 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


Kolekce patří bezpochyby k jedné z nejpoužívanějších součástí .NETu, i přesto jejich možnosti nebývají využívány ani z poloviny a princip jejich fungování často zůstává zahalen tajemstvím. V tomto seriálu si ukážeme, jaké kolekce .NET nabízí, jak fungují a také doprogramujeme, co .NETu chybí.
První díl přináší nezbytný úvod do teorie a zároveň nám představí ty nejdůležitější rozhraní.
Úvod do seriálu
Ještě než se pustíme do samotného výkladu, řekneme si, co můžete od tohoto seriálu očekávat. V plánu je projít následující témata:
- Teorie
- Základní vlastnosti jazyka C# pro práci s kolekcemi
- Datové sturktury v .NET (seznamy, slovníky, stromy, apod.)
- Tvorba vlastních kolekcí
- Kolekce ve vícevláknovém prostředí
- Knihovny kolekcí mimo .NET
- Výkonnost
Většina dílů (především o datových strukturách) bude začínat teoretickým úvodem, z něhož přejdeme již na samotný .NET a výklad ukončíme praktickou ukázkou kódu. Mimo jiné si např. doprogramujeme některé abstraktní datové typy (viz níže), které v .NET chybí, nebo se podíváme, jak implementovat perfektní hashování apod.
Než se však dostaneme k samotným datovým strukturám a kolekcím .NET, musíme si říct něco málo o abstraktních datových typech a rozhraních, protože bez nich bychom se v dalších dílech neobešli.
Abstraktní datové typy
V teorii informatiky můžeme narazit na pojem abstraktní datový typ (ADT). ADT popisují pouze vnější chování objektu, nedefinují algoritmus fungování ani způsob uložení dat v paměti. Všechny ADT můžeme popsat pomocí matematických definic, v praxi však k definici ADT většinou používáme rozhraní. A proč se vlastně o ADT bavíme? Důvodem je, že pokud pomineme takové ADT, jako je řetězec nebo union (jistě znáte z Céčka), tak většinu z nich bychom mohli zařadit mezi kolekce:
- Seznam umožňuje duplicitní prvky. V .NET je reprezentován rozhraním IList<T> a ICollection.
- Kruhový seznam je specifickým typem seznamu s fixní velikostí. Po zaplnění všech míst začnou novější prvky nahrazovat ty starší.
- Množina. Každý prvek se v množině může vyskytovat pouze jednou. Rozhraní ISet<T>.
- Slovník / Mapa / Asociativní pole je kolekce, jejíž prvky nejsou indexovány pomocí číselného indexu ale pomocí klíče. Rozhraní IDictionary<T>.
- Zásobník (Stack) a Fronta (Queue). Tyto dva typy jistě představovat nemusíme. Fronta je kolekce typu FIFO (First In – First Out), zásobník naopak LIFO (Last In – First Out). V .NET pro tyto kolekce neexistuje žádné specifické rozhraní, obě však implementují IEnumerable<T> a ICollection.
- Prioritní fronta (Priority Queue). U prioritních front má každý prvek přiřazenu určitou prioritu. Minimální funkcionalitou takové kolekce pak musí být možnost přidání nového prvku a odebrání prvku s nejvyšší prioritou. V .NET prioritní frontu jako takovou přímo nenajdeme, můžeme však k tomuto účelu použít SortedDictionary<T>, což je binární vyhledávací strom. K implementaci prioritní fronty bychom mohli nalézt i efektivnější algoritmus např. halda.
- Bag / Multiset je v podstatě kříženec mezi množinou a seznamem. Umožňuje duplicitní prvky, na rozdíl od seznamu však zároveň uchovává informaci o počtu prvků jednotlivých duplicit.
- Strom (tree) je hierarchická struktura tvořená kořenem s dceřinými prvky (potomky), které dále mohou být rodičem pro další dceřiné uzly.
-
Graf je jednoduše řečeno množina vrcholů a hran. Oproti stromu obecně nemá žádný počátek/kořen. Strom můžeme považovat za specifický případ grafu.
Tabulka 1 ukazuje, která ADT bychom mohli v .NET nalézt a která rozhraní jim odpovídají.
| Rozhraní | Třídy | |
|---|---|---|
| Seznam | ICollection, IList | List, LinkedList, ... |
| Množina | ISet | HashSet, SortedSet |
| Slovník | IDictionary | Dictionary, StringDictionary, ListDictionary, ... |
| Prioritní fronta | - | Implementace pro prioritní frontu přímo neexistuje, je však možné použít SortedSet nebo SortedDictionary apod. |
| Fronta | - | Queue |
| Zásobník | - | Stack |
| Strom | - | Implementace pro strom přímo neexistuje, je možné použít LinkedList. Pro vyhledávácí stromy pak třeba SortedDictionary. |
Rozhraní
Jak jsme si již řekli, tak ADT bývají v programovacích jazycích reprezentovány pomocí rozhraní. V následujících několika řádcích se podrobněji podíváme na ty nejdůležitější z nich.
Z principu lze rozhraní rozdělit na generická a negenerická. Negenerická rozhraní již v současné době nejsou příliš používaná a hodně z nich spolu se svými implementacemi v .NET zůstává pouze kvůli zpětné kompatibilitě se staršími verzemi (např. IOrderedDictionary, Hashtable nebo ArrayList). Na obr. 1 můžete vidět strukturu negenerických rozhraní:
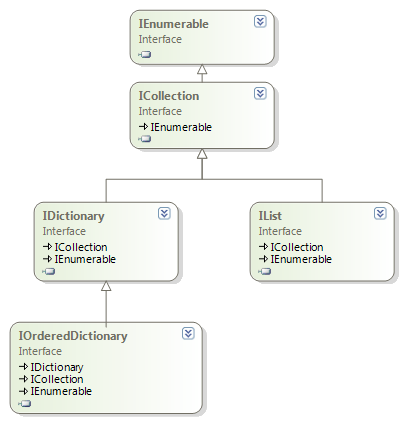
Na dalším obrázku je naopak o něco komplikoavnější struktura generických rozhraní:

Obecná rozhraní
IEnumerable a IEnumerable<T> jsou základní rozhraní, které implementují i ty nejjednodušší kolekce. Mají pouze jedinou metodu GetEnumerator, která vrací objekt Enumerator (Enumerator<T>). Jsou to právě tato rozhraní, která umožňují použití objektu v cyklu foreach.
IOrderedEnumerable<T> se v .NET nachází od verze 3.5 a obsahuje jedinou metodu CreateOrderedEnumerable:
IOrderedEnumerable<TElement> CreateOrderedEnumerable<TKey>(
Func<TElement, TKey> keySelector,
IComparer<TKey> comparer,
bool descending
)
Jak můžete vidět, návratovým typem této metody je opět rozhraní IOrderedEnumerable<T>. Takovým rozhraním se říká fluent interface.
Jediným účelem tohoto rozhraní je informovat o tom, že kolekce je již seřazena, ovšem neposkytuje žádnou informaci o tom, jakým způsobem. IOrderedEnumerable je hojně využíváno LINQem, vrací ho např. metoda OrderBy.
ICollection je oproti své generické verzi poměrně jednoduché. Obsahuje především property Count a také SyncRoot a IsSynchronized, které slouží pro práci s více vlákny. IsSynchronized nám oznamuje, zdali je kolekce bezpečná pro práci s více vlákny (thread-safe). SyncRoot využijeme jako synchronizační objekt. Singleton nad kolekcí by pak mohl vypadat následovně:
get
{
lock(kolekce.SyncRoot)
{
// tady budou operace s kolekci, ktere by nemusely byt
// vlaknove bezpecne. Jako je pruchod foreachem apod.
}
}
ICollection<T> umožňuje již celkem rozumnou manipulaci s prvky, má vlastnost Count a umožňuje vkládat a odebírat jednotlivé prvky. Má však také vlastnost IsReadOnly, která určuje, zdali lze prvky přidávat a odebírat. Z toho důvodu ICollection<T> působí poněkud schizofrenním dojmem. Proč by rozhraní mělo zároveň obsahovat metodu Add na přidání prvku a pak také property říkající, jestli to opravdu můžeme udělat? Je to zvláštní, ale je tomu opravdu tak. Celé tajemství tkví v tom, že třída nemusí implementovat rozhraní implicitně, nýbrž také explicitně. To znamená, že funkčnost daného rozhraní je přístupná, pouze pokud objekt přetypujeme přesně na toto rozhraní. Je to stejný důvod, proč na objektu typu List<T> deklarovaném takto:
List<T> list = new List<T>();
nenalezneme property IsReadOnly. Přetypujeme-li však proměnnou list na ICollection<T>, tak už ji nalezneme:
(ICollection<T>list).IsReadOnly;
Dalším podobným případem je např. třída ReadOnlyCollection<T>, která naopak skrývá metodu Add a Remove. Více o explicitní implementaci můžeme nalézt na MSDN.
Jedinou věcí, kterou bychom mohli ICollection<T> vytknout je, že neobsahuje operátor indexování. Je tomu proto, aby ICollection<T> mohlo být použito jak pro seznamy, tak i pro slovníky.
Kolekce pouze pro čtení
IReadOnlyList<T> a IReadOnlyDictionary<T> Jak je vidět, IsReadOnly property může přinést řadu komplikací často končících výjimkou InvalidOperationException, proto byla ve verzi 4.5 přidána tato dvě rozhraní sloužící k identifikaci kolekcí pouze pro čtení.
Seznam
IList poskytuje již hotový luxus pro práci, umí vracet index prvku metodou IndexOf, vkládat na konkrétní pozici - Insert, nebo z ní prvek smazat - RemoveAt. A také hlavně procházení kolekce pomocí indexu. Za povšimnutí stojí také property IsFixedSize, která nám říká, jestli kolekce má pevně danou velikost.
IList<T> je generickým odvarem IListu. Samotné rozhraní nemá tolik členů, protože většinu dědí již od ICollection<T>. Jediné, co generickému IListu<T> opravdu chybí, je property IsFixedSize.
Slovník
IDictionary a IDictionary<T> jsou rozhraní pro slovníky a obecně pro jakékoli kolekce, které obsahují pár klíč-hodnota. Mají dvě podkolekce Keys a Values, které lze procházet pomocí indexu. Obě rozhraní se liší v tom, že IDictionary<T> obsahuje navíc metodu TryGetValue, jež ověřuje, zdali je v kolekci patřičná hodnota.
Dalším rozdílem je metoda GetEnumerator. Zatímco negenerický slovník definuje vlastní metodu, která vrací rozhraní IDictionaryEnumerator, tak generický metodu GetEnumerator ji „přebírá“ od rozhraní ICollection<KeyValuePair<TKey, TValue>>, a vrací tudíž IEnumerator<T> stejně jako všechny ostatní kolekce.
IOrderedDictionary je jedním ze zapomenutých rozhraní, o čemž svědčí i to, že má v celém .NET jen jednu jedinou implementaci. Oproti IDictionary navíc umožňuje procházení pomocí číselného indexu jako IList.
Množina
ISet<T> se v .NET vyskytuje od verze 4.0, slouží pro práci s množinami, ve kterých je každý prvek jedinečný. Proto zahrnuje takové metody jako IsSubsetOf, IsSuperset, UnionWith atd. Dědí rozhraní ICollection<T>. Pokud se o tomto rozhraní chcete dozvědět víc, můžete se opět obrátit na MSDN.
Rozhraní stejně jako kolekce byly do .NET přidávány postupně. Tab. 2 shrnuje dostupnost výše jmenovaných rozhraní v jednotlivých verzích .NET frameworku:
| Rozhraní | Dostupný od verze |
|---|---|
| IEnumerable | 1.1 |
| IEnumerable<T> | 2.0 |
| IOrderedEnumerable<T> | 3.5 |
| ICollection | 1.1 |
| ICollection<T> | 2.0 |
| IList | 1.1 |
| IList<T> | 2.0 |
| IDictionary | 1.1 |
| IDictionary<T> | 2.0 |
| IOrderedDictionary | 2.0 |
| ISet<T> | 4.0 |
| IReadOnlyList<T> | 4.5 |
| IReadOnlyDictionary<T> | 4.5 |
Datové struktury a algoritmy
Datovou strukturu (dále jen DS) si lze představit jako implementaci ADT. U DS se již můžeme bavit o užitém algoritmu, reprezentaci dat v paměti i časové a paměťové složitosti. Mezi příklady datových struktur mohou patřit:
- Vázaný seznam,
- Halda,
- Binární vyhledávací strom,
- Hashovací tabulka atd.
Přehled základních datových struktur .NET a jejich vlastností je v následující tabulce:
| ADT |
Implementace Algoritmus |
Typ přístupu | Řazen | Rychlost vyhledávání |
Vložení prvku |
Smazání prvku | |
|---|---|---|---|---|---|---|---|
| List | Seznam | Pole | Index | NE |
Hodnota: O(n) Index: O(1) |
O(1) | O(n) |
| ListDictionary | Seznam | Jednosměrný vázaný seznam |
Klíč |
NE | Klíč: O(n) | O(1) | O(1) |
| LinkedList | Seznam | Dvousměrně vázaný seznam | - | NE | Klíč: O(n) | O(1) | O(1) |
| Dictionary | Slovník | Hashovací algoritmus | Klíč | NE | Klíč: O(1) | O(1) | O(1) |
| SortedDictionary | Slovník | Red-Black tree | Klíč | ANO | Klíč: O(log(n)) | O(log(n)) | O(log(n)) |
| SortedList | Slovník | Řazené pole |
Klíč Index |
ANO | Klíč: O(log(n)) | O(n) | O(n) |
| HashSet | Množina | Hashovací algoritmus | Klíč | NE |
Klíč: O(1) |
O(1) | O(1) |
| SortedSet | Množina | Red-Black tree | Klíč | ANO | Klíč: O(log(n)) | O(log(n)) | O(log(n)) |
Závěr
V tomto dílu seriálu jsme si řekli, co je to abstrakní datový typ, a seznámili se s nejběžnějšími rozhraními kolekcí. V příštím díle se podíváme, jak vůbec implementovat to nejjednodušší rozhraní IEnumerable, ukážeme si klíčové slovo yield a implementujeme několik iterátorů.



