

V závěrečném díle miniseriálu o garbage collection se něco dozvíme o možnostech použití garbage collectoru v jazycích, které jsou založeny na manuální správě paměti – v C a C++. Dále se podíváme, jak to vypadá v jazycích a běhových prostředích, kde je garbage collector vestavěný.
Garbage collection pro C
C ve smyslu jazyka bylo od začátku vyvíjeno a zamýšleno jako nástroj určený pro tzv. „low-levelové“ věci – tzn. psaní jádra operačního systému, ovladačů pro různá zařízení, systémových utilit aj. Jeho hlavním cílem bylo vystřídat assembler, který byl tehdy běžný, ale neumožňoval přenositelnost softwaru v něm napsaném mezi platformami (resp. mezi procesory s jinou instrukční sadou). Bylo tedy vyvinuto C, někdy přezdívané jako „přenositelný assembler“.
V počátcích nebylo počítáno, že by se jazyk mohl tak rozšířit (hlavně do jiných odvětví psaní aplikací – hlavně do psaní uživatelských aplikací). Ale stalo se tak, C si lidé oblíbili a oblíbené určitě ještě nějakou tu chvíli zůstane. Protože ale psaní uživatelských aplikací není tak úzce svázáno s hardwarem a systémem, věci jako úplná kontrola nad pamětí procesu nemusí být výhodou, tady jde spíše o to, jak paměť spravovat efektivně, správně uvolňovat apod. Řešení se nabízí – použít garbage collection. S tím se ovšem také nabízí otázka: „Jak?“
Prakticky máme na výběr ze dvou možností – zabudovat podporu přímo do jazyka, či napsat nějakou podpůrnou knihovnu. První případ by však znamenal nutnost ustanovit nějakou novou verzi standardu, či standard úplně nový, kterou/ý by pak musely implementovat kompilátory. Na druhou stranu, kompilátor ví všechno o strukturách, které by se alokovaly, a tak by umožňoval efektivnější práci s nimi. Ale zase je tu již hodně napsaného kódu, který využívá manuální správu paměti a který by po přepsání nemusel už nadále fungovat, či byl velice neefektivní. Taky se hodně lidí brání přijetí této změny do návrhu jazyka, protože manuální správu potřebují, nebo jim prostě vyhovuje.
Druhou cestou – formou knihovny – se někteří vydali. Ale opět zde nastává problém. A to především s nemožností určení strukturování paměti procesu. Knihovna sice může určit, jaké jsou rozsahy paměti pro jednotlivé oblasti (kde začíná a končí zásobník, halda apod.), ale již nemůže vědět, jaká data jsou kde a v jakém pořadí uložena. Paměť je pro knihovnu prostě sled jedniček a nul.
Boehm-Demers-Weiserův konzervativní collector
Konzervativní collectory je označení pro takové collectory, které nepotřebují žádnou spolupráci s kompilátorem, nepotřebují, aby byly struktury nějak označovány, ani se nepotřebují udržovat nějakou tabulku ukazatelů na objekty. Nejznámějším je asi Boehm-Demers-Wiserův collector (někdy též označovaný jen jako Boehmův). Ke kódu je připojován jako malá knihovna poskytující své rozhraní pomocí funkcí jako GC_malloc() pro alokování nové paměti, GC_realloc() pro změnu velikosti alokované paměti či GC_free() pro explicitní uvolňování objektů. Program používající tento collector vlastně operuje na dvou rozdílných haldách – jedné spravované manuálně a druhé spravované collectorem. Tento model umožňuje přidání collectoru do programu, jehož část je již napsána s manuální správou paměti, či potřebuje knihovny, které ji využívají.
Collector používá dvouúrovňový alokátor. Halda je rozdělena na bloky stejné velikosti. (Pozn.: velikost jednoho bloku je nastavitelná. Povětšinou se velikost stanovuje velikosti stejné, jako je velikost jedné stránky paměti. Na většině Unixů, ne však na všech, se tedy velikost stanovuje na 4 KB. Bloky se zarovnávají na stránky.) V každém bloku se pak alokují objekty stejné velikosti (i když se může jednat o objekty jiného typu). Tyto bloky jsou brány od nízkoúrovňového alokátoru (knihovního, systémového aj.). Po proběhnuvší garbage collection, kdy se objekty v blocích uvolní, mohou být objekty spojovány do větších, aby uspokojily potřeby nově alokovaných objektů. Objekty větší než polovina velikosti jednoho bloku jsou alokovány ve vlastních oblastech bloků.
Boehm-Demers-Weiserův collector využívá mark & sweep pro stanovování živosti a uvolňování objektů. Podporuje taky inkrementální a generační garbage collection. Konzervativní collectory obecně nemohou využívat jakýkoli druh algoritmu, který by s objekty manipuloval (kopírovací collector, mark & compact apod.). A to z prostého důvodu, který byl již popsán – collector nezná strukturu dat uložených v paměti, proto by ani nemohl změnit případné ukazatele na přesunutý objekt. Tento konzervativní collector tedy v první fázi („mark-phase“) přidá všechny kořeny na zásobník a následně prochází celý zásobník a zjišťuje, jestli je nějaký objekt na haldě spravované collectorem referencován. Problém je, že na zásobníku se neukládají pouze ukazatele, navíc tam mohou být různě velké objekty různě zarovnané. Předpokládaný ukazatel tedy musí projít řadou testů, aby byl shledán pravým ukazatelem na alokovaný objekt:
- Nejzákladnější předpoklad pro to, aby se jednalo o ukazatel do haldy spravované collectorem je to, aby adresa, kterou drží, byla v rozsahu počátku a konce collectorem spravované haldy.
- Když potencionální ukazatel prvním testem projde, nastává další test, a to, jestli ukazatel míří do bloku, kde se nějaký živý objekt vyskytuje.
- Jelikož každý blok obsahuje pouze objekty určité velikosti, které jsou samozřejmě alokovány postupně za sebou, třetí test spočívá v ověření, jestli je adresa ukazatele možnou adresou objektu vzhledem k počáteční adrese bloku a velikosti objektů, které jsou v bloku alokovány.
Pokud potencionální ukazatel projde všemi třemi testy, je shledán pravým ukazatelem na objekt, na který míří, a je označen. Pak samozřejmě probíhá podobným způsobem procházení označených objektů na reference vedoucí z nich. Ovšem ne každý objekt na haldě musí obsahovat ukazatele na jiné objekty, proto pro zvýšení efektivity collectoru a neplýtvání procesorového času na procházení objektů, které reference neobsahují, collector taky obsahuje alokační funkci GC_malloc_atomic(), která objekt naalokuje a označí ho jako atomický (nedělitelný), takže ho collector v mark-phase pouze označí, ale nebude procházet a hledat v něm ukazatele.
Samozřejmě, že takovéto určování referencí na objekt není vůbec přesné a collector nemusí určit množinu kořenů („root set“) ani reference uvnitř objektů správně. A proto mohou být označeny za živé i objekty, které jsou vlastně mrtvé.
Studie, kde byly porovnávány různé explicitní způsoby správy paměti a Boehm-Demers-Weiserův collector, ukazují, že celkový čas běhu tohoto collectoru byl okolo 20 % nad časem běhu toho nejlepšího alokátoru v testu, což je docela hezký výsledek. V některých případech však může collector době běhu programů velice uškodit, kdy byl zaznamenán až o 57 % delší čas běhu collectoru. Co se týče paměti zabrané collectorem pro jeho vnitřní struktury, tak ta se vyšplhala v některých případech až na trojnásobek paměti zabrané tím nejlepším explicitním alokátorem. Ovšem toto se týkalo velice malých hald. Boehm-Demers-Weiserův collector holt vždycky potřebuje nějaký minimální prostor na udržení dat potřebných pro kolekci.
Mostly copying collector
Dalším collectorem použitelným pro automatickou správu paměti v C je Mostly copying collector napsaný Bartlettem. Jedná se o hybrid mezi konzervativním a kopírovacím collectorem. Zatímco Boehm-Demers-Weiserův collector nezná informace o žádné struktuře objektů v paměti, Mostly copying collector potřebuje znát strukturu dat uložených na jím spravované haldě.
Halda je opět, podobně jako u předchozího collectoru, rozdělena na bloky a ne jen na dvě části, jak je tomu u „klasického“ kopírovacího colletoru. Každý blok je označen malým číslem, které říká o jaký druh bloku se jedná. Toto má za následek, že objekty mohou být z Fromspace do Tospace přesouvány dvěma způsoby – zaprvé samotným zkopírováním objektu a zadruhé změněním hlavičky bloku, která ho přidělí do té které částí haldy.
Mostly copying collector byl napsán hlavně pro Bartlettův kompilátor Scheme-to-C. Nejsou známy, alespoň mně, žádné studie srovnávající tento collector s Boehm-Demers-Weiserovým nebo s manuální správou paměti. (Pozn.: Pokud byste něco takového našli, určitě se podělte v diskusi pod článkem.)
Garbage collection pro C++
Ještě více než u C se diskutovalo o zavedení garbage collection nativně do C++. Ovšem zase zde je problém s tím, že hodně knihoven je již napsáno s tím, že využívají manuální správu paměti, a kdyby se zavedla tato změna do jazyka, to by se zase nelíbilo dodavatelům kompilátorů. Správa paměti v C++ je taky o něco komplikovanější. A to právě kvůli objektům.
U každého objektu nestačí jenom naalokovat paměť a poskytnout ji k užití. Objekty totiž při svém vytváření musí nejen získat paměť od alokátoru/collectoru, musí se také zinicializovat, o což se starají tzv. „konstruktory“. Konstruktor je, jak mnozí jistě ví, označení pro metodu, která se zavolá hned po alokování místa pro objekt a slouží k uvození základního stavu objektu. Pokud bychom brali v úvahu, že jsou objekty tzv. „immutable“ (neměnné), je to taky jediný způsob, jak vytvořit objekty stejné třídy s odlišnými daty. Ale konstruktory nejsou vše, oč se collector musí starat. Stejně jako se konstruktory pojí s inicializací objektu, tzv. „destruktory“ se vážou na jeho zničení – finalizaci objektu. Jsou to uklízecí metody, které mají na starosti zničení, popř. uzavření, všech zdrojů, které se o to nepostarají sami. A jelikož jen collector může vědět, když je objekt uvolňován, jedině on může tyto metody volat. V případě, že jsou objekty organizovány pomocí collectoru, nemůže uživatelský program vědět, kdy by se destruktory měly volat.
Boehm-Demers-Weiserův konzervativní collector toto umožňuje dvěma způsoby:
- pomocí
GC_register_finalizer(), - nebo zděděním třídy
gc_cleanup.
Mostly copying collector bohužel nenabízí žádné možnosti finalizace objektů. Další možností je použitelných tzv. „chytrých ukazatel“ (smart pointers), které pracují na principu reference countingu.
JVM a garbage collection
Java HotSpot virtual machine (nadále jen JVM) je jedním z příkladů běhových prostředí, které se chlubí svou automatickou správou paměti. JVM je, jak již název napovídá, hlavně prostředím pro běh bytekódu Javy, ale jsou i kompilátory do javovského bytekódu pro jiné jazyky jako například Python, Ruby, Groovy, či jazyk Scala.
JVM od verze 5.0 update 6 poskytuje hned čtyři collectory. Všechny generační. Uspořádání haldy však vypadá u všech stejně:
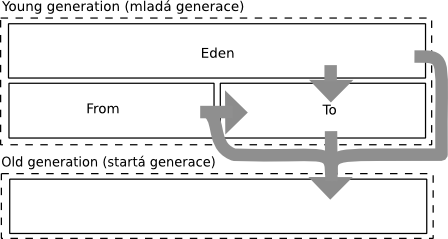
Do mladé generace tedy patří tři oblasti. První je nazývána Eden. Do té se umisťují nově alokované objekty. Jak bylo řečeno, generační garbage collection staví na faktu, že objekty umírají mladé. V Edenu tedy umírá nejvíce objektů a jeho sběr je nejčastější. Další dvě oblasti patřící do mladé generace jsou označované jako From a To. Z názvů je asi jasné, k čemu slouží – ano, jsou to dvě poloviny určené k použití kopírovacího collectoru. Stará generace se nijak více nečlení. Jak je vidět, JVM využívá pouze dvě generace. (Pozn.: Toto je velice časté.)
Cesta objektu vypadá tak, jak je v obrázku naznačeno šipkami. Alokován je v Edenu, kde žije do té doby, než proběhne sběr mladé generace. (Pozn.: V případě opravdu velkých objektů, jejichž neustálé přesouvání by nebylo příliš efektivní, se může JVM rozhodnou je alokovat přímo ve staré generaci.) V tomto sběru se živé objekty z Edenu postupně dostávají do části označené jako To. Za nepříznivých podmínek (malá úmrtnost Edenu) se tam nemusí všechny vejít, proto mohou být i nějaké objekty postoupeny rovnou do generace staré. Z části From se dále také živé objekty přesouvají do To. A stejně jako u Edenu je tu možnost, že by se tam nemusely všechny vecpat, proto mohou být ty přebývající přesunuty do starší generace. Úlohy From a To se, jak je u kopírovacího collectoru obvyklé, po sběru promění – z From se stává To a obráceně. Takto to probíhá do té doby, než se zaplní stará generace, pak proběhne tzv. „major collection“ celé haldy naráz. O starou generaci se stará mark & compact collector.
Předchozí popis se týkal jednoho používaného algoritmu pro garbage collection v JVM. U tohoto algoritmu probíhá všechno v režimu „stop-the-world“, je tedy označován jako „Serial collector“. Další dva algoritmy používané pro označování a uvolňování objektů používají paralelní zpracování pro jednu, nebo druhou generaci. První z nich označovaný jako „Parallel collector“ používá více vláken pro mladší generaci, druhý – „Parallel compacting collector“ – více vláken pro označování starší generace, kdy se pak všechny seběhnou do jednoho na „compact-phase“.
Posledním (čtvrtým) algoritmem, lépe řečeno typem práce s generacemi, používaným v JVM je „Concurret mark-sweep collector“. Pro mladou generaci používá stejný sběr jako Parallel collector, pro starší generaci pak mark & sweep, taky v konkurenčním podání. S objekty ve starší generaci se nehýbe, ale ty mrtvé jsou ukládány na „free-list“. Samozřejmě, že tedy může ve starší generaci docházet k fragmentaci, jak je tomu u „klasického“ mark & sweepu.
Další jazyky a prostředí
Kromě JVM je dalším velice často používaným běhovým prostředím „.NETí“ CLR (Common Language Runtime). Popis jeho práce s objekty zde na programujte.com již je. Proto pouze odkazuji na třetí díl seriálu Architektura Microsoft .NET Framework, kde ho můžete najít. Pokud jsem se nepřehlédl, v článku není zmíněno, jaký typ collectoru je vlastně používán, ale podle popisu jeho vlastností každý jistě usoudí, že se jedná o nějaký typ přesouvajícího collectoru – kopírovací collector, nebo mark & compact. Možná se může jednat i o generační collector. Proto může někdo, kdo do toho více vidí, tuto informaci doplnit v komentářích.
A další jazyky? Třeba ty zvané jako „dynamické“? Když vezmeme v úvahu ty začínající na P – Perl, PHP, Python –, ty používají refence counting. PHP používá úplně jednoduchý, nemá ani detekci cyklů, proto je v něm práce s nimi docela problém. Možná v nějaké příští verzi. Perl a Python používají pro odstranění potíží s cykly slabé a silné reference. U Perlu však je potřeba reference manuálně oslabit.
Další jazyk řadící se mezi ty dynamické je Ruby (bavíme se teď o jeho implementaci od jeho autora Yukihira Matsumota – tzv. „Matz Ruby“). Ten se již vydal cestou tracing algoritmů a zvolil mark & sweep. Podobný přístup zvolil i „extension extendable“ (jak se píše na jeho stránkách) jazyk Lua. Používá inkrementální mark & sweep – píší o „tri-colour incremental mark & sweep“ garbage collectoru.
Dokončení miniseriálu
Tento díl by měl být zakončením miniseriálu o garbage collection. V prvním díle jsme se dozvěděli o tom, co garbage collection je, o jejích výhodách a nevýhodách. V dalších dvou dílech byly popsány nejdříve ty základní algoritmy a poté i ty složitější [ http://programujte.com/index.php?akce=clanek&cl=2008070400-pokrocile-techniky-garbage-collection ]. Nakonec jsme se v tomto díle seznámili s možnostmi collectorů v jazycích a běhových prostředích. Pokud víte o nějakém dalším jazyku využívajícím garbage collection, podělte se v diskusi pod článkem. Ta je stejně tak otevřena pro jiné návrhy, dotazy a připomínky.
Zdroje
- Richard Jones: Garbage Collection Algorithms For Automatic Dynamic Memory Management.
- Memory Management in the Java HotSpot(TM) Virtual Machine [ http://java.sun.com/j2se/reference/whitepapers/memorymanagement_whitepaper.pdf ]
- Boehm-Demers-Weiserův collector [ http://www.hpl.hp.com/personal/Hans_Boehm/gc/ ]
- The evolution of Lua [ http://www.tecgraf.puc-rio.br/~lhf/ftp/doc/hopl.pdf ]
- domovské stránky jazyků, o kterých se zde psalo, a další…