 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu

") Stálý člen
Stálý člen")
")
Dobrý večer, všem přeji,
@gna mi vytvořil perfektní krátký RE. za který mu moc děkuji:
(.*?(;|$)){20}
Ten výraz dělá to, že z textu o struktuře CSV vezme prvních 20 prvků oddělených středníkem, zahodí konec.
Dalo by se to nějak upravit tak, aby to vzalo prvních 10 prvků z textu a posledních 10 textu? Tedy zahazovat střed namísto zahazování konce.
Výsledkem by byla zase strukture CSV, akorát by to zahodilo prvky uprostřed a prvních 10 prvků by se spojilo s těmi posledními 10 prvky.
Jelikož RE nerozumím, tak mě z mé lgiky napadlo něco takového (JE TO SAMOZŘEJMĚ NESMYSL):
(.*?(;|$)){10}((;|$).*?){10}
Mohl byste prosím někdo zkušenější to upravit, aby to fungovalo?
Slibuji, že pak dám už s RE pokoj. :-)
 Nahlásit jako SPAM
Nahlásit jako SPAM IP: 31.30.175.–
IP: 31.30.175.–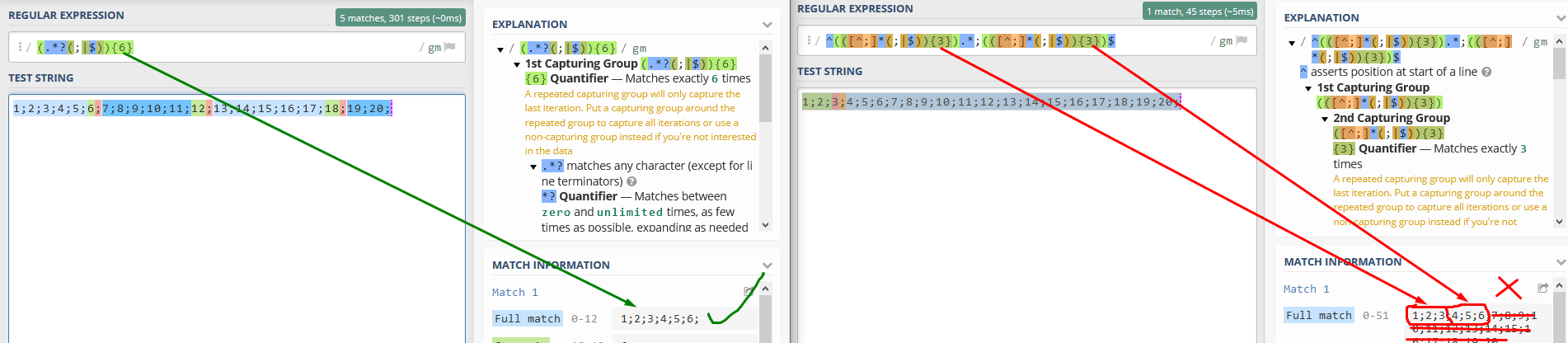


 Zjistit počet nových příspěvků
Zjistit počet nových příspěvků
































