

Pole lze použít na ukládání velkého množství dat. Jednou z důležitých oblastí zpracování takovýchto dat je třídění a v tomto díle si ukážeme, co to vlastně třídění je, k čemu nám je dobré a proč se mu budeme věnovat několik dalších dílů.
O co vlastně jde? Minule [ http://programujte.com/clanek/2011122300-vyvojove-diagramy-priklady-s-vyuzitim-poli-19-dil/ ] jsme si vygenerovali tiket Sportky a na výstupu jsme dostali čísla tak, jak byla vygenerována, a nikoliv seřazená podle velikosti. Kdybychom je chtěli v takovém pořadí, tak si musíme pole setřídit. Příklad výstupu algoritmu z 19. dílu:
| index [] | 1 | 2 | 3 | 4 | 5 | 6 |
| hodnota | 10 | 7 | 45 | 13 | 34 | 2 |
A takto by vypadalo pole setříděné (vzestupně):
| index [] | 1 | 2 | 3 | 4 | 5 | 6 |
| hodnota | 2 | 7 | 10 | 13 | 34 | 45 |
Tříděním se hodnoty v jednotlivých šuplíčcích seřadí tak, že víme, v jakém jsou pořadí, tj. pokud setřídíme pole vzestupně, tak v šuplíčku s označením A je jistě číslo menší nebo rovné číslu v šuplíčku A + 1.
Poznámka: v úloze s tiketem se nám čísla opakovat nemohla, ale v jiných úlohách se hodnoty v poli opakovat mohou, a proto ta neostrá nerovnost menší nebo rovno (<=)).
Teď si asi řeknete: a k čemu je mi to dobré? Představte si, že máte nesetříděné pole, které obsahuje 100 000 čísel různých hodnot (hodnoty se mohou opakovat, ale nemusí - je to jen na vás). A teď mi zjistěte, jestli je v poli uloženo číslo 768. To je přece jednoduché, řeknete si, projdu celé pole a toto číslo najdu (nebo nenajdu).
Ano, tak se to samozřejmě řešit dá a také nic jiného nezbývá (metoda se nazývá lineární vyhledávání [ http://cs.wikipedia.org/wiki/Line%C3%A1rn%C3%AD_vyhled%C3%A1v%C3%A1n%C3%AD ]). Když budu mít štěstí, tak bude číslo hned první testované. Když budu mít smůlu, tak to bude až to úplně poslední, tj. při tom nejhorším scénáři musím projít celé pole a to trvá (pokud někomu 100 tisíc připadá málo, tak může slovo tisíc nahradit třeba slovem milion nebo miliard :)).
A jak nám tedy pomůže setřídění? Když si pole setřídím a začnu ho procházet, tak sice mohu třeba již v půlce říct, že tam takové číslo není, když poslední testovaný šuplíček obsahoval číslo větší, ale když to hledané číslo bude to největší v poli, tak ho stejně projdu celé, nebo ne?
Samozřejmě to lze řešit jinak, a to tzv. metodou půlení intervalu (binární vyhledávání [ http://cs.wikipedia.org/wiki/Bin%C3%A1rn%C3%AD_vyhled%C3%A1v%C3%A1n%C3%AD ]). Řekněme, že máme to pole 100 000 hodnot a hledáme číslo 768. Vezmeme hodnotu ze šuplíčku uprostřed intervalu (index = 50 000), kde bude například hodnota 5689, takže víme, že všechny šuplíčky v poli za tímto (celá půlka pole) jsou jistě s hodnotou výše a již je nemusíme testovat. V tuto chvíli nám stačí otestovat pouze zbylých 50 000 (resp. 49 999) šuplíčků. Na ně samozřejmě můžeme použít stejnou metodu a vyřadit tak opět polovinu tohoto rozsahu. Na dvě porovnání jsme vyřadili 3/4 pole.
Složitost lineárního hledání je O(N), tj. maximálně počet prvků pole. Složitost binárního vyhledávání je O(1 + lg(N)) (kde lg je logaritmus při základu 2). Pro pole o délce 100 000 hodnot tedy potřebuje v prvním případě maximálně 100 000 porovnání. V druhém případě potřebuje maximálně 17 kroků k nalezení čísla, resp. k jeho případnému nenalezení. Efekt zrychlení je tedy více než markantní.
Pro ty, co něvěří :), je tu praktická ukázka výpisu - pole o délce 100 000 prvků a hledáme například číslo 768, které v poli není, takže je to ten nejhorší případ - až po posledním porovnání se dozvíme, že tam takové číslo není.
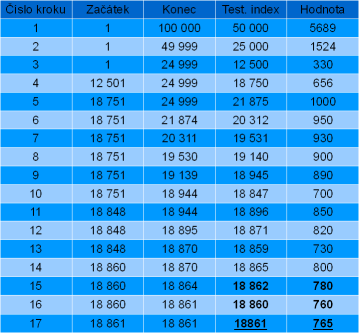
Ve výpisu jsou tučně vyznačené tři body, které ohraničují šuplíček, ve kterém by měla hledaná hodnota být. V šuplíčku s indexem 18862 je hodnota 780, takže naše hledané číslo musí být v šuplíčku s menším indexem (máme přeci setříděné pole). V šuplíčku 18860 je hodnota 760, takže hledané číslo musí být v šuplíčku s vyšším indexem. Z toho plyne, že jediným místem, kde by námi hledané číslo mohlo být, je šuplíček s indexem 18861 a tam takové číslo není, takže pole hledané číslo neobsahuje.
Samozřejmě platí, že máme-li pole a chceme-li pouze jednou najít nějaké číslo, tak je skoro jedno, jestli se provede setřídění nebo ne a podle toho se použije vyhledávání. Je potřeba si ovšem uvědomit, že v programech bývá nejčastější operace právě hledání, takže setřídění pole a výběr správného algoritmu vyhledávání se ve výsledné rychlosti programu projeví.
Abychom si v tomto díle udělali alespoň jeden vývojový diagram, tak si vyřešíme binární vyhledávání. Existují dva způsoby řešení: iteračně (cyklem) a rekurzivně. Ukážeme si obě s tím, že základní program bude jeden - volání funkce Najdi mimo jiné s parametrem, který bude obsahovat hodnotu prvku, který hledáme. Vracet bude boolean hodnotu, tj. true, pokud prvek v poli je, a v opačném případě bude vracet false.
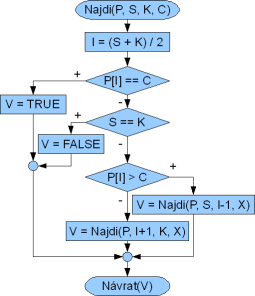
V obou případech předáváme do podprogramu čtyři parametry:
- P - pole
- S - počáteční (startovací) index
- K - poslední (koncový) index
- C - hledané číslo
Obě řešení jsou si velice podobná a rekurzivní zápis není o nic jednodušší než nerekurzivní. V rekurzivním máme funkci, které předáváme pole, počáteční a koncový index, mezi kterými hledáme. Tento rozsah postupně rozdělíme a dále rekurzivně testujeme pouze polovinu původního rozsahu, pokud již není číslo nalezené. Rekurze je ukončená ve chvíli, kdy číslo nalezneme nebo kdy již není možné dále rozsah dělit (počáteční a koncový index jsou shodné).
Nerekurzivní (iterativní) řešení funguje stejně, jenom si musíme udržovat aktuální počátek a konec prohledávaného rozsahu. Procházíme hodnoty pole v cyklu s podmínkou na začátku, která kontroluje, jestli je ještě co testovat (jestli testovaný index není stejný jako počáteční a koncový - rozsah obsahuje už pouze jeden šuplíček). Na počátku si index inicializujeme na -1, takže při prvním průchodu je podmínka určitě splněná. Dále to funguje stejně - kontroluje index v polovině rozsahu a pokud to není námi hledané číslo, tak podle porovnání (větší / menší) zmenšíme rozsah o polovinu zleva nebo zprava.
Oba vývojové diagramy vidíte na obrázcích. V příštím díle se ukážeme první tři metody třídění pole.