 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
") Duch
Duch")
")
Ahoj. Vytvořil jsem dynamické pole objektů. Toto pole teď potřebuji zvětšit. Je to možné udělat tak, že vytvořím jiné (větší) pole a do něj pomocí for cyklu a přiřazení "nakopíruji" prvky původního pole? Dočetl jsem se, že by to mělo jít udělat pomocí vektoru, ale tak daleko s výukou jěště nejsme proto ho nemohu použít. Jsem začátečník a jsem už z toho zoufalý. Díky za odpověd.
Fórum › C / C++
C++ kopírování dyn. pole objektů
Toto vlákno bylo označeno za vyřešené.

 Nahlásit jako SPAM
Nahlásit jako SPAM IP: 188.120.195.–
IP: 188.120.195.–") Stálý člen
Stálý člen
") God of flame
God of flame
Díky za rychlou reakci. Můžu vás jěště poprosit o kontrolu kódu, vždycky mi to na konci spadne. Puvodni pole jsem vytvořil úplně stejně jako zvětšené pole.
case 1:
{ pole[pocet-1].nastavOsoba (jmeno,prijmeni,funkce);
pole[pocet-
].nastavHodnoceni(vzhled,vystupovani,komunikace,tv); // zapis do puvodniho pole
Zamestnanec *pomocnePole = new Zamestnanec[pocet]; //alokace druheho pole
for (int k=0;k<pocet;k++)
{
pomocnePole[k]=pole[k]; //kopirovani prvku
}
delete [] pole; //mazu puvodni pole
pocet+=1;
Zamestnanec *pole = new Zamestnanec[pocet]; //alokace o 1 zvetseneho pole
for (int m=0;m<pocet;m++)
{
pole[m]=pomocnePole[m];
}
delete [] pomocnePole; //mazu pomocne pole
}
system ("cls");
break;
Můžu vás jěště požádat o kontrolu kódu. Vždycky mi to nakonec spadne a nemůžu přijít na to proč.
tak napriklad:
Zamestnanec *pole = new Zamestnanec[pocet]; //alokace o 1 zvetseneho pole
Tady totiz PREDEFINUJES promennou pole, do ni alokujes pole a pak lusknutim prstu zapomenes, ze existovalo (presne na konci bloku)
to ze delas alokaci 2x je taky docela blbej napad, samej konstruktor, pak prepsani ..
") Věrný člen
Věrný člen#5 james2000
Ne ideální, ale lepší řešení by spíš vypadalo nějak takhle:
#include <string>
#include <iostream>
//testovaci struktura Zamestnanec
struct Zamestnanec
{
std::string m_jmeno;
std::string m_prijmeni;
double m_vek;
Zamestnanec() {}
Zamestnanec(const std::string &jmeno, const std::string &prijmeni, double vek)
: m_jmeno(jmeno), m_prijmeni(prijmeni), m_vek(vek) {}
};
/* Deklarace globální proměnných
* __kapacita: označuje aktuální kapacitu pole (koli můžeš
* uchovat zaměstnanců
* __prvniVolnyIndex: pomocný index pro usnadnění alokace většiho pole
* __poleZamestnancu: klasické dynamicky vytvářené pole zaměstnanců na free storu */
size_t __kapacita{ 4 };
unsigned int __prvniVolnyIndex{ 0 };
Zamestnanec *__poleZamestnancu{ new Zamestnanec[__kapacita] };
int _tmain(int argc, _TCHAR* argv[])
{
char volba[10];
std::cout << "Vytvorte zamestnance: ";
std::cin >> volba;
do {
switch (volba[0])
{
//case 1 tvorba zaměstnance
case '1':
{
//vytvoříme si zaměstnance
Zamestnanec *zam = new Zamestnanec("Jan", "Novak", 22);
//index nastavený mimo existující pole, je třeba provést realokaci
if (__prvniVolnyIndex == __kapacita)
{
Zamestnanec *pomocnePole = new Zamestnanec[__kapacita * 2];
for (size_t i = 0; i < __kapacita; i++)
{
pomocnePole[i] = __poleZamestnancu[i];
}
//původní pole už nepotřebujem
delete[] __poleZamestnancu;
__poleZamestnancu = pomocnePole;
__poleZamestnancu[__prvniVolnyIndex] = *zam;
__prvniVolnyIndex++;
__kapacita *= 2;
}
//v poli je ještě místo
else
{
__poleZamestnancu[__prvniVolnyIndex] = *zam;
__prvniVolnyIndex++;
}
break;
}
//defaultní
default: break;
}
system("CLS");
std::cout << "Vytvorte zamestnance: ";
std::cin >> volba;
} while (volba[0] != '0');
//delete pole na free storu k předejití memory leaku
delete[] __poleZamestnancu;
return 0;
}
Je lepší provádět alokaci vždycky 2x větší. Proč? Ze začátku to bude celkem blbý, se ti to bude alokovat docela často, ale čím více prvků v poli budeš mít, tím méně často bude ke zvětšování pole docházet (například když budeš mít 32 zaměstnanců a přidáš dalšího, pole se zvětší na 64, a pak se dalších 32 zaměstnanců zvětšovat nemusí (nemusíš zbytečně spouštět for cyklus pro každé zvětšení - šetření času)).
Pochopitelně kód má svý mouchy, například používání raw pointerů ke správně paměti na free storu, fuj, musíš si hlídat dealokaci, ale to budeš muset nějak přežít.
#7 ondrej39
V kódu mám docela závažnou chybu, ačkoli jsme se snažil memory leaku předejít, tak k němu došlo, protože jsem hloupej.
Není třeba vytvářet konkrétního zaměstnance na free storu, protože dané pole je pouze pole objektů Zamestnanec, nikoli pole ukazatelů na objekt Zamestnanec, takže namísto
Zamestnanec *zam = new Zamestnanec("Jan", "Novak", 22);
můžeš zaměstnance normálně vytvořit pomocí
Zamestnanec zam("Jan", "Novak", 22);
potom je třeba upravit přiřazení do pole tak, že odstraníš dereferenční operátor, protože již do pole nepřiřazuješ hodnotu pointeru, ale samotný objekt.
Pokud použiješ kód, kde používám new pro vytvoření nového zaměstnance, je třeba před příkazem break; v case '1' ještě zavolat delete zam;, takhle:
delete zam;
break;
Toto jsem já zapomněl zavolat, kvůli tomu k memory leaku došlo.
Ten kód není zrovna ukázkovej... Když už, tak aspoň takto
#include <iostream>
#include <string>
using namespace std;
class Zamestnanec {
string jmeno, prijmeni;
int vek;
public:
Zamestnanec() {}
Zamestnanec(const string & jmeno, const string & prijmeni, int vek)
: jmeno(jmeno), prijmeni(prijmeni), vek(vek) {}
friend ostream & operator<<(ostream & os, const Zamestnanec & zamestnanec) {
return os << zamestnanec.jmeno << ' '
<< zamestnanec.prijmeni << " ("
<< zamestnanec.vek << ')';
}
};
class Zamestnanci {
size_t pocet, velikost;
Zamestnanec * zamestnanci;
public:
Zamestnanci() : pocet(0), velikost(8), zamestnanci(new Zamestnanec[velikost]) {}
~Zamestnanci() { delete[] zamestnanci; }
size_t Pocet() const { return pocet; }
Zamestnanci & operator+=(const Zamestnanec & zamestnanec) {
if (pocet >= velikost) {
velikost *= 2;
Zamestnanec * pom = new Zamestnanec[velikost];
for(size_t i = 0; i < pocet; i++)
pom[i] = zamestnanci[i];
delete[] zamestnanci;
zamestnanci = pom;
}
zamestnanci[pocet++] = zamestnanec;
return *this;
}
friend ostream & operator<<(ostream & os, const Zamestnanci & zamestnanci) {
for (size_t i = 0; i < zamestnanci.pocet; i++)
os << zamestnanci.zamestnanci[i] << endl;
return os;
}
};
int main(void) {
Zamestnanci zamestnanci;
zamestnanci += Zamestnanec("Jan", "Novák", 27);
zamestnanci += Zamestnanec("Franta", "Vomáčka", 22);
cout << zamestnanci;
}
Ale pořád tam samozřejmě chybí tuna věcí...
No pořád se jedná o pole zaměstnanců s pomocnou proměnnou udávající jeho velikost a jeho aktuální naplněnost. Že je celý kód zabalený do třídy Zaměstnanci nic na principu dynamického zvětšování pole, tak jak jsem ho tam napsal, nemění.
Tak ona se v C++ už celkově manuální alokace paměti téměř nepoužívá...
No kazdopadne vector snad ani nepouziva new/delete ale malloc a free - vola konstruktory a destruktory primo (aby pri realokaci jen prekopiroval data a nedelaly se zbytecnosti. Coz "new Zamestnanec[1000]" a pak jeste kopirovani cyklem docela dela). No proste klasika
#18 KIIV
KIIVe, přece nemůžeš předpokládat, že já, člověk, kterej programuje asi 6 měsíců, udělám stejně dobrej algoritmus na zvětšování pole s dynamickou velikostí jako je uvedenej ve standardní knihovně :-D.
Jinak já si myslel, že mezi malloc a new jsou jen minimální rozdíly, s tím, že malloc je spíš přebytek z C a v C++ se pro alokaci převážně používá new. Malloc má lepší výkon?
#19 ondrej39
no jde o to, ze new zabere pamet a provede konstruktor. Delete zase provede destruktory. Malloc/free to samozrejme neumi - nicmene pro stl kontejnery je to vyhodnejsi, ty konstrukce a destrukce si poresi explicitne kdyz je to opravdu nutne (jako pridani, smazani prvku, pri zvetsovani se pak jen kopiruji data, ale nedela se konstruktor, kopie, destruktor starych hodnot - hlavne, pokud bys to mel blbe napsany a mels tam dynamicky data, jen melkou kopii, tak by se ti to sesypalo)
#19 ondrej39
new [] by měl být stejně výkonný jako malloc. Rozdíl se projeví až právě při realokaci paměti. Zatímco při zvětšování pole alokovaného s new [] musíš všechny prvky zkopírovat do nového pole a staré pak uvolnit, realloc se ti pokusí staré pole zachovat a jen ho protáhnout. Taková operace tě pak i s milionem prvků nestojí téměř žádný čas. Ale není to garantovaný. Někdy se realloc tomu kopírování taky nevyhne...
#20 KIIV
KIIVe, chápu to teda správně, že stl při zvětšení vezme chunk existujících dat a prostě je přesune do nově, dvojnásobně velkého pole, namísto aby je tam kopíroval, čímž by 1) na chvíli zabral 2násobek paměti a 2) zdržoval proces tvorbou a mazáním?
#22 ondrej39
tim si nejsem jist.. realloc zvetsi, kdyz ma kam, jinak musi presouvat a pak ti to chvili zabira starou i novou.. (a pravdepodobne ty bloky zustanou procesu i tak - ikdyz jsou prazdny a mozna je malloc/new jeste vyuzijou)
Pak jsou spojovy seznamy, stromy a tak, kde se dela alokace po prvcich a neni to pak v pameti zasebou. Tady se zase projevi pomalost alokace, jeden prvek zabira vic pameti, problemy s predvidanim cache procesoru u hodne dat, a tak dale.
#24 ondrej39
Těžko říct co bereš jako optimalizaci na vyšší programátorské úrovni. Realloc je dost standardní část Cčka a v C++ není jen z důvodu, že by prostě s konceptem tříd nemohl existovat. Jsou tam např. virtuální třídy, kde si kompilátor ukládá nějaký data i bokem mimo třídu a při takovémto přímém kopírování paměti by to na 100% nepřežili.
Já třeba zítra na VŠ skládám zkoušku z efektivních algoritmů. Musím umět během chvíle naimplementovat docela pokročilé datové struktury jako Red–black tree, Binomiální haldu, všechny možný řadící algoritmy, hashovací tabulky a spoustu dalších stromových struktur + určit složitost. To je pak psaní v Cčku docela oddychovka :-).
#26 PiranhaGreg
Algoritmy atd. už mám za sebou, řadící algoritmy také. Nicméně výhody realloc mi zatím nikdo nesdělil :-D.
Jinak tu zkoušku máš na 4 hodiny? Vždyť implementace negenerického RBT je v čitelném kódu na bezmála 1000 řádků a nejde ani o to, že je těch řádků docela hodně jako si ohlídat všechny případy, které při vkládání/mazání mohou nastat. Kde studuješ, vždyť to po vás nemohou chtít z píky napsat.
#28 ondrej39
tak to jeste trosku studuju a nakonec se malloc nepouziva v kontejnerech.. alokujou to pomoci new void* (aby vytvorili nealokovanou pamet) - proste se snazi o to, aby na tom miste, kde je prazdno, nedelali zbytecne alokaci. Inicializaci pak delaji pomoci placement new (new, ktery nealokuje pamet, ale umisti to na konkretni misto pameti a zavola konstruktor)
#27 ondrej39
ČVUT FIT, je to tu těžký no :D. Už mám poslední pokus :-/.
Nechtějí napsat celý kód. Třeba je v zadání ať naimplementuji pouze insert. A s těmi kombinacemi právě ještě dost bojuju. Ze stromových struktur tam může být AVL tree, RB tree, B-stromy, pak různý kombinace n-árních stromů, ty binomiální a Fibonacciho haldy, pak samozřejmě klasika BVS a využití haldy v heap sortu... a když má člověk u každýho umět insert, delete, atd. tak je to šíleně kombinací... asi to nedám :D.
Ale jsou tam i lehčí příklady, na kterých snad naženu co nejvíc bodů O:-).
#30 PiranhaGreg
Tak u insertu do rbt jsou stejně 4 situace, který mohou nastat, pokud si to dobře pamatuji, málo toho rozhodně není. Každopádně rbt je na implementaci skoro to nejobtížnější co bys mohl dostat, avl strom by se ještě zvládnout dal. Přeju zítra hodně štěstí.
#29 KIIV
jop, taky jsem na to před chvílí ze zvědavosti koukl. Každopádně bych nechtěl dělat na standardních knihovnách ani náhodou. Nedávno jsem třeba koukal na implementaci Cčkové funkce strlen. Člověk by čekal nějakej while na 2 řádky a prý teda ne...
http://www.stdlib.net/~colmmacc/strlen.c.html
#29 KIIV
KIIVe, bohužel vůbec nechápu, jak ten placement new funguje :D. Našel jsem tento kód, je to správná stránka, kde si o daném tématu něco přečíst?
Je mé chápání, to, co je v komentářích, správné?
//naincluduji si new knihovnu
#include <new>
struct Foo
{
int m_Bar;
Foo() {}
Foo(int bar) : m_Bar(bar) {}
~Foo() {}
};
int _tmain(int argc, _TCHAR* argv[])
{
//vytvořím si místo v paměti o velikosti jednoho Foo()
char pamet[sizeof(Foo)];
//na místě v paměti, které určitě bude velikostí vyhovovat, protože
//jsem ho vytvořil pomocí sizeof(Foo), zavolám konstruktor Foo(10)
//a tím si do daného místa dosadím strukturu Foo(10), na níž ukazuje Foo * f
Foo * f = new(pamet)Foo(10);
//manuální volání destruktoru
f->~Foo();
return 0;
}
Překvapilo mě, že mi kód fungoval, i když jsem naincludovanou knihovnu new neměl. Jak je to možné? Další, co mi vrtá hlavou, jak je možné, že pole char pamet vlastně alokuji na stacku a pak do daného místa přiřazuji Foo * f? To je normální?
A v neposlední řadě mě zajímá, jakým způsobem by se alokovalo místo v paměti například pro 10 Foo struktur, způsobem, že by velikost mohla být proměnná a nebyla dána konstantnou?
UPDATE: Našel jsem ještě další stránku, která víceméně osvětluje problém s alokací pole pro n počet Foo objektů pomocí
size_t n = 10;
//vytvořím si místo v paměti o velikosti jednoho Foo()
char * pamet = new char[n * sizeof(Foo)];
a rovněž zde probíhá alokace potřebného místa na free store namísto stacku, což je asi korektnější řešení, než v prvním případě, ne?
#34 ondrej39
Komentare sedi. Vic mista bys tam mohl nacpat napriklad pomoci char * pamet = new char[sizeof(Foo)*pocet];
A pak pouzit pro inicializaci prvniho: Foo * f = new(pamet) Foo(10);
pro inicializaci druheho bud maly ukrok stranou (v f uz pointer je i se spravnym typem):
Foo * test = new(f+1) Foo(11); // f+1 bude ukazovat na misto dalsiho prvku
nebo
Foo * test = new(pamet+sizeof(Foo)) Foo(11); // pamet je v charech, takze se musi pricist velikost Foo, v predchozim pripade se o to postaral prekladac a pointerova aritmetika
A zbytek je zatim neinicializovany... taky by melo jit neco jako Foo * vse = new(pamet) Foo[pocet]; (ale musi byt implicitni konstruktor. V c++11 standardu jde i Foo * vse = new(pamet) Foo[pocet]{1,2,3,...}
#35 KIIV
A jakým způsobem se tady nakonec vyhnu tomu volání konstruktorů, které new dělá, jak jsi zmiňoval v jednom z dřívějších příspěvků? Vždyť tady se volají konstruktory také, čemuž jsme se chtěli vyhnout, ne?
Nebo je to tak, že běžně například Foo * f = new Foo[n] hned v tomto kroku zavolá n-krát konstruktor objektu Foo, tedy zavolá se n-krát i kdybych potom v dalším kroku přidal do pole třeba jen 2 Foo objekty, namísto pomocí placement new metody se pouze alokuje prostor a konstruktor se volá teprve tehdy, až konkrétní objekty vytváříme, takže bych ho zavolal jen dvakrát namísto n-krát, čímž se ušetří počítačový výkon?
Konstruktory se volaji az pri tom placement new. Pripravis si pole o 1000prvcich a konstruktor zavolas, az kdyz ten prvek skutecne zabiras, ne hned pri te priprave 1000prvku
#38 ondrej39
on se zavola automaticky pokud existuje. A o to prave jde. Ty si pripravis pole o 1000prvcich, ale zatim si z nich zadny oficialne nezabral - s normalnim new uz je ta pamet predem pripravena, u vseho zavolany konstruktory. Jen proto, abys za chvili zacal pomoci assign operatoru ty jednotlivy objekty prepisovat. To mas hned dve zbytecny operace - inicializace a kopie. Ale pokud to delas placement operatorem, tak delas ten konstruktor se spravnejma datama rovnou. Zadny defaultni konstruktor prepsany kopirovacim operatorem.
#39 KIIV
A nevíš, jakým způsobem probíhá to kopírování (přesouvání?) prvků z jednoho menšího pole do toho 2násobně velkého? To se přece udělat také musí, ne? Nebo jak konkrétně to ve vectoru funguje? Těm klikyhákům ve vector knihovně vůbec nerozumím, šablony na 3 stránky a tak :-D.
U realloc to chápu, že se pokusí aktuální pole zvětšit a když nemá k dispozici dost velký blok paměti, tak se provede malloc/calloc jinde a do nového bloku se nakopírují (je to tak?) data z předchozího polovičního bloku, pomocí placement new lze dosáhnout něčeho podobného?
Tak uz si nejak nejsem moc jist... Cim vic hledam, jak je to implementovany, tim vic to vypada, jako ze je to uplne jinak :D
Stare standardy to kopirujou pomoci copy konstruktoru a nove pomoci move konstruktoru. Takze jedine objekt, ktery by vypisoval veskery akce a prohnat to vectorem - pak by se videlo, co se opravdu deje. Jestli se udela kopirovaci konstruktor a stary objekt se zlikviduje.
#41 KIIV
Zkoumám ty vektory a vypadá to, že když se vektor 2x zvětší, tak je opravdu třeba prostě projet vektor původní a jeho obsah nakopírovat do vektoru dvakrát tak velkého, což vede na lineární asymptotickou složitost. Že vektory opravdu nepodporují změnu velikosti pole jak je to v C pomocí realloc, kde se nejdříve zkusi vytvořit blok o dané velikosti a ten připlácnout na pole původní a malloc a kopírování na jiném bloku volat teprve poté, když tato operace udělat nejde (pokud to teda chápu správně).
Jediný způsob, jak předejít tomuto kopírování je právě pomocí vektor.reserve(), který kdosi nedávno zmínil v nějakém jiném tématu, kde si prostě naalokuješ (pouze naalokuješ) místo, které podle tebe budeš potřebovat, a poté už na každém indexu pomocí toho placement new explicitně voláš konstruktory, jak jsi psal původně.
#42 ondrej39
realloc dela to samy, taky veme to co ma a pokud se musi prestehovat, tak to za tebe zkopiruje. Takze te maximalne usetri toho kopirovani. Jen se nestara o objekty, protoze zadny nezna.
#43 KIIV
Takže to vypadá, že v C++ jiná možnost než to překopírovat nebo přesunout pomocí copy/move sémantiky není.
Pokud bych tedy kód, který jsem původně napsal, upravil, aby se pole netvořilo pomocí
Zamestnanec * pole = new Zamestnanec[n];
v němž se volá implicitní konstruktor n-krát, na kód, kde se pouze alokuje potřebné místo a konstruktory se volají až u konkrétních objektů, tak už asi moc dalšího prostoru pro optimalizace snad ani nebude. Že?
#46 ondrej39
s vectorem to neni takovy problem, ale ten to dela tou alokaci bez inicializace a konstruktor zavola az kdyz je treba.
Ale ted jsem zkousel, co se presne ve vectoru deje a u c++11 standardu pro ty presuny pouziva kopirovaci konstruktor (az kdyz sem ho zakomentoval, tak se pouzil move konstruktor... coz je hodne divny)
#include <iostream>
#include <vector>
using namespace std;
class Foo {
public:
Foo(): x(0) { cout << " Ctor(): " << this << " x="<< x << endl; }
Foo(int x_): x(x_) { cout << " Ctor(int): "<< this << " x="<< x << endl; }
//Foo(const Foo& b): x(b.x) { cout << " Ctor(const Foo&): "<< this << " b="<< &b <<" x="<< x << endl; }
Foo(Foo&& b): x(b.x) { b.x=0; cout << " Ctor(Foo&&): "<< this << " b="<< &b <<" x="<< x << endl; }
~Foo() { cout << " Dtor(): "<< this << " x="<< x << endl; }
protected:
int x;
};
int main() {
cout << "Create vector:\n";
vector<Foo> test;
cout << "Reserve 2\n";
test.reserve(2);
cout << "push back 1\n";
test.push_back(1);
cout << "push back 2\n";
test.push_back(2);
cout << "push back 3\n";
test.push_back(3);
cout << "push back 4\n";
test.push_back(Foo(4));
cout << "push back 5\n";
test.push_back(Foo(5));
cout << "push back 6\n";
test.push_back(Foo(6));
cout << "push back 7\n";
test.push_back(Foo(7));
cout << "push back 8\n";
test.push_back(Foo(8));
cout << "push back 9\n";
test.push_back(Foo(9));
cout << "push back 10\n";
test.push_back(Foo(10));
cout << "push back 11\n";
test.push_back(Foo(11));
cout << "push back 12\n";
test.push_back(Foo(12));
cout << "push back 13\n";
test.push_back(Foo(13));
cout << "End:\n";
}
S explicitnim copy konstruktorem:
Create vector:
Reserve 2
push back 1
Ctor(int): 0x7ffffdda1a40 x=1
Ctor(Foo&&): 0x239c010 b=0x7ffffdda1a40 x=1
Dtor(): 0x7ffffdda1a40 x=0
push back 2
Ctor(int): 0x7ffffdda1a50 x=2
Ctor(Foo&&): 0x239c014 b=0x7ffffdda1a50 x=2
Dtor(): 0x7ffffdda1a50 x=0
push back 3
Ctor(int): 0x7ffffdda1a60 x=3
Ctor(Foo&&): 0x239c038 b=0x7ffffdda1a60 x=3
Ctor(const Foo&): 0x239c030 b=0x239c010 x=1
Ctor(const Foo&): 0x239c034 b=0x239c014 x=2
Dtor(): 0x239c010 x=1
Dtor(): 0x239c014 x=2
Dtor(): 0x7ffffdda1a60 x=0
push back 4
Ctor(int): 0x7ffffdda1a70 x=4
Ctor(Foo&&): 0x239c03c b=0x7ffffdda1a70 x=4
Dtor(): 0x7ffffdda1a70 x=0
push back 5
Ctor(int): 0x7ffffdda1a80 x=5
Ctor(Foo&&): 0x239c060 b=0x7ffffdda1a80 x=5
Ctor(const Foo&): 0x239c050 b=0x239c030 x=1
Ctor(const Foo&): 0x239c054 b=0x239c034 x=2
Ctor(const Foo&): 0x239c058 b=0x239c038 x=3
Ctor(const Foo&): 0x239c05c b=0x239c03c x=4
Dtor(): 0x239c030 x=1
Dtor(): 0x239c034 x=2
Dtor(): 0x239c038 x=3
Dtor(): 0x239c03c x=4
Dtor(): 0x7ffffdda1a80 x=0
push back 6
Ctor(int): 0x7ffffdda1a90 x=6
Ctor(Foo&&): 0x239c064 b=0x7ffffdda1a90 x=6
Dtor(): 0x7ffffdda1a90 x=0
push back 7
Ctor(int): 0x7ffffdda1aa0 x=7
Ctor(Foo&&): 0x239c068 b=0x7ffffdda1aa0 x=7
Dtor(): 0x7ffffdda1aa0 x=0
push back 8
Ctor(int): 0x7ffffdda1ab0 x=8
Ctor(Foo&&): 0x239c06c b=0x7ffffdda1ab0 x=8
Dtor(): 0x7ffffdda1ab0 x=0
push back 9
Ctor(int): 0x7ffffdda1ac0 x=9
Ctor(Foo&&): 0x239c0a0 b=0x7ffffdda1ac0 x=9
Ctor(const Foo&): 0x239c080 b=0x239c050 x=1
Ctor(const Foo&): 0x239c084 b=0x239c054 x=2
Ctor(const Foo&): 0x239c088 b=0x239c058 x=3
Ctor(const Foo&): 0x239c08c b=0x239c05c x=4
Ctor(const Foo&): 0x239c090 b=0x239c060 x=5
Ctor(const Foo&): 0x239c094 b=0x239c064 x=6
Ctor(const Foo&): 0x239c098 b=0x239c068 x=7
Ctor(const Foo&): 0x239c09c b=0x239c06c x=8
Dtor(): 0x239c050 x=1
Dtor(): 0x239c054 x=2
Dtor(): 0x239c058 x=3
Dtor(): 0x239c05c x=4
Dtor(): 0x239c060 x=5
Dtor(): 0x239c064 x=6
Dtor(): 0x239c068 x=7
Dtor(): 0x239c06c x=8
Dtor(): 0x7ffffdda1ac0 x=0
push back 10
Ctor(int): 0x7ffffdda1ad0 x=10
Ctor(Foo&&): 0x239c0a4 b=0x7ffffdda1ad0 x=10
Dtor(): 0x7ffffdda1ad0 x=0
push back 11
Ctor(int): 0x7ffffdda1ae0 x=11
Ctor(Foo&&): 0x239c0a8 b=0x7ffffdda1ae0 x=11
Dtor(): 0x7ffffdda1ae0 x=0
push back 12
Ctor(int): 0x7ffffdda1af0 x=12
Ctor(Foo&&): 0x239c0ac b=0x7ffffdda1af0 x=12
Dtor(): 0x7ffffdda1af0 x=0
push back 13
Ctor(int): 0x7ffffdda1b00 x=13
Ctor(Foo&&): 0x239c0b0 b=0x7ffffdda1b00 x=13
Dtor(): 0x7ffffdda1b00 x=0
End:
Dtor(): 0x239c080 x=1
Dtor(): 0x239c084 x=2
Dtor(): 0x239c088 x=3
Dtor(): 0x239c08c x=4
Dtor(): 0x239c090 x=5
Dtor(): 0x239c094 x=6
Dtor(): 0x239c098 x=7
Dtor(): 0x239c09c x=8
Dtor(): 0x239c0a0 x=9
Dtor(): 0x239c0a4 x=10
Dtor(): 0x239c0a8 x=11
Dtor(): 0x239c0ac x=12
Dtor(): 0x239c0b0 x=13
Se zakomentovanym copy konstruktorem
Create vector:
Reserve 2
push back 1
Ctor(int): 0x7fff4c0f1eb0 x=1
Ctor(Foo&&): 0x2457010 b=0x7fff4c0f1eb0 x=1
Dtor(): 0x7fff4c0f1eb0 x=0
push back 2
Ctor(int): 0x7fff4c0f1ec0 x=2
Ctor(Foo&&): 0x2457014 b=0x7fff4c0f1ec0 x=2
Dtor(): 0x7fff4c0f1ec0 x=0
push back 3
Ctor(int): 0x7fff4c0f1ed0 x=3
Ctor(Foo&&): 0x2457038 b=0x7fff4c0f1ed0 x=3
Ctor(Foo&&): 0x2457030 b=0x2457010 x=1
Ctor(Foo&&): 0x2457034 b=0x2457014 x=2
Dtor(): 0x2457010 x=0
Dtor(): 0x2457014 x=0
Dtor(): 0x7fff4c0f1ed0 x=0
push back 4
Ctor(int): 0x7fff4c0f1ee0 x=4
Ctor(Foo&&): 0x245703c b=0x7fff4c0f1ee0 x=4
Dtor(): 0x7fff4c0f1ee0 x=0
push back 5
Ctor(int): 0x7fff4c0f1ef0 x=5
Ctor(Foo&&): 0x2457060 b=0x7fff4c0f1ef0 x=5
Ctor(Foo&&): 0x2457050 b=0x2457030 x=1
Ctor(Foo&&): 0x2457054 b=0x2457034 x=2
Ctor(Foo&&): 0x2457058 b=0x2457038 x=3
Ctor(Foo&&): 0x245705c b=0x245703c x=4
Dtor(): 0x2457030 x=0
Dtor(): 0x2457034 x=0
Dtor(): 0x2457038 x=0
Dtor(): 0x245703c x=0
Dtor(): 0x7fff4c0f1ef0 x=0
push back 6
Ctor(int): 0x7fff4c0f1f00 x=6
Ctor(Foo&&): 0x2457064 b=0x7fff4c0f1f00 x=6
Dtor(): 0x7fff4c0f1f00 x=0
push back 7
Ctor(int): 0x7fff4c0f1f10 x=7
Ctor(Foo&&): 0x2457068 b=0x7fff4c0f1f10 x=7
Dtor(): 0x7fff4c0f1f10 x=0
push back 8
Ctor(int): 0x7fff4c0f1f20 x=8
Ctor(Foo&&): 0x245706c b=0x7fff4c0f1f20 x=8
Dtor(): 0x7fff4c0f1f20 x=0
push back 9
Ctor(int): 0x7fff4c0f1f30 x=9
Ctor(Foo&&): 0x24570a0 b=0x7fff4c0f1f30 x=9
Ctor(Foo&&): 0x2457080 b=0x2457050 x=1
Ctor(Foo&&): 0x2457084 b=0x2457054 x=2
Ctor(Foo&&): 0x2457088 b=0x2457058 x=3
Ctor(Foo&&): 0x245708c b=0x245705c x=4
Ctor(Foo&&): 0x2457090 b=0x2457060 x=5
Ctor(Foo&&): 0x2457094 b=0x2457064 x=6
Ctor(Foo&&): 0x2457098 b=0x2457068 x=7
Ctor(Foo&&): 0x245709c b=0x245706c x=8
Dtor(): 0x2457050 x=0
Dtor(): 0x2457054 x=0
Dtor(): 0x2457058 x=0
Dtor(): 0x245705c x=0
Dtor(): 0x2457060 x=0
Dtor(): 0x2457064 x=0
Dtor(): 0x2457068 x=0
Dtor(): 0x245706c x=0
Dtor(): 0x7fff4c0f1f30 x=0
push back 10
Ctor(int): 0x7fff4c0f1f40 x=10
Ctor(Foo&&): 0x24570a4 b=0x7fff4c0f1f40 x=10
Dtor(): 0x7fff4c0f1f40 x=0
push back 11
Ctor(int): 0x7fff4c0f1f50 x=11
Ctor(Foo&&): 0x24570a8 b=0x7fff4c0f1f50 x=11
Dtor(): 0x7fff4c0f1f50 x=0
push back 12
Ctor(int): 0x7fff4c0f1f60 x=12
Ctor(Foo&&): 0x24570ac b=0x7fff4c0f1f60 x=12
Dtor(): 0x7fff4c0f1f60 x=0
push back 13
Ctor(int): 0x7fff4c0f1f70 x=13
Ctor(Foo&&): 0x24570b0 b=0x7fff4c0f1f70 x=13
Dtor(): 0x7fff4c0f1f70 x=0
End:
Dtor(): 0x2457080 x=1
Dtor(): 0x2457084 x=2
Dtor(): 0x2457088 x=3
Dtor(): 0x245708c x=4
Dtor(): 0x2457090 x=5
Dtor(): 0x2457094 x=6
Dtor(): 0x2457098 x=7
Dtor(): 0x245709c x=8
Dtor(): 0x24570a0 x=9
Dtor(): 0x24570a4 x=10
Dtor(): 0x24570a8 x=11
Dtor(): 0x24570ac x=12
Dtor(): 0x24570b0 x=13
#47 KIIV
Asi záleží na buildu, jaký používáš. V mém případě se defaultně používá move konstruktor, pokud move s rvalue reference zakomentuji, pak se použije copy, vyvíjím v nejnovějším Visual Studiu Community.
a když nechám třídu zcela bez komentářů (trošku jsem upravil výpisy, aby se mi lépe identifikovalo, o co se jedná), tedy
class Foo {
public:
Foo() : x(0) { cout << " CTOR(): " << this << " x=" << x << endl; }
Foo(int x_) : x(x_) { cout << " CTOR(int): " << this << " x=" << x << endl; }
Foo(const Foo& b): x(b.x) { cout << " COPY(const Foo&): "<< this << " b="<< &b <<" x="<< x << endl; }
Foo(Foo&& b) : x(b.x) { b.x = 0; cout << " MOVE(Foo&&): " << this << " b=" << &b << " x=" << x << endl; }
~Foo() { cout << " DTOR(): " << this << " x=" << x << endl; }
protected:
int x;
};
výsledkem je
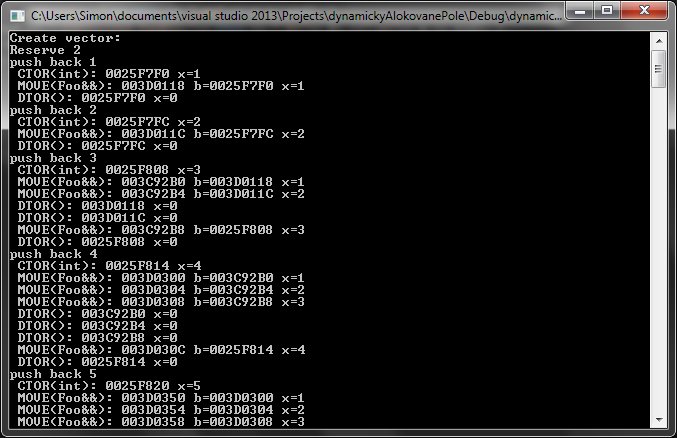
Upřímně, spíše mě překvapilo, jak často změna velikosti pole probíhá. Myslel jsem si, že si vektor alokuje místo v 2^n... 1, 2, 4, 8, 16, 32, 64, 128 atd., ale dle způsobu, jakým se konstruktory a move provádí, se vektor očividně alokuje úplně nějak jinak.
Pokud bych si rezervoval 20 míst a do pole vložil 21 položek, prvních 20 půjde vložit normálně a při 21. se musí přesunout celý obsah malého pole do nového většího.
Create vector:
Reserve 20
push back 1
CTOR(int): 0039FB4C x=1
MOVE(Foo&&): 00710118 b=0039FB4C x=1
DTOR(): 0039FB4C x=0
push back 2
CTOR(int): 0039FB58 x=2
MOVE(Foo&&): 0071011C b=0039FB58 x=2
DTOR(): 0039FB58 x=0
push back 3
CTOR(int): 0039FB64 x=3
MOVE(Foo&&): 00710120 b=0039FB64 x=3
DTOR(): 0039FB64 x=0
push back 4
CTOR(int): 0039FB70 x=4
MOVE(Foo&&): 00710124 b=0039FB70 x=4
DTOR(): 0039FB70 x=0
push back 5
CTOR(int): 0039FB7C x=5
MOVE(Foo&&): 00710128 b=0039FB7C x=5
DTOR(): 0039FB7C x=0
push back 6
CTOR(int): 0039FB88 x=6
MOVE(Foo&&): 0071012C b=0039FB88 x=6
DTOR(): 0039FB88 x=0
push back 7
CTOR(int): 0039FB94 x=7
MOVE(Foo&&): 00710130 b=0039FB94 x=7
DTOR(): 0039FB94 x=0
push back 8
CTOR(int): 0039FBA0 x=8
MOVE(Foo&&): 00710134 b=0039FBA0 x=8
DTOR(): 0039FBA0 x=0
push back 9
CTOR(int): 0039FBAC x=9
MOVE(Foo&&): 00710138 b=0039FBAC x=9
DTOR(): 0039FBAC x=0
push back 10
CTOR(int): 0039FBB8 x=10
MOVE(Foo&&): 0071013C b=0039FBB8 x=10
DTOR(): 0039FBB8 x=0
push back 11
CTOR(int): 0039FBC4 x=11
MOVE(Foo&&): 00710140 b=0039FBC4 x=11
DTOR(): 0039FBC4 x=0
push back 12
CTOR(int): 0039FBD0 x=12
MOVE(Foo&&): 00710144 b=0039FBD0 x=12
DTOR(): 0039FBD0 x=0
push back 13
CTOR(int): 0039FBDC x=13
MOVE(Foo&&): 00710148 b=0039FBDC x=13
DTOR(): 0039FBDC x=0
push back 14
CTOR(int): 0039FBE8 x=14
MOVE(Foo&&): 0071014C b=0039FBE8 x=14
DTOR(): 0039FBE8 x=0
push back 15
CTOR(int): 0039FBF4 x=15
MOVE(Foo&&): 00710150 b=0039FBF4 x=15
DTOR(): 0039FBF4 x=0
push back 16
CTOR(int): 0039FC00 x=16
MOVE(Foo&&): 00710154 b=0039FC00 x=16
DTOR(): 0039FC00 x=0
push back 17
CTOR(int): 0039FC0C x=17
MOVE(Foo&&): 00710158 b=0039FC0C x=17
DTOR(): 0039FC0C x=0
push back 18
CTOR(int): 0039FC18 x=18
MOVE(Foo&&): 0071015C b=0039FC18 x=18
DTOR(): 0039FC18 x=0
push back 19
CTOR(int): 0039FC24 x=19
MOVE(Foo&&): 00710160 b=0039FC24 x=19
DTOR(): 0039FC24 x=0
push back 20
CTOR(int): 0039FC30 x=20
MOVE(Foo&&): 00710164 b=0039FC30 x=20
DTOR(): 0039FC30 x=0
push back 21
CTOR(int): 0039FC3C x=21
MOVE(Foo&&): 00710348 b=00710118 x=1
MOVE(Foo&&): 0071034C b=0071011C x=2
MOVE(Foo&&): 00710350 b=00710120 x=3
MOVE(Foo&&): 00710354 b=00710124 x=4
MOVE(Foo&&): 00710358 b=00710128 x=5
MOVE(Foo&&): 0071035C b=0071012C x=6
MOVE(Foo&&): 00710360 b=00710130 x=7
MOVE(Foo&&): 00710364 b=00710134 x=8
MOVE(Foo&&): 00710368 b=00710138 x=9
MOVE(Foo&&): 0071036C b=0071013C x=10
MOVE(Foo&&): 00710370 b=00710140 x=11
MOVE(Foo&&): 00710374 b=00710144 x=12
MOVE(Foo&&): 00710378 b=00710148 x=13
MOVE(Foo&&): 0071037C b=0071014C x=14
MOVE(Foo&&): 00710380 b=00710150 x=15
MOVE(Foo&&): 00710384 b=00710154 x=16
MOVE(Foo&&): 00710388 b=00710158 x=17
MOVE(Foo&&): 0071038C b=0071015C x=18
MOVE(Foo&&): 00710390 b=00710160 x=19
MOVE(Foo&&): 00710394 b=00710164 x=20
DTOR(): 00710118 x=0
DTOR(): 0071011C x=0
DTOR(): 00710120 x=0
DTOR(): 00710124 x=0
DTOR(): 00710128 x=0
DTOR(): 0071012C x=0
DTOR(): 00710130 x=0
DTOR(): 00710134 x=0
DTOR(): 00710138 x=0
DTOR(): 0071013C x=0
DTOR(): 00710140 x=0
DTOR(): 00710144 x=0
DTOR(): 00710148 x=0
DTOR(): 0071014C x=0
DTOR(): 00710150 x=0
DTOR(): 00710154 x=0
DTOR(): 00710158 x=0
DTOR(): 0071015C x=0
DTOR(): 00710160 x=0
DTOR(): 00710164 x=0
MOVE(Foo&&): 00710398 b=0039FC3C x=21
DTOR(): 0039FC3C x=0
End:
nicméně pokud si nerezervuji nic, pak je při vkládání 21 položek dle výstupu kódu postupná velikost vektoru: 1, 2, 3, 4, 6, 9, 13, 19, 28. Vektory jsou divný.
g++ 4.8.1..
V g++ se zase vetsinou pouziva strategie "kdyz je potreba zvetsit, ber dvojnasobek". VS ma jak vidis trosku min nenazranou strategii, zalezi, kde to skonci a co nakonec bude lepsi.
#49 KIIV
Pokud by člověk měl hodně rozsáhlý objekt zabírající třeba 1500B, a udělal si vektor takových objektů, pak je určitě lepší varianta v g++, kde se velikost zvětšuje vždy dvojnásobně, nicméně v takovém případě by člověk asi nedělal vektor objektů, ale vektor ukazatelů na daný objekt a pak asi vyhrává vektor ve VS, protože nebude alokovat tolik volného místa jako vektor v G++ a přesunou 4B pointery je relativně levná operace.
Mimochodem co je nejlepsi, tak i pres tohle vsechno je vector pro vkladani a mazani na nahodne pozici nad serazenym polem nejrychlejsi (pro velky pole samozrejme). Hlavne diky tomu, ze jsou prvky pekne za sebou v pameti. Jak se skace pres vetsi bloky nez je velikost cache procesoru, tak se stara cache zahodi, nacte se nova. A tim se zabije cela vecnost strojovyho casu.
Viz prednaska Stroustrupa o standardu c++11, kde to zminuje.
#51 KIIV
Nad seřazeným polem, jako seřazeným vektorem? Na seřazenou strukturu by asi bylo lepší použít std::list, který má amortizovaný čas vkládání/mazání na konstantu, nebo ne? Podle mě, pokud chceš mít seřazený vektor, tak náročnost vkládání a mazání do/z takového vektoru je lineární, tedy horší než u seznamu. Pochopitelně náhodný přístup je u vektoru lepší.
#52 ondrej39
no jenze abys nasel insert point, tak ho musis projit. A pokud tim budes mit zabrano 50MB ramky a pri kazdym prechodu budes zbesile skakat sem a tam, tak jen to nalezeni mista te bude stat vic nez ve vectoru i s posunem dat za nim :)
Totez u pointeru, pokud bys musel dereferencovat pro zjisteni hodnot, tak ses zase na zacatku :)
EDIT: tady je rovnou ta cast z prednasky: https://www.youtube.com/watch?…
#53 KIIV
To jsem nevěděl, že to u polí bude zanedbatelný. U vektoru obsahující 50 milionů integerů vložení na začátek zabralo přibližně 6,5 vteřiny, což je, vzhledem k velikosti struktury, velmi dobrý výkon.
EDIT: Tu přednášku jsem už dokonce nedávno viděl :D. Scénku s grafem si velmi živě vybavuji.
 Zjistit počet nových příspěvků
Zjistit počet nových příspěvků
Přidej příspěvek
Toto téma je starší jak čtvrt roku – přidej svůj příspěvek jen tehdy, máš-li k tématu opravdu co říct!
Ano, opravdu chci reagovat → zobrazí formulář pro přidání příspěvku
×Vložení zdrojáku
×Vložení obrázku

×Vložení videa
Aktuálně jsou podporována videa ze serverů YouTube, Vimeo a Dailymotion.
×































Uživatelé prohlížející si toto vlákno
Uživatelé on-line: 0 registrovaných, 54 hostů
Podobná vlákna
Kopírování objektu — založil Peet
Uložení dat do dyn. alokovaného pole — založil aralxd
Kopírování čísel z pole do jiného datového typu — založil Cruppy
Pole v objektu — založil foxik
Pole objektu — založil tone
Moderátoři diskuze
