 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu

") Duch
Duch")
")
Zdravím, dělám utilitu pro práci s AVI soubory. Úspěšně dokážu číst INFO tagy, tak jsem se pokusil o editaci, ta potom selže - avi soubor se poškodí. Základem je struktura LIST, skládá se ze slova LIST, následně 4 byte velikosti v pořadí little-endian. Za tímto LISTem je ještě chunk JUNK, což je zarovnávací prostor, hlavička se opět skládá z 8byte - "JUNK" a 4 byte velikosti, velikost se počítá právě po hlavičce - těch 8 byte. To platí i pro LIST. LISTů je několik druhů, mne ovšem zajímá jen to INFO. Jsou to 4byte "INFO", hned po 8mi bytové hlavičce, takže se už počítá do velikosti. Následně obsahuje několik chunků. Opět 8 byte, první 4 byte je fourCC kód (např. INAM pro Title, IART pro Artist, atd.) následně délka následujícího řetězce a po řetězci nulový byte. Provedu konverzi dat do INFO struktury. Jelikož dojde ke změně velikosti, změnu vyrovnám tím následujícím chunkem JUNK, jehož obsah není důležitý a může složit např. pro skrytý popis. Otázka tedy zní, kde je problém? Když jsem si to projížděl v HEX editoru, formát se zdál být správný, ručně jsem kontroloval délky řetězců atd. Viz přiložené soubory
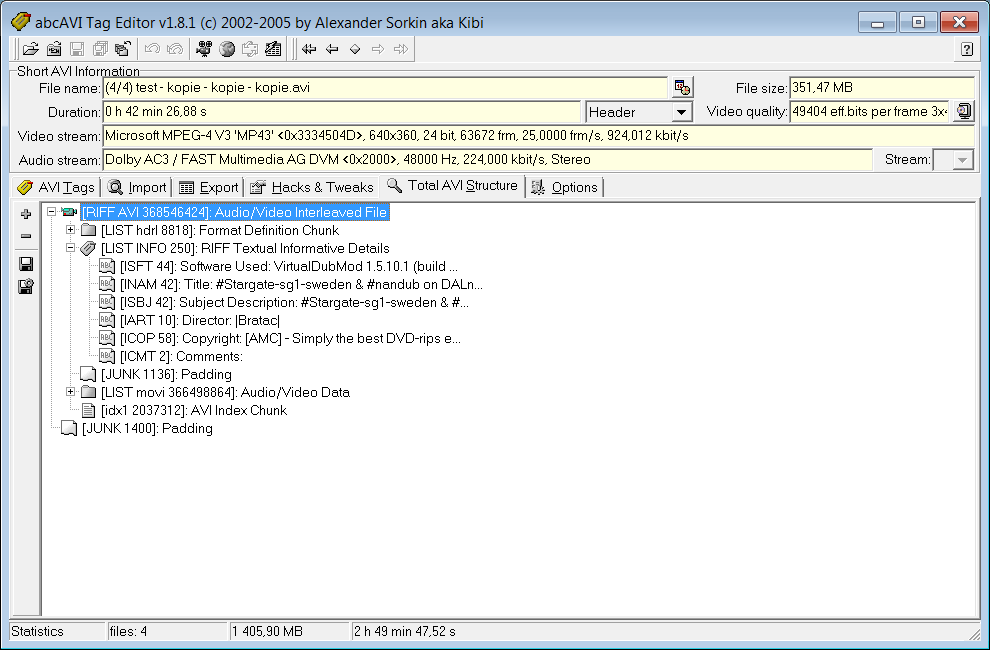
Na obrázku jde vidět právě onen LIST INFO a následně JUNK
V přiložených .bin souborech jsou surová data. Neobsahují na začátku slovo "LIST", začátek souboru je definice velikosti. old.bin je původní, new.bin je generovaný skriptem. Přikládám i onen skript. Zatím to je primitivní bast, čtení ovšem funguje bez problému. Důležitá je funkce write (parse.php), která zapíše asociativní pole AVItag::$tags do binární podoby a zapíše na patřičný offset.
https://drive.google.com/file/d/1UjBlS24HeYtm_FNMuGhSrGmqQJiObywL/view?usp=sharing
 Nahlásit jako SPAM
Nahlásit jako SPAM IP: 83.240.52.–
IP: 83.240.52.– Zjistit počet nových příspěvků
Zjistit počet nových příspěvků
































