 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


") Duch
Duch")
")
Zdravím kolegové programátoři.
Narazil jsem na velmi neobvyklý problém na který jsem nenašel na googlu odpověď. Používám ve svém programu čtečku čárového kódu která se chová jako klávesnice. Stačí jí tedy nastavit fokus do nějakého textového políčka (např. JTextField) a uživatel jen načte kód čtečkou,která je nastavena tak aby na konci posílala CR LF na což v dialogu reaguji. To je všechno v pohode a chodí to,ale problém je v tom,že ne úplně spolehlivě! Zcela náhodně se stává,že např. 20x je kód načten správně,ale pak se stane,že je vynechán znak na náhodné pozici a nebo je zaměněn za nějaký úplně jiný někdy i s vysokým UTF kódem např. vyžším než 8000 a nebo nějakým kolem 200 apod. Je to zcela náhodné a není při tom vyvolána žádná vyjímka. Chybu čtečky jsem zavrhnul,protože to za prvé dělá na více modelech a za druhé např. do poznámkového bloku mohu načíst kód třeba 200x a žádná chyba se nestane! Zajímavý poznatek je,že stejně náhodně je načtený kód komolen i když ho načítám do JAVA vývojového prostředí NetBeans. Řeším tento problém už několik týdnů a začínám z toho pomalu šílet. Potřebuji nutně aby bylo čtení 100% bez chyby. Nemá prosím někdo zkušenost s tímto zcela nepochopitelným problémem? Poraďte prosím.
Děkuji Tomáš Langer.
takto to například vypadá při testu čtení stejného kódu v NetBeans...
05013872
05013872
05013872
0501õ872
0½013872
н013872
05013872
05013872
0501k872
05013872
05013872
0501»872
05013872
05013872
05013872
05013872
05013872
ˆ5013872
05013872
05013872
05013872
0501387‚
05013872
05013872
 Nahlásit jako SPAM
Nahlásit jako SPAM IP: 89.190.73.–
IP: 89.190.73.–
") God of flame
God of flame

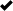 Nejlepší odpověď
Nejlepší odpověď
 Zjistit počet nových příspěvků
Zjistit počet nových příspěvků































