") Guru
Guru")
")
Ahoj,
mám projít vektor ukazatelů od druhého prvku vč. po konec vektoru (vynechat první prvek). Který postup byste zvolili - iterátor nebo index?
hu
 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu

Ahoj,
mám projít vektor ukazatelů od druhého prvku vč. po konec vektoru (vynechat první prvek). Který postup byste zvolili - iterátor nebo index?
hu
Edit: Sorry, jsem chtěl linknout celou tu stránku, na mobilu se blbě pracuje. :-D
#1 hlucheucho
Když mi nikdo, kdysi neuměl vysvětlit z jakého důvodu bych měl nahradit index iterátory (jde o běžné procházení indexovaného vektoru), tak jsem si udělal několik testů rychlosti, a z těch mi vyšlo jako rychlejší (rozdíl nebyl nijak závratný) způsob procházení vektoru indexem a navíc mě přijde lst[i] přehlednější, než iterator, tak pokud si mohu vybrat, jsem pro index. Jaký udělat jiný test, než test rychlosti mě nenapadá.
on je to vektor ukazatelů na struktury. Přístup k položce struktury pomocí iterátoru
(*it)->polozka;
působí to krkolomně stejně tak zápis cyklu. Zřejmě ty indexy budou vhodnější kvůli čitelnosti kódu.
hu
#8 hlucheucho
kdyby to nebylo od druhyho prvku, tak nejlip vypada range based loop:
for (Typ * ptr : pole) {
ptr->...
}
ale od druhyho, to aby clovek mel zase nejaky wrapper objekt, kterymu bys predhodil pole a on vratil spravnej begin a originalni end... jen bacha na prazdny pole.. by se to mohlo trosku zacyklit
hlavne se moc nepouziva iter <= end, protoze to pak neni obecny a spoleha to na to, ze jdou prvky po sobe (respektive to potrebuje random access iterator) - proste se pouziva !=
#10 hlucheucho
To už podle mě řešíš něco, co nemá vůbec smysl řešit, protože se dá vyřešit úplně jednoduchou podmínkou...
if (vektor.size() == 1)
{
//udělej toto, protože tam 2. prvek není
}
else
{
//jinak vektor prostě projeď
}#14 hlucheucho
ted nechapu odkud pocitas, jestli myslis index 0 jako nulty prvek, index 1 jako prvni.. Ja pocitam jako prvni prvek ten s indexem 0.
A begin ukazuje na prvni prvek, po pricteni 1 bude ukazovat na end, pokud je tam jen ten jeden prvek, nebo na druhy prvek, pokud jich je vicero.
Respektive:
0 polozek: begin == end
1 polozka: begin == end+1
myslel jsem, že end ukazuje na poslední prvek
hu
#16 hlucheucho
ukazuje za posledni prvek, nejsou tam uz platny data - je to velice univerzalni, neco jako \0 na konci retezce
nakonec by bylo lepsi pouzit treba:
std::for_each(pole.begin()+1,pole.end(), [](typ * ptr){ ptr->metoda(); } );
- cim min mist, kde se da udelat chyba, tim spolehlivejsi kod :)
samo s if (! pole.empty())
for_each je až od C++11? Myslím, že ano, takže nelze použít. Embarcadero implementovalo C++11 jen na půl :(, některé věci u 32-bitového překladače nejdou
hu
#21 hlucheucho
myslim ze ne, tyhle algoritmy byly pred c++11 .. jen bys nemohl pouzit tu lambdu (musel bys to mit nekde mimo)
Pořád se mi zdají ty indexy jednodušší a srozumitelnější
hu
#23 hlucheucho
jasny, je to o zvyku. Ty algoritmy jsou zase overeny - ono se totiz i pri prochazeni podle indexu da nadelat spousta chyb uz v kostre cyklu :)
Pak existujou i specialni iteratory pro std::copy ... napriklad pro cout - pak pomoci copy vypises vsechny prvky pole...
Back inserter iterator se zase navaze na vector a pomoci copy se tim da vkladat na konec..
Z examplu na tom cppreference.com:
#include <algorithm>
#include <iostream>
#include <vector>
#include <iterator>
#include <numeric>
int main()
{
std::vector<int> from_vector(10);
std::iota(from_vector.begin(), from_vector.end(), 0);
std::vector<int> to_vector;
std::copy(from_vector.begin(), from_vector.end(),
std::back_inserter(to_vector));
// or, alternatively,
// std::vector<int> to_vector(from_vector.size());
// std::copy(from_vector.begin(), from_vector.end(), to_vector.begin());
// either way is equivalent to
// std::vector<int> to_vector = from_vector;
std::cout << "to_vector contains: ";
std::copy(to_vector.begin(), to_vector.end(),
std::ostream_iterator<int>(std::cout, " "));
std::cout << '\n';
}
tady je z c++11 ta std::iota co to ma za ukol naplnit cislama od 0 do 9 :)
S tou lambda funkcí jsme to tady kdysi řešili a C++ Builder s tím měl problémy. Co jsem pak dělal pokusy s verzí XE5, byla pro mne zklamáním. Od té doby mám chuť přejít na MS VS.
S chybama u procházení vektoru pomocí indexů bych to neviděl až tak dramaticky. Mnohem větší riziko vidím u věcí, se kterými jsem neměl nikdy nic do činění.
hu
dělám i na jednočipech, z tohoto důvodu je mi C/C++ bližší. Změna IDE mne asi bude stát hodně času než se naučím jiný framework (znalost vcl mi asi moc nepomůže) a pak přenositelnost kódu. Hodně věcí napsaných s použitím vcl bude asi nepoužitelných
hu
#28 hlucheucho
Ja pouzivam iterovanie pomocou indexov len ak potrebujem modifikovat vector pocas iterovania. Ak by som pouzil iteratory tak by to neskoncilo dobre :). Ak mas c++11 tak samozrejme vstavany foreach, ak mas c++14 tak std::for_each a polymorficke lambdy.
#30 hlucheucho
V poslednm case programujem D a robi sa v nom ovela lepsie ako v C++.
V tvojom pripade bude asi lpsie pouzit indexi, lebo rucne vypisovat typy iteratorov je strasna otrava (predpokladam ze builder nema auto z c++11)..
D?
Předpokládáš správně, nemá auto. (trochu mimo téma) a já taky ne, už více než rok.
hu
#32 hlucheucho
http://dlang.org/
Vypadá to zajímavě
hu
typedef je třeba používat s rozumem. Mít alias na kdejaký prd a nebo 20 aliasů pro totéž je spíš na nadělání zmatků.
Jsme se vzdálili od tématu :)
hu
Měl bych doplňující otázku:
Jakou funkci by jste použili? Nebo je to úplně jedno?
void Fc1()
{
//1. verze
for(int i=0; i<100000; i++)
{
v1.push_back(hodnota());
v2.push_back(hodnota());
}
}
//---------------------------------------------------------------------------
void Fc2()
{
//2. verze
for(int i=0; i<100000; i++)v1.push_back(hodnota());
for(int i=0; i<100000; i++)v2.push_back(hodnota());
}
//---------------------------------------------------------------------------#37 BDS
#include "stdafx.h"
#include <iostream>
#include <time.h>
#include <vector>
using std::cout;
using std::endl;
using std::cin;
int _tmain(int argc, _TCHAR* argv[])
{
int hodnota = 10;
std::vector<int> vektor1;
std::vector<int> vektor2;
cout << "V jednom for cyklu: " << endl;
for (size_t i = 0; i < 10; i++)
{
const clock_t begin_time = clock();
for (size_t i = 0; i < 5000000; i++)
{
vektor1.push_back(hodnota);
vektor2.push_back(hodnota);
}
cout << float(clock() - begin_time) / CLOCKS_PER_SEC;
cout << endl;
vektor1.clear();
vektor2.clear();
}
cout << endl;
cout << "Ve dvou for cyklech " << endl;
for (size_t i = 0; i < 10; i++)
{
const clock_t begin_time = clock();
for (size_t i = 0; i < 5000000; i++)
{
vektor1.push_back(hodnota);
}
for (size_t i = 0; i < 5000000; i++)
{
vektor2.push_back(hodnota);
}
cout << float(clock() - begin_time) / CLOCKS_PER_SEC;
cout << endl;
vektor1.clear();
vektor2.clear();
}
return 0;
}
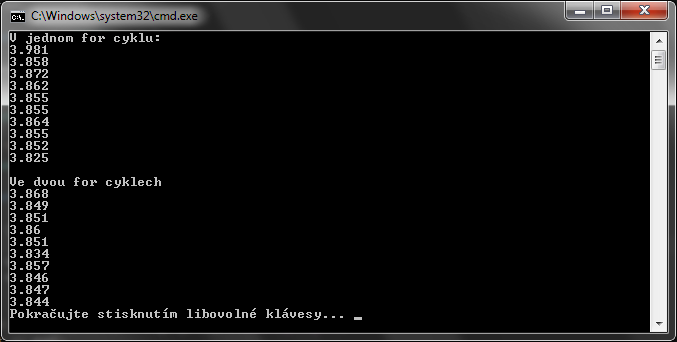
Verze 1 s jedním cyklem. V souladu s Application Note od Atmelu, měla v názvu efektivní C kódování, je dobré se vyhnout nadbytečným iteracím cyklu. Ono to na jednočipu je víc poznat, když plýtváš strojovým časem. Stejně tak se to vymstí u větších projektů na výkonnějším stroji.
hu
 Zjistit počet nových příspěvků
Zjistit počet nových příspěvků
Ano, opravdu chci reagovat → zobrazí formulář pro přidání příspěvku

































 Nahlásit jako SPAM
Nahlásit jako SPAM IP: 2001:67c:1222:800:e478:81...–
IP: 2001:67c:1222:800:e478:81...–") Věrný člen
Věrný člen

") God of flame
God of flame

") Grafoman
Grafoman