 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu

")
")
Ahoj,
prosím o pomoc - potřeboval bych vymyslet s jednou funkcí v jazyku C. Jedná se v podstatě o algoritmus představující substituci.
Mám buffer, který má například tyto prvky: {S:aS S:a}
Já potřebuji provést substituci na {S:aA A:S A:@} (S se přepíše na A, tudíž v dalším řádku je A = S, v dalším řádku se A nemá na co přepsat, tak se tam dá symbol @)
Příklady substitucí:
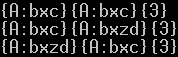
{A:bxc A:yc A:bxzd A:yzd} -> {A:bxB A:yC B:c B:zd C:c C:zd}
{A:aB A:aCB} -> {A:aX A:bBB X:B X:CB}
{X:a X:abCa C:c C:cBC} -> {X:aD D:@ D:bCa C:cF F:@ F:BC}
Co se týče písmenek, které mají nahradit původní, je na ně pouze požadavek, aby byla velká a nebyla stejná jako ty které už jsou použita.
Děkuji
 Nahlásit jako SPAM
Nahlásit jako SPAM IP: 147.228.209.–
IP: 147.228.209.–
 Zjistit počet nových příspěvků
Zjistit počet nových příspěvků































