 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu

") Grafoman
Grafoman")
")
Ještě pracuju na tom projektu co jsem psal. Mám nový problém. Zatímco Parser funguje správně a třída Transpose funguje taky, tak jsem začal implementovat ukládání netransponovaných dat z parseru. Zkoušel jsem to dělat pomocí GPT a zavedl mě úplně totálně na zcestí, takže jsem teď v pasti a nevím jak z ní ven.
V té třídě s parserem přibyly dvě pole:
self.verb_array = [] # Sem se ukládají záznamy typu: ParserVerbInfo
self.verb_array_map = {} # mapování ke zjištění kde začíná index v poli načtených řádků v konkrétní tabulce v rámci parsovače
Pole pro mapování ignorujte, to teď není důležité. Veškeré podstatné data se mají ukládat do self.verb_array. Jeden element má reprezentovat jeden řádek tabulky a jsou tam všechny tabulky co jsou na stránce. Jedna tabulka odpovídá jedné konjugaci. Sloupce odpovídají časům. Řádky zájmenům, respektive těm slovesným tvarům pro dané zájmeno a čas v dané konjugaci. Má se tedy uložit struktura dat o daném řádku. Toto je jak mi to navrhl GPT:
# ParserVerbInfo: Typ je určen ke sbírání dat a vypisování po řádcích a dle filtru.
# Pomocná třída, která umožňuje zjistit více informací o právě parsovaném řádku (slovu) a tvarech ve sloupcích netransponované tabulky
class ParserVerbInfo:
def __init__(self, table_name_index=0, columns_included=[], kmen=[], koncovka=[], adverb=[], preceding=[], person=[], no_form=[]):
self.table_name_index = table_name_index # refer to self.table_names
self.columns_included = columns_included if columns_included is not None else [] # inicializace prázdného seznamu
self.kmen = kmen if kmen is not None else [] # inicializace prázdného seznamu
self.koncovka = koncovka if koncovka is not None else [] # inicializace prázdného seznamu
self.adverb = adverb if adverb is not None else [] # inicializace prázdného seznamu
self.preceding = preceding if preceding is not None else [] # inicializace prázdného seznamu
self.person = person if person is not None else [] # inicializace prázdného seznamu
self.no_form = no_form if no_form is not None else [] # inicializace prázdného seznamu
def add_row(self, columns, kmen, koncovka, adverb, preceding, person, no_form):
self.columns_included.append(columns) # přidá sloupec
self.kmen.append(kmen) # přidá kmen
self.koncovka.append(koncovka) # přidá koncovku
self.adverb.append(adverb) # přidá adverb
self.preceding.append(preceding) # přidá preceding text
self.person.append(person) # přidá osobu
self.no_form.append(no_form)
def __repr__(self):
return f"VerbInfo(table_name_index={self.table_name_index}, kmen={self.kmen}, koncovka={self.koncovka}, adverb={self.adverb}, preceding={self.preceding}, person={self.person}, no_form={self.no_form})"
Důležité je, že v každém sloupci mají být obvykle 4 až 5 časů, tedy v každém poli je ne víc jak pět forem pro dané zájmeno. Takže při výpisu si pak mohu vypsat zájmeno nebo koncovka:
self.verb_array[i].adverb[k]
print(f"{adv}{pre}{kmen}|{self.verb_array[i].koncovka[k]}")
Co se děje velmi velmi špatně, že
self.verb_array[i].adverb
self.verb_array[i].kmen
self.verb_array[i].koncovka
self.verb_array[i].preceding
mají asi 120 záznamů ... místo pouhých 4-5 tvarů pro daný řádek.
Já chápu jak se to děje, ale je to špatně - problém je na tomto řádku:
# Vložit řádek tabulky do pole:
self.verb_array.append(self.temp_parser_verb_info)
Celý kód pro vkládání záznamů vypadá takto:
if self.column_counter==1:
self.temp_parser_verb_info = ParserVerbInfo(table_name_index=0)
if self.column_counter<self.header_column_counter:
# print(self.column_counter, kmen, koncovka, self.adverbs[self.adverb_counter-1], preceding_string, self.person)
self.temp_parser_verb_info.add_row(
columns=self.column_counter, # nebo jiný index sloupce
kmen=kmen,
koncovka=koncovka,
adverb=self.adverbs[self.adverb_counter-1],
preceding=preceding_string,
person=self.person,
no_form=False # nebo jiná logika, podle potřeby
)
else:
# Vložit řádek tabulky do pole:
self.verb_array.append(self.temp_parser_verb_info)
if self.current_table_name not in self.verb_array_map: # Pokud se jedná o první záznam tabulky, přidáme mapování
self.verb_array_map[self.current_table_name] = len(self.verb_array) - 1 # Uložení indexu prvního záznamu tabulky
Funkce na zobrazování netransponovaných dat:
def show_conjunction(self, conjugation, print_adverbs=True):
if conjugation in self.verb_array_map:
start_index = self.verb_array_map[conjugation]
next_index = self.table_names_indexes[conjugation]+1
if next_index < len(self.table_names)-1:
next_key = self.table_names[next_index]
else:
next_key = None
if next_key:
# @TODO: Otestovat
end_index = self.verb_array_map[next_key]-1
else:
end_index = len(self.verb_array)-1
# Zvýšení efektivity čtení pomoci definovaného rozsahu smyčky:
for j in range(start_index, end_index):
i = start_index+j
for k, kmen in enumerate(self.verb_array[i].kmen):
if print_adverbs:
adv = f"{self.verb_array[i].adverb[k]} "
else:
adv = ""
if self.verb_array[i].preceding[k]:
pre = f"{self.verb_array[i].preceding[k]} "
else:
pre = ""
if self.verb_array[i].no_form[k]:
print(f"{adv}{pre}{kmen}")
else:
print(f"{adv}{pre}{kmen}|{self.verb_array[i].koncovka[k]}")
Implementace:
parser = VerbParser(sloveso, hledane_kmeny)
check_add_unique = False
parser.process_file(input_file)
sort = False
if check_add_unique:
parser.print_unique_koncovky(sort)
else:
parser.show_conjunction("Imperative")
Takže tento řádek,
self.verb_array.append(self.temp_parser_verb_info)
místo aby vkládal záznamy dolů pod sebe (každá nová struktura dat jako nový element v self.verb_array, tak se ty data přidávají na konec toho pole např. kmen, koncovy, preceding ... a v součtu to je cca 120 záznamů. To se opakuje asi 120x nebo kolikrát směrem dolů.
Takže já nevím jak to mám udělat aby to bylo slušné. Zjednoduším předhledně jak by to mohlo vypadat pro češtinu:
pole[0].adverb=["já","já","já","já"]
pole[0].kmen=["byl","býval","budu","byl"]
pole[0].nasledujici=["","jsem","","bych"] .. španělština nemá následující, ale předcházející text
pole[1].adverb=["ty","ty","ty","ty"]
pole[1].kmen=["byl","býval","budeš","byl"]
pole[1].nasledujici=["jsi","jsi","","bys"]
pole[2].adverb=["on","on","on","on"]
pole[2].kmen=["byl","býval","bude","byl"]
pole[2].nasledujici=["","","","by"]
u té španělštiny tedy je to jednodušší, ale takhle nějak by to mělo vypadat kdyby se to aplikovalo na češtinu.
Co to dělá aktuálně? Nasere všechny slova do jednoho pole asi takto: pole[0].adverb=["já","já","já","já", "ty", "ty", "ty", "ty" ...]
pole[1].adverb=["já","já","já","já", "ty", "ty", "ty", "ty" ...]
pole[2].adverb=["já","já","já","já", "ty", "ty", "ty", "ty" ...]
 Nahlásit jako SPAM
Nahlásit jako SPAM IP: 94.113.182.–
IP: 94.113.182.–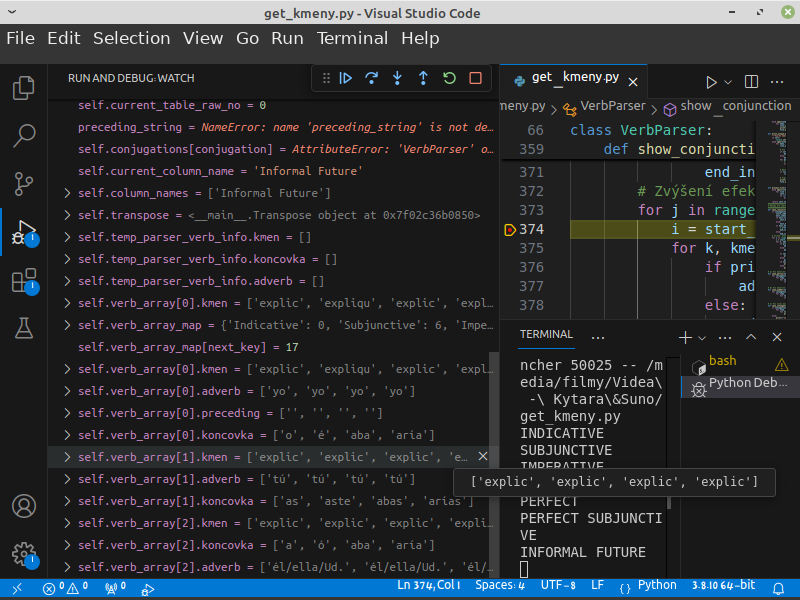
 Zjistit počet nových příspěvků
Zjistit počet nových příspěvků
































