

Pokračování seriálu Umělá inteligence, v tomto díle o perceptronech a jejich učícím algoritmu.
Perceptron
Perceptron sestává z jediného výkonného prvku modelovaného obvykle McCullochovým a Pittsovým modelem neuronu, který má nastavitelné váhové koeficienty a nastavitelný práh. Někteří autoři označují stejným názvem i celou síť takových prvků. Algoritmus vhodný k nastavení parametrů perceptronu publikoval poprvé F. Rosenblatt v roce 1958 a později v roce 1962. Rosenblatt dokázal následující větu:
Máme-li v n-rozměrném prostoru lineárně separabilní třídy objektů, pak lze v konečném počtu kroků učení (iterací optimalizačního algoritmu) nalézt vektor vah W perceptronu, který oddělí jednotlivé třídy bez ohledu na počáteční hodnotu těchto vah.
Preceptron s jedním výkonným prvkem umožňuje ovšem nanejvýše klasifikaci do dvou tříd. Zvětšíme-li však počet výkonných prvků pracujících v perceptronu a zvětšíme-li i počet jeho vrstev, je možno jím klasifikovat do více tříd. Tyto třídy již nemusí být lineárně separabilní, musí však být separabilní.
Perceptronová síť vychází z fyziologického vzoru a je taktéž třívrstvá.

Topologie a funkce
Vstupní vrstva v tomto případě funguje jako vrstva tzv. "vyrovnávací" či jinak řečeno rozvětvovací. Úkolem této vrstvy je rozdělit vstupní vektor, většinou dvourozměrný do jednorozměrného. Součástí perceptronu jsou taktéž váhy, jako u ostatních dále zmíněných sítí, a jeho váhy jsou pevně připojené a jsou tedy konstantní. Druhou vrstvu tvoří tzv. detektory příznaků. Každý z neuronů je náhodně spojen s prvky vstupní vrstvy. A nakonec poslední, třetí vrstva je nejdůležitější na celé perceptronové síti. Obsahuje "rozpoznávače" vzorů (pattern recognizer, neboli perceptrons). Změnou oproti dvěma zmíněným vrstvám je to, že její váhy nejsou nastaveny pevně, ale při procesu trénování či učení jsou nastavovány.
K jejich učení navrhl F. Rosenblatt tzv. perceptronovský učicí algoritmus. Přenosová funkce je skoková. Jelikož je funkce v podstatě transformací vstupního obrazu na výstup, je definována následujícím způsobem: nechť {x1, ... , Xn} 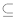 Rn což je skutečná reálná množina proměnných z Rn. Dále máme stanovenu množinu funkcí definovaných na členech zmíněné množiny Rn. Pokud nalezneme množinu takových koeficientů, že platí rovnice 2.8, pak je tato rovnice skoková.
Rn což je skutečná reálná množina proměnných z Rn. Dále máme stanovenu množinu funkcí definovaných na členech zmíněné množiny Rn. Pokud nalezneme množinu takových koeficientů, že platí rovnice 2.8, pak je tato rovnice skoková.

Tato funkce, jak lze vidět v rovnici 2.8., je realizována neuronem od McCullocha-Pittse s M vstupy a vhodně zvolenými vahami. Neurony ve vrstvě, která je schopná se naučit, mají zpravidla ještě jeden výstup navíc, jehož hodnota je konstantně nastavena na -1. Když si vzpomeneme na definici neuronové sítě, pak zjistíme, že při N vstupech má vlastní vstupní vektor perceptronu tvar rov. 2.9:
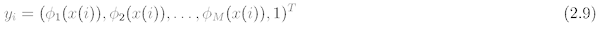
Jakmile se příslušné prahy položí rovny 0, provedeme úpravu perceptronu, která se používá při demonstracích učení perceptronu. Jelikož výstupní neuron perceptronu může nabývat pouze dvou hodnot, lze vstupní vektory-vzory přiřadit pouze do dvou tříd. Úprava bývá ve většině literatur označována jako "nastavený rozšířený vektor" a spočívá v tom, že vektory dané třídy bývají násobeny hodnotou -1.
Jelikož potřebujeme kvůli učení nastavovat nové váhy a prahy, existují pro perceptron následující metody učení:
- Metoda koeficientů - koeficient může být používán jako fixní či modifikovatelný. V případě modifikovatelnosti tohoto koeficientu pak mluvíme o tzv. absolutní či o zlomkové korekci.
- Gradientní metoda
Gradientní metoda
Gradientní metoda je metoda, která se používá pro nastavování vah v neuronové síti perceptronů. Využívá metodu největšího gradientu. Nastavování vah se potom děje pomocí následující rovnice:

kde c je konstanta zvaná gradient MSE chyby označovaná 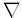 E.
E.
Výpočet vlastní (energetické) funkce je pak definován výrazem:
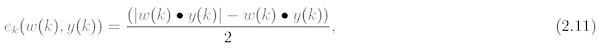
kde gradient této funkce je dán vztahem:
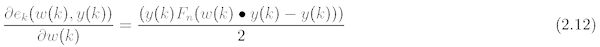
V posledním uváděném vztahu má význam Fn skokové funkce. Jestliže proto dosadíme rov. 2.12 do rov. 2.10, dostaneme výchozí rovnici pro výpočet a nastavování nových vah. Tato rovnice je tvaru:
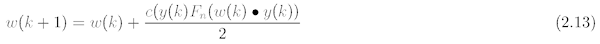
Podle této rovnice již můžeme velmi přesně nastavit váhy celé perceptronové sítě. Jednotlivé elementy při procesu učení se liší podle vrstvev umístěných v neuronové síti.
Jaký je rozdíl mezi jednotlivými elementy můžeme vypozorovat na obr. 2.11.
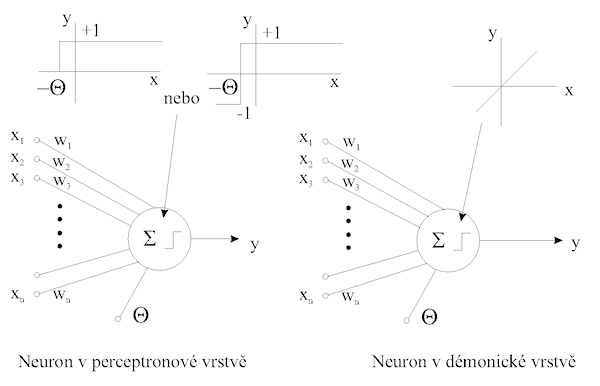
Obrázek 2.11: Typy neuronů v Rosenblattově neuronové síti
Fixní přírůstky
Při používání tohoto pravidla přepočtu nových vah se nové váhy modifikují podle následujících vztahů:
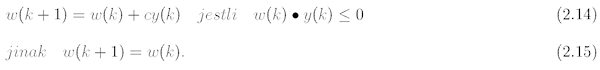
Koeficient c může nabývat hodnot celočíselných větších než 0.
Absolutní korekce
Podmínkou této korekce je následující výraz:
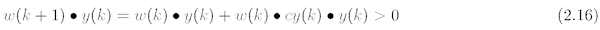
a konstanta c pak musí odpovídat výrazu:

Zlomková korekce
V případě, že pro aktualizaci vah chceme používat tyto korekce, pak bychom měli postupovat podle výrazu definovaného na následujícím řádku.
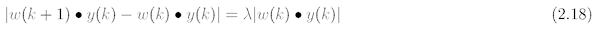
a z toho plyne výraz pro hodnotu c následující:

V tomto případě platí, že konvergencí algoritmu má být parametr lambda v intervalu 0 až 2.
Elementy v perceptronové vrstvě mají pouze jeden vstup (práh) připojený pevně ke konstantě 1. Ostatní vstupy jsou náhodně připojeny k výstupům démonů střední vrstvy a jejich váhy jsou nastavitelné. Jak vypadá přenosová charakteristika takového neuronu? Je následující: výstup je nulový za předpokladu, je-li vážený součet všech jeho vstupů nulový nebo záporný. V opačném případě je výstup roven jedné.
Učicí algoritmus perceptronu
- Váhy jsou nastaveny náhodně.
- Je-li výstup správný, váhy se nemění.
- Má-li být výstup roven 1, ale je 0, inkrementuj váhy na aktivních vstupech.
- Má-li být výstup roven 0, ale je 1, dekrementuj váhy na aktivních vstupech.
Aktivní vstupy máme přitom tehdy, je-li jejich hodnota na vstupech nad prahem nenulová. Velikost, s jakou se mění váhy (přesněji řečeno, kdy se inkrementují a kdy dekrementují), závisí na konkrétně zvolené variantě:
- Při inkrementaci i dekrementaci se aplikují pevné přírůstky.
- Přírůstky se mění v závislosti na velikosti chyby. Je výhodné, jsou-li při větši chybě větší a naopak. Takto zrychlená konvergence však může mít za následek nestabilitu učenÍ.
- Proměnné a konstanty se kombinují v závislosti na velikosti chyby.
Příště si popíšeme vlastní neuronovou síť zpětného šíření Back-propagation.