 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


Asi nejčastěji používaným typem kolekcí jsou seznamy. Jedná se o jeden z nejjednodušších ADT, jejich účelem je prosté uložení libovolných prvků, které mohou být duplicitní. Na následujících řádcích si však ukážeme, že jejich implementace zdaleka nemusí být tak triviální.
Úvod a rozdělení seznamů
Jak již bylo řečeno, v tomto díle se zaměříme na seznamy. Konkrétně se bude jednat o dva ADT:
- lineární seznam a
- cyklický seznam.
Další možností, jak kategorizovat seznamy, je dle způsobu uložení prvků v paměti. V principu existují tři:
- pomocí pole,
- vázané seznamy,
- kombinace obou.
Postupně se budeme zabývat všemi těmito způsoby a zvážíme jejich výhody a nevyýhody.
Pole
Než začneme se seznamy, podívejme se nejdříve na samotná pole. V .NET jsou pole referenčními typy (reference types) a to i v případě, kdy uchovávají pouze hodnotové typy (value types). Tudíž jsou uloženy na haldě (heap) a předávány odkazem (referencí).
V .NET můžeme nalézt podporu několika základních typů polí:
Jednorozměrné pole
Pokud mluvíme o "polích", máme standardně na mysli právě pole jednorozměrná. Deklarace probíhá následujícím způsobem:
T[] pole = new T[velikost];
Indexy všech polí začínají nulou (tzv. zero-based). Takovéto pole můžeme naplnit několika způsoby:
int[] pole = new int[5];
pole[0] = 1;
pole[1] = 2;
pole[2] = 3;
pole[3] = 4;
pole[4] = 5;
int[] pole = new int[5] { 1, 2, 3, 4, 5 };
int[] pole = new { 1, 2, 3, 4, 5 };
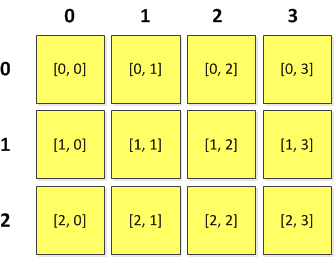
Dvojrozměrná a vícerozměrná pole
Dvojrozměrné pole si můžeme představit jako tabulku nebo matici (nemusí být čtvercová), viz obr. 1.
Deklarace dvojrozměrného pole:
T[,] matice= new T[sirka, vyska];
a jeho naplnění:
int[,] matice = new int[3, 2];
matice[0, 0] = 1;
matice[0, 1] = 2;
matice[1, 0] = 3;
matice[1, 1] = 4;
matice[2, 0] = 5;
matice[2, 1] = 6;
nebo
int[,] matice = new int[3, 2] { { 1, 2 }, { 3, 4 }, { 5, 6 } };
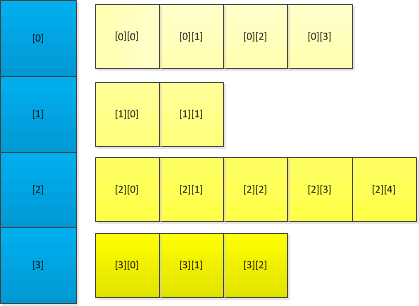
Pole polí, vícenásobné pole (jagged array)
Vícenásobná nebo chcete-li zanořená pole nejsou nic jiného než pole, jehož prvky jsou reference na další pole stejného typu, viz obr. 2.
Deklarace probíhá následovně:
T[][] vicenasobnePole = new int[velikost][];
a naplnění prvků takto:
int[][] vicenasobnePole = new int[3][];
vicenasobnePole[0] = new int[] { 1, 3, 5, 7, 9 };
vicenasobnePole[1] = new int[] { 0, 2, 4, 6 };
vicenasobnePole[2] = new int[] { 11, 22 };
nebo
int[][] vicenasobnePole = new int[][]
{
new int[] {1,3,5,7,9},
new int[] {0,2,4,6},
new int[] {11,22}
};
Třída Array a rozhraní
Každé pole implementuje následující rozhraní:
- IEnumerable<T>,
- ICollection<T>,
- IList<T>,
- ICloneable.
A kromě toho také dědí abstraktní třídu Array poskytující celou řadu další funkcionality:
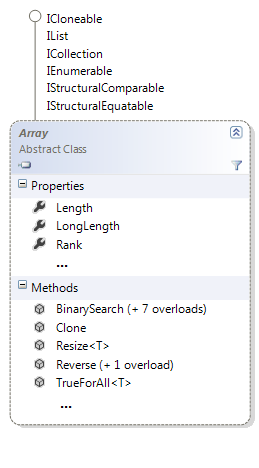
Nebudeme se zde zabývat všemi členy této třídy, podíváme se pouze na některé z nich:
- Length vrací velikost pole.
- LongLength - počet prvků pole ve všech dimenzích.
- Rank - počet dimenzí.
Vedle toho má i několik zajímavých statických metod:
- AsReadOnly() vrátí kolekci pouze pro čtení - ReadOnlyCollection.
- BinarySearch() je určena k vyhledávání nad seřazenými poli. Metoda má logaritmickou časovou složitost, a proto je rychlejší než foreach nebo extension metoda Find apod.
- Resize() zvětší velikost stávajícího pole.
- Reverse() otočí pořadí prvků v existujícím poli.
- atd.
Detailní popis třídy Array můžete nalézt na MSDN nebo na Devbooku.
Seznamy využívající pole
Typy
Seznamy s interním polem
A jak vlastně můžeme seznam naprogramovat? Jako první se nabízí varianta využívající jednorozměrné pole, které je po naplnění nahrazeno polem větším, viz obr. 4. Právě takovéto chování nalézneme u třídy List<T>.

Pole lze zvětšovat vždy o stejnou velikost, zdvojnásobit ji nebo použít libovolný jiný postup. Záleží na tom, k čemu má daná kolekce sloužit.
Hashed array
Problém s neustálým překopírováváním prvků částečně řeší datová struktura zvaná Hashed array. Ta místo jednorozměrného pole používá pole polí. Zde však nejde o vícenásobné pole (jagged array), popsané výše, ale spíš o pole objektů, které interně používají další pole, viz obr. 5 až 7.
I u této datové struktury dochází k překopírování dat z jednoho pole do druhého. Nepřekopírovávají se ale prvky všechny, nýbrž jen reference na pole, která je obsahují. Celý proces můžete vidět na obrázku 5 až 7:
Vytvoříme hlavičku a do ní vložíme pole pro jednotlivé prvky:
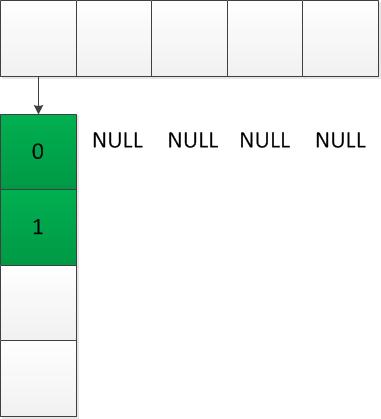
Po zaplnění prvního pole se do hlavičky přidá další:
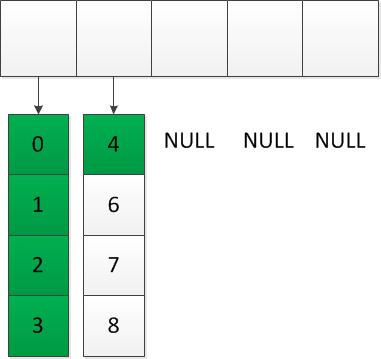
Když se zaplní všechna pole prvků i místa v hlavičce, dojde k vytvoření větší hlavičky, do níž se překopírují všechny reference:

Nevýhodou tohoto postupu je pomalý přístup k prvkům na základě indexu. Zatímco v předchozím případě můžeme přistupovat k prvkům na libovolné pozici prakticky okamžitě, u Hashed array musíme provést přepočet indexu na pozici v hlavičkovém i dceřiném poli.
Ring buffer
Zatímco předchozí datové struktury představovaly ADT lineární seznam, tak Ring buffer je seznamem kruhovým. Je to kolekce s fixní velikostí, nejčastěji znázorňovaná jako kruhové pole.
Dokud nejsou všechny volné pozice zaplněny, funguje stejně jako standardní lineární seznam (viz obr. 8) a indexy jednotlivých prvků se zvětšují s každým přidaným prvkem.
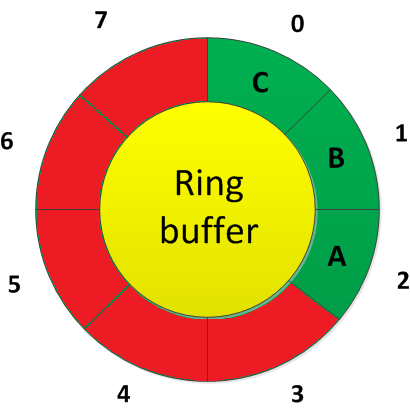
V okamžiku, kdy dojde k jeho zaplnění, se však počet prvků přestane zvětšovat:
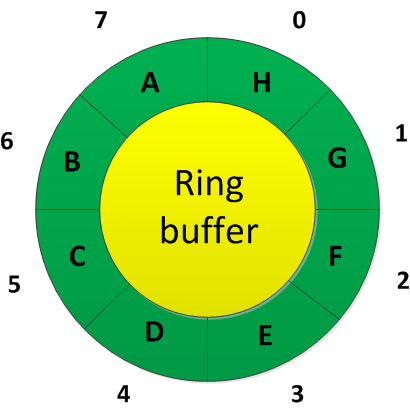
A začnou se odmazávat prvky přidané jako první:
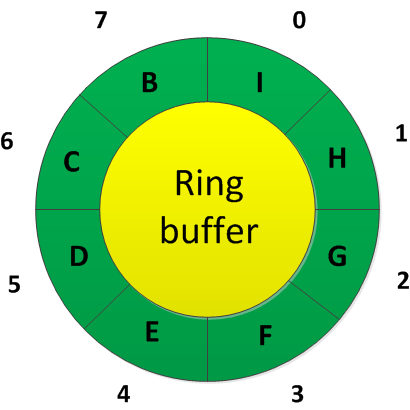
Implementace
Richard Feynman věřil, že musí existovat více způsobů, jak stáhnout z kočky kůži. Není jisté, jak tomu u koček opravdu je, ale zcela určitě to platí pro datové struktury, kruhový seznam nevyjímaje. K jeho implementaci bychom mohli použít např. vázaný seznam (což si ukážeme v příštím díle) nebo využít pole a jeho prvky přesouvat, my však zvolíme jiný přístup. Prvky nebudeme přesouvat, ale budeme posouvat začátek pole.
Základ třídy RingBuffer může vypadat následovně:
public class RingBuffer<T> : IEnumerable<T>
{
private readonly T[] _array; // pole s jednotlivymi prvky
private int _arrayInsertPosition; // pozice pro novy prvek
private bool _isArrayFull; // indikuje, zda pole jiz bylo zcela zaplneno
public int Length { get { return _array.Length; } }
public RingBuffer(int capacity)
{
_array = new T[capacity];
}
public void Add(T item)
{
// VLOZIME PRVEK
_array[_arrayInsertPosition] = item;
// NASTAVIME POZICI PRO VKLADANI NA NASLEDUJICI MISTO
_arrayInsertPosition++;
// POKUD JE VKLADACI POZICE MIMO ROZSAH POLE, ZACNE SE OPET OD ZACATKU
if (_arrayInsertPosition >= Length)
{
_arrayInsertPosition = 0;
_isArrayFull = true; // pole jiz bylo alespon jednou zcela zaplneno
}
}
}
Interní proměnná _array uchovává jednotlivé prvky RingBufferu, _arrayInsertPosition určuje, na kterou pozici v _array se má vložit další prvek. Nemusíme tedy přeskládávat prvky v poli, stačí měnit proměnnou _arrayInsertPosition.
Abychom mohli prvky i získávat, přidáme do třídy indexer:
private int recalculateIndexPosition(int index)
{
if (_isArrayFull)
{
int newestItemPosition = _arrayInsertPosition == 0 ? Length - 1 : _arrayInsertPosition - 1;
int recalculatedIndex = (newestItemPosition + index) % Length;
}
return index;
}
public T this[int index]
{
get { return _array[recalculateIndexPosition(index)]; }
set { _array[recalculateIndexPosition(index)] = value; }
}
Věškerá logika je ukryta v metodě recalculateIndexPosition, která přepočítá index viditelný zvnějšku třídy na ten používaný interně.
Jakmile máme indexování, není již těžké vytvořit enumerátor:
public class RingBufferEnumerator<T> : IEnumerator<T>
{
private readonly RingBuffer<T> _ringArray;
private int _index;
public RingBufferEnumerator(RingBuffer<T> ringArray)
{
_ringArray = ringArray;
}
public T Current { get { return _ringArray[_index]; } }
object System.Collections.IEnumerator.Current
{
get { return _ringArray[_index]; }
}
public bool MoveNext()
{
return _index++ < _ringArray.Length - 1;
}
public void Reset()
{
_index = 0;
}
public void Dispose() { return; }
}
a následně i implementovat IEnumerable<T> pro třídu RingBuffer:
public IEnumerator<T> GetEnumerator()
{
return new RingBufferEnumerator<T>(this);
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return new RingBufferEnumerator<T>(this);
}
Další typy seznamů
Seznamů založených na poli můžeme nalézt mnohem víc. Vždy však záleží na tom, pro kterou operaci chceme seznam optimalizovat. Pokud bychom např. často vkládali prvky doprostřed seznamu, bylo by vhodné zvážit použití Gab bufferu, viz Code project nebo Wikipedia.
Kolekce v .NET
List<T> je zdaleka nejznámější a nejpoužívanější kolekcí, bohužel je také kolekcí, která se nejčastěji používá i tam, kde to není zrovna nejvhodnější.
List<T> pro své fungování využívá pole způsobem z obr. 4, jehož velikost představuje property Capacity. Pokud jeho hodnotu nenastavíte přímo v konstruktoru Listu, tak se při vložení prvního prvku nastaví na čtyři. V okamžiku, kdy budete chtít přidat pátý prvek, velikost pole se zdvojnásobí. Při dalším naplnění pole se jeho velikost opět zdvojnásobí. Kapacita proto poroste následující řadou:
4, 8, 16, 32, ...
Je zřejmé, že neustálé přestavování pole při častém přidávání nebo odebírání prvků je dost neefektivní. Proto pokud alespoň přibližně znáte budoucí počet prvků v kolekci, vždycky nastavte kapacitu Listu v jeho konstruktoru.
Situace, kdy je ještě výhodné použít List a kdy už je vhodnější použít jinou kolekci, budou diskutovány v jednom z dalších dílů seriálu.
Collection<T> se nachází ve jmenném prostoru System.Collections.ObjectModel a implementuje IList stejně jako klasický List. Oproti Listu je však o něco málo pomalejší, a tudíž nevhodná pro běžné použití, ke kterému ani neni určena. Collection stejně jako všechny ostatní kolekce ve stejném namespace má sloužit pro tvorbu vlastních kolekcí. Osobně však doporučuji použití Collection důkladně zvážit a použít ji jen tam, kde je to nezbytně nutné. K tvorbě vlastních kolekcí si většinou vystačíte s Listem.
.NET Speciality
Ještě na okraj zmíníme další .NET kolekce používající pole, s velmi specifickým použitím, jimž bude věnován samostatný díl seriálu:
- ReadOnlyCollection<T> je určena pouze pro čtení a neumožňuje přidávání ani odebírání jednotlivých prvků.
- ObservableCollection<T> se poprvé objevila v .NET 3.0. Dědí od Collection, je tedy podobná Listu, navíc však implementuje rozhraní INotifyCollectionChanged a INotifyPropertyChanged, jež umožňují sledovat změny.
- ConcurrentBag<T>, BlockingCollection<T> jsou kolekce určené pro práci ve vícevláknovém prostředí a bude jim věnován samostatný díl seriálu.
- NameValueCollection z namespace System.Collections.Specialized. Tato kolekce určitým způsobem kombinuje vlastnosti slovníku a indexované kolekce, bohužel však pouze pro řetězce. Ke každé textové hodnotě musíte definovat také její textový klíč. Kolekci můžete procházet jak pomocí indexu, tak pomocí klíče.
- BitArray slouží k optimalizaci práce s bity a boolean proměnými.
Vázané (spojové) seznamy
Typy a rozdělení
Vázané seznamy (linked list) ke svému fungování nepotřebují pole. Jsou tvořeny objekty, které obsahují reference na jeden či více prvků seznamu.
Lineárně vázané seznamy
Vázané seznamy, které obsahují referenci pouze na předchozí nebo následující prvek, označujeme jako lineární jednosměrné (viz obr. 11).
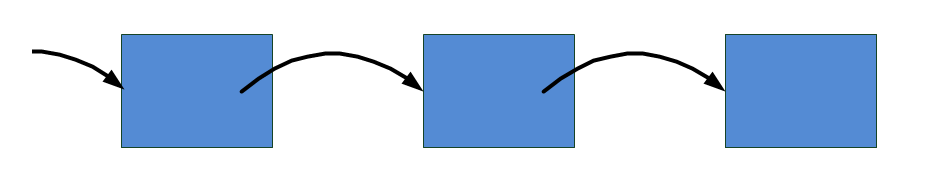
Pokud prvky vázaného seznamu mají referenci na předchozí i následující prvek, hovoříme o lineárních dvousměrných (double linked) seznamech (obr. 12).
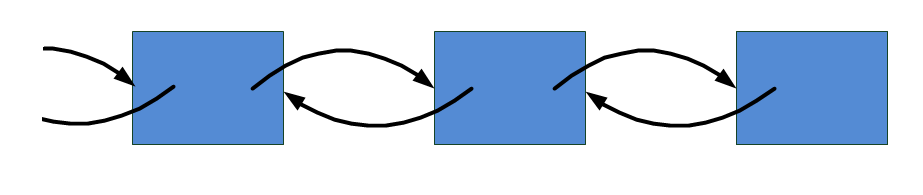
V .NET najdeme pouze dva lineárně vázané seznamy, a to LinkedList, který, ač tomu název nenapovídá, je dvousměrný, a ListDictionary, který je jednosměrný.
Cyklicky vázaný seznam
Pochopitelně vázané seznamy mohou mít i zcela jinou strukturu. Mohou být např. využity k implementaci stromu nebo utvořit kruh, viz obr. 13.

Skip list
Za zvláštní zmínku stojí tzv. skip list, nepříliš známá DS, představená světu teprve v roce 1989. Jedná se o řazený vázaný seznam, jehož jednotlivé prvky mají reference na více členů seznamu, viz obr. 4.
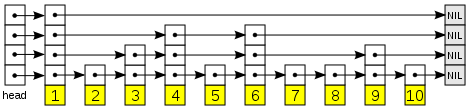
Skip list je zajimavý tím, že může sloužit jako náhrada stromových struktur, ale přitom je jeho implementace podstatně jednodušší. Více se můžete dozvědět např. v této prezentaci ze ZČU. Implementaci v C# můžete nalézt např. na Code projectu.
Kolekce v .NET
ListDictionary z hlediska funkčnosti také představuje slovník. Ovšem princip fungování je zcela odlišný, nepoužívá totiž hashovací algoritmus, ale pouhý jednosměrně vázaný seznam, čímž by ListDictionary měl být pro malé množství prvků efektivnější než hashovací tabulka. Samotný Microsoft doporučuje ListDictionary používat pro malé kolekce do 10 prvků. Pravdivost této teze prověříme v jednom z dalších pokračování.
LinkedList<T> je dvousměrně vázaný lineární seznam, můžeme na něj proto pohlížet jako na alternativu k klasickému Listu. LinkedList při vkládání a mazání prvků nemusí přeskládávat pole, tudíž by se dalo očekávat, že tyto dvě operace budou rychlejší, naopak procházení pomocí indexu zase pomalejší. Při časté práci s prvky kolekce se nám navíc mohou stát neocenitelnou pomůckou metody jako AddAfter, AddBefore, AddFirst, AddLast nebo RemoveFirst nebo RemoveLast.
Porovnání obou přístupů
Výhody a nevýhody
Jak seznamy založené na polích, tak seznamy založené na referencích mají své výhody a nevýhody.
Vkládání/mazání prvků
Výhodou vázaných seznamů oproti poli je vetší flexibilita během vkládání a mazání prvků především na začátek nebo doprostřed kolekce.
Indexace
Indexy jsou naprosto jasným nepřítelem vázaných seznamů. Zatímco pole má v tomto případě časovou složitost O(1), tak vázané seznamy dosahují O(n).
Paměťová náročnost
Nevýhodou vázaných seznamů je jejich paměťová náročnost. Představme si např. situaci, kdy chceme pomocí vázaného pole uchovávat čístla typu int, který v paměti zabírá 32 bitů, pak zároveň každá vazba mezi jednotlivými prvky bude zabírat u 32bitového systému taktéž 32 bitů a u 64bitového systému dokonce 64!
Jedná se však o nevýhodu diskutabilní. Pokud totiž přestřelíme počet prvků, které budeme vkládat do kolekce používající pole, pak nevyužitá část pole může bez problémů zabrat více paměti než reference v případě vázaných seznamů.
Unrolled list
Jednou z datových struktur, která se snaží vytěžit to nejlepší z obou principů je unrolled list. V podstatě se nejedná o nic jiného než vázaný seznam, jehož prvky jsou pole, viz obr. 15.
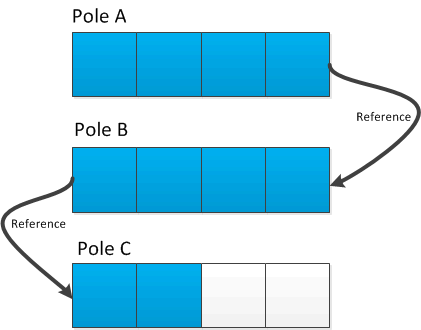
Implementace
Protože Unrolled list je kolekcí velmi jednoduchou a při tom je zároveň poměrně efektivní, pokusím se nyní o jeho implementaci.
Nejprve nadefinujeme třídu zapouzdřující pole:
public class UnrolledListNode<T>
{
private int _currentIndex; // pozice pro pridani dalsiho prvku
public T[] Array { get; set; } // pole pro jednotlive prvky
public UnrolledListNode<T> Next { get; set; } // nasledujici uzel
public UnrolledListNode(int capacity)
{
Array = new T[capacity];
}
public bool Add(T item)
{
Array[_currentIndex] = item;
return Array.Length <= ++_currentIndex;
}
public bool IsFull(int index)
{
return Array.Length <= index +1 ;
}
}
Kapacita těchto uzlů by mohla být vždy konstantní, my ji však budeme zvětšovat stejným způsobem jako u třídy List<T>.
Základ třídy UnrolledList<T>:
public class UnrolledList<T> : IEnumerable<T>
{
// kapacita nového uzlu
private int _nodeCapacity = 4;
// uzel pro pridani dalsich prvku
private UnrolledListNode<T> _currentNode { get; set; }
// prvni uzel kolekce
public UnrolledListNode<T> FirstNode { get; set; }
public UnrolledList()
{
_currentNode = FirstNode = new UnrolledListNode<T>(_nodeCapacity);
}
public void Add(T item)
{
if (_currentNode.Add(item))
{
_nodeCapacity *= 2;
_currentNode.Next = new UnrolledListNode<T>(_nodeCapacity);
_currentNode = _currentNode.Next;
}
}
...
}
Enumerátor kolekce může vypadat následovně:
public class UnrolledListEnumerator<T> : IEnumerator<T>
{
private int _currentIndex;
private UnrolledListNode<T> _currentNode;
private UnrolledList<T> _list;
public UnrolledListEnumerator(UnrolledList<T> list)
{
_list = list;
_currentNode = list.FirstNode;
}
public T Current
{
get { return _currentNode.Array[_currentIndex]; }
}
public void Dispose() { return; }
object System.Collections.IEnumerator.Current
{
get { return Current; }
}
public bool MoveNext()
{
_currentIndex++;
if (_currentNode.IsFull(_currentIndex))
{
_currentIndex = 0;
_currentNode = _currentNode.Next;
}
return __currentNode != null;
}
public void Reset()
{
_currentIndex = 0;
_currentNode = _list.FirstNode;
}
}
Použití
K čemu může být UnrolledList užitečný? Uvažujme situaci, kdy incializujeme, naplníme a cyklem foreach projdeme všechny prvky v třídě List a UnrolledList, zjistíme, že pro malé počty prvků je List zanedbatelně rychlejší, avšak pro velké množství prvků (zhruba 50 000 a více) se situace otočí a UnrolledList bude rychlejší. Další výhodou je nižší paměťová náročnost, List je totiž z hlediska paměťové složitosti otesánkem viz SlimList z Codeproject a v některých případech dokonce u Listu dosáhneme OutOfMemoryException, zatímco UnrolledList funguje bez potíží dál.
Závěr
Cílem tohoto dílu bylo především ukázat, že problematika seznamů je mnohem komplikovanější, než se může zdát, a také čtenáři ukázat různé způsoby řešení. V příštím díle se podíváme především na slovníky, řeč bude mimo jiné o hashovacích tabulkách a stromech.
Pokud máte jakékoli připomínky, otázky nebo pochvalu, napište to prosím do komentářů. Je to jediný feedback, který autor má.
Zdroje:
- Seznam datových struktur: http://en.wikipedia.org/wiki/List_of_data_structures
- Vázaný seznam: http://en.wikipedia.org/wiki/Linked_list
- Cyklický seznam: http://en.wikipedia.org/wiki/Circular_buffer
- Třída Array: http://msdn.microsoft.com/en-us/library/system.array.aspx
- Gap buffer: http://www.codeproject.com/Articles/20910/Generic-Gap-Buffer



