovat, situace pořád není ztracena – mohou zde zbývat nějaké mrtvé, avšak prozatím neodalokované objekty – proto se pokusíme tyto objekty uvolnit. Podařilo-li se, vidíme hned poté, kdy se pokusíme alokovat znovu.
mark_sweep() =
for R in Roots
mark(R)
sweep()
mark(O) =
if not marked(O)
marked(O) = true
for C in children(O)
mark(C)
sweep() =
N = Heap_bottom
while N < Heap_top
if not marked(N)
free(N)
else
marked(N) = false
N = N + size(N)
Celé uvolňování se prakticky řídí tím, co jsme psali o mrtvých a živých objektech. Živý je objekt tehdy, je-li dosažitelný z kořenů (Roots). Proto tyto kořeny projdeme a všechny objekty, kterých se nám tímto způsobem podaří dosáhnout, označíme. Označený objekt rovná se živý objekt. Nakonec projdeme celou haldu a všechny objekty, které nejsou označené, můžeme odalokovat (v tom případě umístit na free-list).
Mark & sweep má oproti reference countingu jednu nespornou výhodu – cykly pro něj nejsou žádnou překážkou. Taky spotřeba paměti i procesorového času je menší – na označení objektů v „mark phase“ (fáze označování) stačí jediný bit a není potřeba pořád upravovat reference count objektu. Problémem však je, že tato implementace mark & sweep collectoru je tzv. „stop-the-world“, což znamená, že v době běhu collectoru – „mark phase“ a „sweep phase“ – nemůže program vykonávat žádnou činnost. Čas strávený na „mark phase“ se odvíjí od počtu živoucích objektů, na „sweep phase“ je vždy stejný – vždycky je potřeba projít celou haldu. U reference countingu bylo zmíněno, že je vhodnější pro „real-time“ systémy, ale i u takové hry či přehrávače videa není žádoucí, aby nastaly zaznamenatelné pauzy. Proto se tato nejjednodušší implementace mark & sweep pro tyto případy naprosto nehodí. (Samozřejmě, že existují pokročilejší verze, které tyto problémy řeší.)
Dalším minusem pro mark & sweep je tzv. „fragmentace haldy“. Je důležité uvědomit si, že uvolňování objektů na haldě jen málokdy probíhá přesně v tom pořadí, v jakém byly i alokovány. V paměti se tvoří pomyslné „díry“. Navíc, pokud bychom implementovali volné objekty pomocí lineárního seznamu, kde by se při alokaci volný objekt rozdělil na dva – jeden požadované velikosti, druhý zbytkové, druhý by se vrátil zpět na free-list – mohly by vznikat objekty tak malé velikosti, že bychom je nevyužili, a místo v paměti, které by zabíraly, by zelo prázdnotou. (Pozn.: Ve srovnání s následujícícm collectorem však toto „mrhání“ místem není až tak znatelné.)
Copying (kopírovací) collector
Druhým a zároveň posledním „tracing“ algoritmem, který si představíme je kopírovací algoritmus. Základem tohoto algoritmu je rozdělení prostoru na haldě na dvě části – rovnocenné části – kdy jedna je vždy aktivní, s druhou se nepracuje. Pro začátek tento collector tedy potřebuje určitou inicializaci.
init() =
Tospace = Heap_bottom
space_size = Heap_size / 2
top_of_space = Tospace + space_size
Fromspace = top_of_space + 1
free = Tospace
new(n) =
if free + n > top_of_space
flip()
if free + n > top_of_space
error("Not enough memory")
O = free
free = free + n
return O
Po inicializaci jako klasicky dostáváme do rukou alokační mechanismus v podobě funkce new(), která přijímá jako argument velikost nově alokovaného místa. Alokace znamená prosté zvýšení adresy jednoho ukazatele. Pokud se však již nevejdeme do místa na části haldy, je potřeba provést úklid.
flip() =
Fromspace, Tospace = Tospace, Fromaspace
top_of_space = Tospace + space_size
free = Tospace
for R in Roots
R = copy(R)
copy(O) =
if atomic(O) or O is nil -- pokud O není ukazatel
return O
if not forwarded(O)
n = size(O)
O' = free -- rezervuje místo na haldě
free = free + n
temp = O[0] -- první buňka původního objektu bude
-- držet forwarding_address
forwarding_address(O) = O'
O'[0] = copy(temp)
for i = 1 to n - 1
O'[i] = copy(O[i])
return forwarding_address(O)
Ten spočívá v prohození úloh obou částí – ta, co byla teď neaktivní, se stane aktivní et vice versa – a zkopírování živých objektů na novou aktivní část. Mrtvé objekty nás nemusí zajímat. Pouze udržíme živé dále živými tak, že je celé přesuneme na druhou, teď aktivní, část haldy. Mrtvé budou při dalším prohození částí přepsány novými daty, budou-li jim stát „v cestě“. Kopírování objektů zde poté probíhá způsobem stejným jako značkování u mark & sweep – od kořenů ke všem dosažitelným objektům. Jeden po druhém jsou poté přesouvány ze staré části haldy do té nové.
Kopírovací kolekce tedy probíhá velice zdlouhavě, kdy je potřeba všechny živé objekty přesunout z jedné části do druhé. Tento algoritmus je stejně jako předtím představovaný mark & sweep tzv. „stop-the-world“. Kvůli náročnosti celého přesunu tedy mohou být prodlevy ještě znatelnější než při použití mark & sweep. Co si však tento algoritmus vybírá na čistění, vrací při alokaci, která snad ani nemůže být jednodušší – postačí zvýšení jedné adresy.
Dalším problémem je rozdělení haldy na dvě stejně velké části, kdy stejně může být využita v čase jen jedna z nich – vždycky můžeme alokovat objekty v celkové velikosti pouze poloviční, nežli je velikosti haldy. Na druhou stranu nenastává fragmentace jako u mark & sweep – objekty jsou udržovány na spodku právě používaného prostoru, proto stačí k jejich adresovaní mnohem menší rozptyl adres. Dnešní operační systémy kvůli jejich použití virtuální paměti pro každý proces samozřejmě nemohou držet vše v operační paměti (na normálních domácích počítačích prostě tolik paměti není), proto „stránkují“. Stránkování spočívá v tom, že paměť procesu je rozdělena na stránky určité velikosti. Pokud proces ke stránkám (určitému rozsahu adres) zrovna nepřistupuje, mohou být klidně uvolněny z operační paměti a uloženy někam jinam (např. na pevný disk). V případě mark & sweep se tedy objekty mohou vyskytovat přes několik stránek, které mohou být, hlavně v případě menší paměti, stále a znovu načítány do paměti. U copying collectoru také mohou být také data přes více stránek, ale určitě to bude při stejném programu stránek méně.
Příští díl
Dnes jsme se zmínili o třech základních algoritmech garbage collection. Představené příklady jsou jejich nejjednodušší formy, které se hodí spíše jen pro akademickou debatu než použití v praxi. Proto se v příštím díle podíváme na zoubek některým technikám pro vylepšení těchto algoritmů.