 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


S fulltextovými vyhledávači, jako je například Seznam.cz nebo Google, pracujeme každý den. V třídílném článku se podíváme na to, jaké komponenty jej tvoří a na co si dát pozor při optimalizaci pro vyhledávače (SEO).
Aby byly vyhledávače schopny v reálném čase prohledávat internet, musí nejprve projít co nejvíce stránek a předpřipravit si datovou strukturu – tzv. index. Fulltextové vyhledávače tedy při položení dotazu vyhledávají až v tomto indexu.
Principiálně vyhledávače fungují ve třech krocích:
- crawlování (sbírání dat do databáze vyhledávače),
- indexace (příprava indexu),
- výdej výsledků.
Schéma fungování fulltextových vyhledávačů je ve zjednodušené formě zobrazeno na následujícím obrázku.
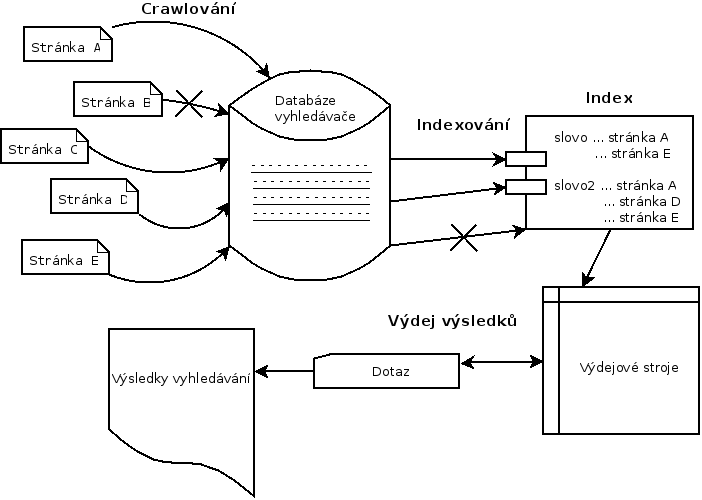
Princip fungování fulltextových vyhledávačů.
Crawler
Crawler je program, který prochází internetové dokumenty a přes HTTP protokol si o nich ukládá důležitá data jako jejich obsah (text), metadata (datum stažení dokumentu, hash dokumentu, zda došlo ke změně dokumentu od poslední návštěvy apod.), případně informace o zpětných odkazech.
Crawler si také ukládá hypertextové odkazy (tj. obsah HTML atributů src a href) na další dokumenty, které bude stahovat v budoucnu. Z toho plyne, že jako prvotní vstup je potřeba crawlerovi dodat několik URL adres, na kterých může nalézt další adresy.
Vytváří si tak seznam URL adres, které se budou dále stahovat. Data se ukládají na pevné disky o vysokých kapacitách. Na internetu je teoreticky nekonečně mnoho webových stránek – i na jednom webu lze dynamicky vytvářet velké množství stránek, které mají unikátní (ale často nesmyslný) obsah.
Přesto, že dnes se ceny pevných disků pohybují v řádech korun za gigabyte, není v reálných schopnostech crawlera stáhnout všechny stránky na internetu. Musí se tedy rozhodnout, které stránky jsou dostatečně kvalitní a měly by se vyskytovat v indexu. Při tomto rozhodování používá výběrovou funkci, kde jsou vstupy parametry dokumentu a výstupem je, zda se bude dokument stahovat nebo ne.
Problém duplicitního obsahu
Pokud se na více než jedné URL adrese vyskytuje stejný obsah, jde z pohledu vyhledávače o duplicitní obsah. Duplicitní obsah je nežádoucí jev – pokud by měl vyhledávač v indexu dva zcela (nebo i částečně) totožné dokumenty, pouze by zabíraly místo. Cílem vyhledávačů je poskytovat kvalitně tříděné dokumenty svým uživatelům, což duplicitní obsah rozhodně není.
Crawler tedy musí být schopen detekovat, zda již stejnou stránku nemá uloženou. Nejčastější způsob je vytvoření hashe dokumentů – pokud se při porovnání hashe sobě rovnají, jde o duplicitní obsah. V rámci webů vznikají často tzv. přirozené duplicity, které mají tvary:
- http://example.com/,
- http://example.com/index.html,
- http://www.example.com/,
- http://www.example.com/index.html.
V případě URL adres s několika parametry vznikají přirozené duplicity také při různém pořadí parametrů. Pokud je například URL adresa s parametry http://www.example.com/?x=1&y=2, přirozená duplicita je URL ve tvaru http://www.example.com/?y=2&x=1.
Z množiny přirozených duplicit crawler vybere jednoho zástupce – tzv. kanonickou stránku, kterou považuje za nejdůležitější. Pro označení kanonické stránky existuje i řídicí sekvence rel=canonical, kterou podporuje jak Google, tak Seznam.cz.
Crawler také musí umět pracovat s HTTP přesměrováními a dalšími stavovými kódy. Častým stavovým HTTP kódem je 404 Not found. Pokud takovou stránku crawler navštíví poprvé, tak si ji neukládá. Pokud však tato stránka vracela dříve HTTP 200 OK a nyní hlásí 404 Not found, není vhodné ji hned odstranit jak z databáze vyhledávače, tak z indexu.
V těchto případech se pouze odstraní z výdeje a v databázi nadále zůstává. Crawler ji v budoucnu navštíví ještě několikrát. Pokud stránka i nadále vrací kód 404, tak se odstraní také z databáze. Stránka s odstraněnou URL adresou se však na serveru může objevit v budoucnu znovu. V této chvíli ji však crawler i index vnímá jako zcela novou stránku. Z tohoto důvodu je zásadní neměnit jednou vytvořené URL adresy, protože tím přicházíte o pracně budovanou hodnotu dané URL. Jde o jednu z fundamentálních věcí při optimalizaci pro vyhledávače (SEO).
Podobné situace často nastávají při změně redakčního systému na webu. Proto je potřeba tento proces důsledně dozorovat, přesměrovat všechny staré URL adresy na nové a především tento proces důsledně zkontrolovat. Podívejte se, jak byla například naplánována změna domény u MOZu.
Obdobně crawler pracuje s dalšími HTTP kódy 4xx (chyba na straně klienta) a 5xx (chyba serveru). Výjimkou je HTTP kód 410 Gone, který podle specifikace RFC 2616 sděluje klientovi (crawleru), že požadované zdroje již nejsou k dispozici a neexistuje alternativní adresa. Klient by si měl v případě tohoto kódu odstranit z databáze informace o dané adrese – v případě vyhledávače by se tedy měla stránka odstranit jak z výdeje, tak z indexu i databáze.
Crawler musí být také naprogramován tak, aby neposílal na server velké množství požadavků během krátkého časového úseku. Mohl by server zahltit.
Crawler si ukládá nejen soubory typu HTML, PHP, ASPX apod., ale také další typy, které je schopen převést do textové podoby (například DOC, PDF, RTF, ODS, atd.).
Veškeré soubory, které jsou jednotlivé vyhledávače schopny indexovat, lze nalézt v oficiální nápovědě (pro Google). Protože se dokumenty na internetu mění, crawler musí v určitém intervalu stránky znovu navštívit a stáhnout. Není technicky možné navštěvovat všechny stránky ve velice krátkých časových úsecích za sebou, proto crawler používá rozhodování, které je založeno na:
- Frekvenci změn – pokud se při každé návštěvě na dané stránce mění obsah, crawler ji bude častěji stahovat.
- Interní hodnocení (rank) vyhledávače – například PageRank u Googlu nebo S-rank u Seznamu. Platí, že čím vyšší je rank, tím častěji stránku crawler navštěvuje.
- Technická omezení serverů – snaha nezahltit servery, kde jsou umístěné stahované dokumenty.
Může se stávat, že některé stránky webu crawler vůbec nestahuje. Pokud tento problém zjistíte (například analýzou serverových logů), je velice důležití zjistit příčinu. Ta často bývá v nevhodně zvolené informační architektuře webu, kdy jsou stránky zanořeny v navigačním stromu příliš hluboko.
Jak zamezit přístupu crawlera
Autoři vyhledávačů dávají provozovatelům webu možnost zákazu vstupu robotů. Zakázat lze přístup buď na celý web, nebo pouze pro vybrané adresáře či části webu. V praxi se zákaz pro roboty využívá například u stránek administrace webu, stránek určených pouze pro tisk nebo interních diskuzních fór. Časté je také použití z důvodu výskytu duplicitního obsahu na webu, kdy nechci, aby robot na duplicitní stránky chodil a stahoval je.
Duplicitní obsah pouze rozmělňuje hodnocení kanonické stánky a stahování takových stránek má za následek vyčerpání limitu crawlera pro web a příčinu nestahování dalších dokumentů.
Robots Exclusion Protocol – robots.txt
Soubor robots.txt je jednoduchý způsob, jak zakázat robotům vstup na web. Jde o malý textový soubor, který musí být umístěn v kořenovém adresáři webu (např. http://www.example.com/robots.txt) a být pojmenován malými písmeny.
Pokaždé když robot vyhledávače přijde na web, měl by si nejprve stáhnout robots.txt a zjistit, zda má nebo nemá přístup k požadovanému dokumentu. Největší vyhledávače (Google, Seznam.cz, Bing apod.) se tímto protokolem řídí. Mohou však existovat menší vyhledávače, případně jiní internetoví roboti, kteří robots.txt budou ignorovat. Vytvoření robots.txt však není nutné (a to ani prázdného souboru), pokud není u webu potřeba procházení robotům zakazovat. (robots.txt však slouží například i k uvedení odkazu na soubor sitemap.xml, což je u větších webů nezbytné.)
Obecná syntaxe robots.txt je následující:
User-agent: <jméno robota>
Disallow: <adresa, která nemá být procházena>
Allow: <adresa s explicitně povolenou indexací>
Jméno robota (user-agent) je název, pomocí kterého se crawleři identifikují při připojení na server. Jména robotů lze dohledat pomocí serverových logů, případně v nápovědě jednotlivých vyhledávačů. Google se identifikuje jako Googlebot, Seznam.cz jako Seznambot. V případě Googlu lze nastavit pravidla speciálně pro roboty procházející mobilní weby, obrázky a sloužící pro systémy AdSense a AdWords. Jejich user-agenti jsou:
- Googlebot-Mobile – prochází stránky pro index mobilních webů,
- Googlebot-Image – prochází stránky pro index obrázků,
- Mediapartners-Google – prochází stránky za účelem určení obsahu pro systém AdSense (reklamní systém společnosti Google),
- Adsbot-Google – prochází stránky za účelem měření kvality cílových stránek AdWords (systém pro PPC reklamu společnosti Google).
Dalším zdrojem pro názvy robotů je Robots Database, ve které se však nenacházejí všichni roboti – chybí například český Seznambot.
Jméno crawlera se dá v robots.txt nahradit symbolem *, který znamená, že pravidla níže se mají aplikovat pro všechny roboty. Řádek User-agent lze v robots.txt uvádět i několikrát a určit tak pro různé crawlery jiná pravidla.
Direktivy Disallow a Allow určují konkrétní URL adresu, složku nebo množinu URL adres, které mají, respektive nemají zákaz procházení pro vybrané roboty. Adresářová adresa vždy musí začínat lomítkem (/).
Robots.txt ve verzi 2.0 poskytuje také řídicí sekvence podobné regulárním výrazům. Jejich přehled je uveden v následující tabulce. V této verzi se vždy porovnává celá URL adresa, ne pouze začátek, jako tomu bylo ve verzi 1.0.
| Symbol | Význam |
| * | jakýkoli řetězec o délce 0 - n |
| ? | jakýkoli řetězec délky právě 1 |
| $ | konec adresy |
| \ | escape sekvence následujícího znaku, např. "index.php\?" bude brát jako "index.php?" |
Poznámka: Pokud se používají rozšířené řídící sekvence (tj. *, ? , $, \) pro Seznambot, je nutné po user-agent uvést příkaz Robot-version: 2.0.
Ukázka obsahu robots.txt s více pravidly je uvedena v následujícím kódu.
# zakaz vstupu na cely web krome adresare /tajne/
# explicitne zakazany podadresar /tajne/verejne/
# plati pro vsechny roboty
User−agent : ∗
Disallow : /
Allow : /tajne/
Disallow : /tajne/verejne/
# Seznambot nemuze prochazet . xlsx soubory
User−agent : Seznambot
Robot−version : 2.0
Disallow : ∗. xlsx\$
Meta tag robots
Indexaci lze zakázat také přímo v HTML kódu konkrétní stránky pomocí meta tagu robots. Ten se umisťuje do HTML hlavičky (mezi tagy <head> a </head>), přičemž hodnota atributu name je robots. Dalším atributem je content, který může nabývat následujících hodnot:
- index, noindex – povoluje, respektive zakazuje, indexaci dané stránky robotům. Index je implicitní hodnota.
- follow, nofollow – povoluje, respektive zakazuje, robotům následovat odkazy z daného dokumentu na další stránky. Follow je implicitní hodnota.
- all – zkrácený zápis pro index a současně follow,
- noarchive – zabrání uchování kopie dokumentu v mezipaměti/archivu vyhledávače,
- nosnippet – zabrání ve zobrazování úryvků (snippetů) dané stránky ve vyhledávači.
Příklad kódu meta tagu robots, který zakazuje indexaci dané stránky:
<META name="robots" content="noindex" />
Po procesu crawlování následuje indexace, které se věnuje další článek.
Zdroje a další informace
Můžete se podívat na videa Dušana Yuhů Janovského, ze kterých tento článek také čerpá:



