

Přichází třetí díl miniseriálu o garbage collection, ve kterém se objeví některá vylepšení dříve popsaných algoritmů a také padne zmínka o generačních a inkrementálních metodách automatické správy paměti.
Deferred reference counting
Reference counting, jak bylo popsáno minule [ http://programujte.com/?akce=clanek&cl=2008061900-zakladni-algoritmy-garbage-collection ], pracuje na základě toho, že při každém použití objektu se zvedne jeho reference count o jedna, při jeho uvolnění naopak o jedna klesne. Takovéto přepočítávání referencí probíhá a musí probíhat pořád, což se samozřejmě musí projevit na spotřebovaném procesorovém čase. Přepočítávání však neprobíhá jen při přiřazení do proměnné (na haldě), ale také musí se též používat při ukládání na zásobník (aneb při volání funkcí). Nejvíce takových operací s čítačem se právě děje při práci se zásobníkem. Pokud víme, že se během volání funkce nemůže reference count objektu předávaného jako parametr změnit, můžeme referencování při volání funkcí vynechat. Takže se vlastně započítávají pouze ty, které míří na objekt z jiného objektu na haldě.
Problém ovšem je v tom, že nemůžeme objekt odalokovat hned, jak jeho reference count skončí na nule – stále zde mohou totiž být nějaké reference ze zásobníku. Jsou zde v podstatě dvě možnosti, jak toto řešit. Můžeme nechat, aby toto obstaral kompilátor – vše proběhne v době překladu –, což ale potřebuje právě spolupráci výše zmíněného kompilátoru. Pokud ale kompilátor nepíšeme sami, jen těžko ho k tomu donutíme. Pánové Deutsch a Bobrow však přišli s docela hezkým „run-timeovým“ řešením.
delete(O) = -- uvolní referenci na objekt O
RC(O) = RC(O) - 1
if RC(O) == 0 -- je-li počet referencí == 0, přidáme objekt
addToZCT(O) -- do ZCT
ref(O) = -- vytvoří referenci z haldy
RC(O) = RC(O) + 1
removeFromZCT(O) -- je-li objekt referencován z haldy, nemůže
-- mít RC == 0, proto ho můžeme odstanit ze ZCT
reconcile() = -- uvolní objekty, které nejsou referencovány
-- ze zásobníku, ze ZCT
for O in stack
RC(O) = RC(O) + 1
for O in ZCT
if RC(O) == 0
for C in children(O)
delete(C)
free(O)
for O in stack
RC(O) = RC(O) - 1
Objekty jsou po dosažení nuly na čítači přesunuty do tzv. „zero count table“ (zkráceně ZCT). Periodicky pak probíhá kontrola ZCT na přítomnost objektů na zásobníku, o což se stará funkce reconcile(), kdy je po zjištění, že na zásobníku nejsou, můžeme odstranit.
Problémem tohoto řešení je, že ještě zvětšuje náročnost collectoru na paměť. Navíc se mohou vyskytnout problémy s „přetečením“ ZCT. Její velikost se tedy musí volit „tak akorát“ – neměla by být ani příliš velká (její projití by pak trvalo taky zbytečně dlouho), ale nesmí být ani příliš malá, aby se na ní mohly vejít všechny objekty referencované pouze ze zásobníku. Pak již záleží na konkrétní aplikaci, co se více vyplatí – šetřit pamětí a nechat collector řádně zapisovat reference count při každém volání funkce, nebo radši vyhradit paměť pro ZCT a ušetřit tím dost práce při zvedání/snižování počtu referencí. (Pozn.: Některé zdroje uvádějí, že se může jednat až o 80% snížení času stráveného collectorem na těchto operacích. Na druhou stranu něco také spotřebuje reconcile(), takže se musí dost dobře rozmyslet, kdy a jak často se bude volat.)
Řešení problémů reference countingu s cykly
Cykly jsou pro algoritmy používající čítání referencí velký oříšek a žádné elegantní a jednoduché řešení tohoto problému bohužel neexistuje. Jsou zde prakticky tři řešení, kdy jedno se hodí jen pro jisté účely jistých jazyků, druhé maže největší výhodu reference countingu oproti jiným collectorům – rozložení správy paměti do běhu celého programu – a třetí je extrémně náročné na prostředky a v některých případech ani nepracuje správně.
- V čistě funkcionálních jazycích bylo zjištěno, že ve vytváření cyklů jsou jakési „zvyklosti“, proto s nimi může být zacházeno speciálním způsobem.
- Nejedná se o nic jiného, než použití mark & sweep collectoru, který jednou za čas projde haldu a uvolní cykly.
- Poslední řešení spočívá v rozlišování dvou druhů referencí – tzv. „silných“ a „slabých“ – a použití různých počitadel pro každý druh.
Pointer reversal – mark & sweep v konstantním prostoru
Minule ukázaný mark & sweep používal používal pro svůj „marking“ rekurzi. Je to elegantní způsob řešení problému, ale není zrovna moc efektivní – volání funkcí něco stojí a zásobník s každým voláním narůstá, takže v případě velice hlubokých stromů (což v dnešních objektových jazycích nemusí být nic výjimečného), může dojít k jeho přetečení („stack overflow“).
Prvním řešením, které se nabízí, je odstranit rekurzi. Převést do iterativní formy můžeme minulý algoritmus např. díky použití zásobníku objektů čekajících na označení. (Pozn. Zde se nejedná o zásobník procesu, ale i ten by se teoreticky dal využít.) Nejdříve uložíme na zásobník všechny objekty, které jsou v kořenech (Roots). V dalším kroku se již dostáváme k samotnému označování, kdy objekt označíme a všechny jeho neoznačené děti uložíme na zásobník. Tímto dokážeme ušetřit volání funkcí, ale pořád potřebujeme paměť na uložení zásobníku minimálně tak velkou, jako je výška grafu objektů.
Ovšem existuje zde i další řešení, které dokáže označit všechny dosažitelné objekty s využitím konstantní paměti.
mark(O) =
-- prvotní nastavení
done = false
current = O
previous = nil
-- hlavní cyklus
while not done
while i(current) < n(current) -- projdeme celý aktuální objekt
-- i(O) vrací číslo aktuálního dítěte O
-- (počítáno od nuly),
-- n(O) vrací celkový počet dětí O
C = child(current, i(current)) -- child(O, n) vrací n-té dítě O,
-- počítáno od nuly
if i(C) < 1 and not atomic(C) -- i(C) < 1 == not marked(C)
next = C -- další objekt k projití bude dítě
C = previous -- dítě nyní ukazuje na předchozí objekt
previous = current -- aktuální objekt se stává předchozím
current = next -- nyní je aktuální dítě
done = false -- a musíme ho projít
break
else -- pokud je dítě označené nebo se nejedná
done = true -- o ukazatel (je atomické -- nedělitelné),
i(current) = i(current) + 1 -- posuneme se na další dítě
if done and previous is not nil -- objekt jsme celý prošli, ale jelikož
-- previous není nil, nejsme zpátky u kořene,
done = false -- tudíž práce ještě jeskončila
up = child(previous, i(previous)) -- zjistíme objekt o úroveň výš
child(previous, i(previous)) = current -- navrátíme dítěti odkaz na objekt
current = previous -- vrátíme se na předchozí objekt
previous = up -- a předchozím objektem se stane ten
-- o úroveň výš
-- nyní má každý dosažitelný objekt O i(O) > 0; z čehož vyplývá, jak bude vypadat
-- sweep()
Celý „fígl“ je v tom, že místo zásobníku či jiného druhu uložení objektů, které čekají na to, aby byly dokončeny, se použijí samy objekty. Pomyslný zásobník je tedy rozprostřen po stromu objektů, které čekají na dokončení. Po dokončení objektu zjistíme, existuje-li objekt o úroveň výš, a pokud ano, vrátíme se do něj a pokračujeme s jeho procházením. Tato verze „markování“ má konstatní (O(1)) paměťovou složitost, předchozí měla složitost lineární (O(N)). Časová složitost zůstává pořád stejná – O(k), kde k je počet objektů dosažitelných z kořenů.
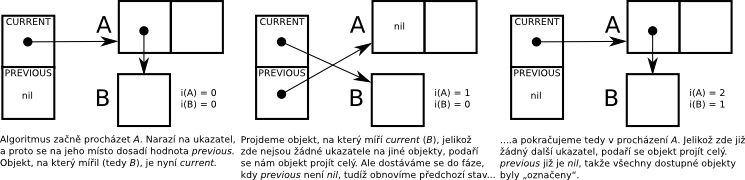
Negativem je, že ušetřené místo při procházení je vykoupeno prostorem, který musíme vyhradit pro skladování informace o aktuálním prvku každého objektu – už nestačí jediný bit, který by značil, jestli objekt byl nebo nebyl navštíven, ale je zapotřebí celé číslo s rozsahem 0 – m, kde m je maximální počet „dětí“, které objekt může mít. I když hodně dnešních systému se zabudovanou podporou garbage collection stejně objektům přiřazuje nejrůznější hlavičky, tudíž se tam může tato hodnota „ztratit“.
Mark & compact
„Klasický“ mark & sweep je hodně kritizován za to, že může docházet a taky že dochází k tzv. „fragmentaci“ haldy. Celková velikost volného místa na haldě spravované garbage collectorem může být dostatečná, ale jelikož je rozprostřena mezi několika malými bloky, nemůže být využita k alokování nového velkého objektu. Proto musela být nalezena metoda, jak bloky dostat těsně za sebe na jeden konec haldy.
Dnes nejvyužívanější je nejspíš tzv. „sliding“, který spočívá v tom, že všechny živé objekty jsou, stejně jak jdou za sebou, přesouvány na začátek haldy. My si zde ukážeme mark & compact pracující na tzv. „tabulkově-založené“ metodě („table-based method“).
mark_compact() =
for R in Roots
mark(R)
compact()
compact() =
relocate()
update_pointers()
Základní kostra je velice podobná mark & sweep algoritmu. Akorát místo funkce sweep() voláme compact(). Ta se již stará o uvolnění mrtvých objektů a úpravu ukazatelů mezi nimi. V první fázi se tedy všechny objekty přesunou na začátek haldy a vytvoří se tabulka, která nám pak pomůže vypočítat jejich nové adresy.
table = nil -- globální proměnné určující tabulku
table_size = 0
free = nil -- po přesunutí objektů na jednu stranu
-- haldy (po volání compact()) obsahuje
-- ukazatel na volné místo
zero_forwarding = nil -- adresa místa, kam půjde první přesunutý
-- objekt, adresy objetků do této není
-- potřeba měnit
relocate() =
-- inicializace
N = Heap_bottom -- adresa aktuálního prvku
free = Heap_bottom -- adresa volného místa
table = Heap_bottom -- adresa tabulky
table_size = 0 -- velikost tabulky
dead_size = 0 -- velikost mrtvých objektů
while N < Heap_top and marked(N) -- označené objekty na začátku haldy
N = N + size(N) -- není potřeba přesouvat
zero_forwarding = N -- na adresu N se přesune první objekt
free = N -- adresa N je první volná
table = free
while N < Heap_top
if not marked(N) -- pokud objekt není označen = je smetí,
dead_size = dead_size + size(N) -- takže vlastně volné místo
N = N + size(N) -- přejdeme na další objekt
else -- objekt je označen = musíme přesunout
moving(N, free, table, free + size(N)) -- přesun tabulky a objektu,
-- viz text pod kódem
free = free + size(N) -- volné místo je hned za objektem
table = free -- a tam je taky tabulka, do které
table[table_size] = (N, dead_size) -- vložíme nový záznam
table_size = table_size + 1 -- do tabulky byl přidán nový záznam
N = N + size(N) -- přejdeme na další objekt
Tabulka se vždy skládá z dvojic čísel, kdy první udává původní adresu objektu a druhé velikost doposavad uvolněného místa tvořeného mrtvými objekty. Za předpokladu, že každý objekt má velikost přinejmenším rovnou velikosti dvou procesorových slov, není potřeba alokovat místo pro tabulku mimo haldu – přesunutím každého objektu získáme místo pro jeho „řádek“ tabulky. O přesuny tabulky a objektu se stará funkce moving(), která řeší i případné kolize tabulky s právě přesouvaným objektem. Její konkrétní implementace není důležitá. Důležitý je pouze výsledek. A to takový, že objekt se přesune na adresu free a tabulka na adresu free + size(N) – tzn. na adresu free + velikost objektu, tudíž hned za objekt.
update_pointers() =
for R in Roots -- upravíme kořeny
R = forwarding_address(R)
N = Heap_bottom
while N < free -- a u každého objektu
for C in children(N) -- všechny jeho děti
C = forwarding_address(C)
N = N + size(N)
forwarding_address(P) =
if P < zero_forwarding -- adresa může zůstat stejná
return P
else -- jinak ji ale musíme najít v tabulce
l = 0 -- použijeme binární vyhledávání
r = table_size - 1
while l ≤ r
m = (r + l) / 2
a, s = table[m]
if m < table_size - 1 -- pokud existuje další dvojice,
a', s' = table[m + 1] -- použijeme ji
else -- ale pokud ne, znamená to, že jsme
a', s' = Heap_top, 0 -- na konci tabulky, proto použijeme
-- jako další, nejvyšší, objekt vrcholek
-- haldy
if a ≤ P < a' -- testování, jestli jsme našli tu
return P - s -- správnou dvojici
else -- jestli ne, hledání pokračuje se dál
if P < a
r = m - 1
else
l = m + 1
return nil -- nová adresa nebyla nalezena
Druhou fází tohoto „stlačovacího“ algoritmu je přepočítání adres objektů. Je zde možnost, že se adresy ani přepočítávat nemusejí, pokud se s objektem nehýbalo, jinak se ale přepočítávají pomocí binárního hledání v tabulce. Je potřeba najít takové dvě dvojice jdoucí za sebou (a, s) a (a', s'), pro které platí nerovnost a ≤ P < a'. Nová adresa pak odpovídá P – s.
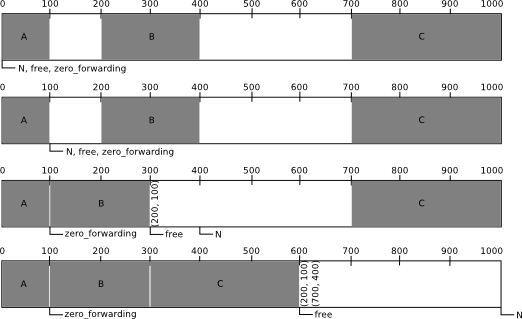
Mark & compact je algoritmus na pomezí mezi mark & sweep a kopírovacími algoritmy. Oproti mark & sweep má výhodu, že nevznikají díry a nemusí mít naalokováno dvakrát tolik, než je potřeba, což je případ kopírovacích collectorů. Ale na rozdíl od kopírovacích collectorů potřebuje mnohem delší čas na projití haldy – v první fázi musí označit živé objekty, v druhé je přesunout a ve třetí přepočítat adresy. Kopírovací collectory začnou od kořenů rovnou objekty procházet, zároveň je i kopírují a mění adresy.
Generační garbage collection
Doposud popsané tracing collectory využívaly vždy celou haldu (či alespoň celou paměť alokovanou collectorem) naráz, tudíž při každé „čistce“ mezi objekty musel collector projít všechny živé a buď je překopírovat do druhé části haldy (copying collector), či je označit a následně projít celou haldu a uvolnit mrtvé. Ovšem toto je velice neefektivní vzhledem ke skutečnosti, která byla zjištěna ve velké většině jazyků využívajících garbage collection – většina, a to znatelná, objektů „umírá“ mladá. Je to smutné, ale je to tak. V případě jazyků, které navíc všechna data alokují na haldě, toto může být ještě umocněno tím, že mezi nimi jsou i dočasné objekty.
Princip generací tedy spočívá v tom, že objekt, který vydrží určitou dobu (může se jednat o dobu relativní i absolutní) je přesunut do další generace. (Pozn. Doba života objektu se většinou neudává v sekundách a/nebo minutách, protože by to bylo vzhledem k rozličnosti a výkonnosti hardware dosti nesměrodatné, ale v množství nově alokovaného prostoru od alokace objektu.) Generací může být hodně a mohou být procházeny collectorem nezávisle na sobě, dokonce pro každou generaci může být použit jiný collector. Je logické, že generace mladších objektů jsou procházeny častěji než generace starších. Rozlišuje se mezi tzv. „minor“ a „major“ garbage collection. Minor je označení pro menší sběr v mladší generaci/cích a major tedy pro větší sběr starší generace, či celé haldy najednou.
Rozdělení haldy
Existují různé způsoby rozdělení haldy pro generační garbage collection. Pokud bychom brali, že jsou pro všechny generace použity kopírovací collectory, můžeme kupř. rozdělit haldu na stejně velké oblasti, kdy každá jedna oblast slouží jako jedna polovina pro kopírovací collector, přičemž by nám musela zůstat ještě jedna volná – kvůli kopírování. Při zaplnění nejmladší generace pak přesuneme všechny živé objekty na volné místo další generace.

Ale toto je jen jeden příklad uskupení haldy z mnoha. Velice pak záleží i na samotném programu, které rozložení pro něj bude lepší.
Určování kořenů generace
Stejně jako všechno, i generační garbage collection nemá pouze pozitiva – nemusí se stále hýbat se všemi objekty, či je neustále procházet – ale trpí i „neduhy“. Ty spočívají v mnohem těžším určení kořenů každé generace. Zatímco při použití jednoduchých algoritmů to bylo jasné – všechny hodnoty na zásobníku a v registrech – při více generacích se okruh referencí ze zásobníku a registrů musí zúžit pouze na reference mířící do generace, která nás zajímá. Navíc se zde mohou vyskytovat tzv. „mezigenerační“ ukazatele, které rozšiřují set kořenů generace, do které míří. V případě, že by tyto ukazatele nebyly brány v potaz, mohlo by dojít k uvolnění objektů, které jsou stále dosažitelné z kořenů přes jinou generaci.
U jazyků, kde jsou všechna data tzv. „immutable“ (tzn. jak jsou jednou data vytvořena, nelze je změnit) jako je tomu např. v Erlangu, či Haskellu, lze navíc dobře využít faktu, že objekty ze starších generací nemohou odkazovat na objekty z mladších. Zužuje se tím počet generací, ve kterých musíme zjišťovat mezigenerační ukazatele. Na objekty v nejmladší generaci, jejíž sběr je nejčastější, tedy kupř. nemůže ukazovat žádný objekt z generace jiné (existují pouze ukazatele mladší generace – starší a žádná generace mladší než nejmladší není), a proto stačí procházet ukazatele pouze na zásobníku a v registrech.
Large object area
Pokud potřebujeme prostředí, ve kterém se mohou vyskytovat různě objekty (což je obvyklé), vyvstává otázka, jestli by nebylo dobré taky různě zacházet s objekty podle velikosti, nejen podle „stáří“. A toto neplatí pouze pro generační garbage collection, ale i všeobecně. (Pozn.: Při využití „normálních“ algoritmů můžeme objekty podle velikosti rozhazovat do jiných částí haldy, i když vyvstává otázka, není-li to pak již také generační přístup?) Objekty jsou obvykle různé velikosti a taky plní různý účel. Mohou být měnitelné („mutable“), ale i neměnné („immutable“). Všechno toto se dá využít při alokování a manipulaci, a tudíž dalšího zefektivnění práce s nimi.
Large object area je, jak název napovídá, oblast, do které se umisťují velké objekty. V případě kopírovacího collectoru by neustálé hýbání s nimi mohlo zapříčinit znatelné prodloužení pauz. Do této oblasti se hodí např. dlouhé řetězce nebo bitmapy.
Inkrementální garbage collection
Zatímco u generační garbage collection jde o ušetření času omezením množiny procházených objektů, u inkrementálního přístupu se jedná o možnost procházení přerušit a následně na něj navázat později. (Pozn.: Ano, opět se bavíme pouze o tracing algoritmech.) Toto má za následek, že i tzv. „stop-the-world“ collectory mohou svou práci přerušit a nechat pokračovat ve vykonávání uživatelský kód.
Ovšem zde opět nastává problém – co dělat, pokud uživatelský program data mezi běhy garbage collectoru změnil? U většiny inkrementálních přístupů je využívána tzv. „tri-colour abstraction“ (tříbarevná abstrakce) – každý objekt má přiřazen jednu ze tří barev:
- Černá – práce garbage collectoru na objektu byla ukončena. Takový objekt již nepotřebuje být více navštíven.
- Šedá – objekt byl collectorem navštíven, ale ještě je potřeba ho navštívit znovu, buď z důvodu, že byl collector přerušen při práci na objektu a/nebo byl objekt změněn uživatelským programem. Pokud jsou na haldě ještě nějaké šedé objekty, nemůže se přistoupit k uvolňování.
- Bílá – objekt nebyl navštíven collectorem. Na konci tracing fáze jsou všechny všechny bílé objekty mrtvé – určené k uvolnění.
Jak je vidět, šedým se objekt může stát ve dvou případech. Druhý z nich – změna uživatelem – je trošku záludnější. Vyžaduje to totiž spolupráci mezi uživatelským programem a collectorem, kdy program musí při každé změně objektu dát collectoru vědět, aby objekt obarvil do šeda. Takový program se pak stává závislý na volání collectoru, a to nejen v případech, kdy potřebuje alokovat paměť. I když tady je celková režie menší než třeba u reference countingu – stačí pracovat pouze s měněnými objekty.
Taky je zde problém, pokud byly zničeny všechny reference na černě označený objekt. Jelikož se k němu z kořenů nelze nijak dostat, měl by být uvolněn. Na druhou stranu byl již označen černě, a collector tudíž nezajímá. Bohužel ale jde jen těžko zjistit, jestli takový objekt by měl být uvolněn, resp. my víme, že by teoreticky uvolněn být měl, ale pro collector je to těžké zjistit. Většina collectorů takové objekty nechává s tím, že budou určitě uvolněny při příštím běhu collectoru – nevedou na ně žádné reference, a proto určitě nemohou být dosaženy programem, či reference na ně přiřazeny do dalších objektů.
Následující díl
O různých dalších možnostech garbage collection by se toho dalo určitě napsat mnohem a mnohem více, ale to je již nad rámec tohoto článku. A kdo by se o toto téma chtěl zajímat podrobněji, své zdroje si jistě najde. A na co se těšit příště? Představíme si některé možnosti automatické správy pro jazyky C a C++ a podíváme se na některé konkrétní příklady použití garbage collection, čímž by tento miniseriál měl být zakončen.