 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


Master Data (česky také kmenová data) jsou data sdílená napříč různými systémy, nemění se příliš často a netransakční. Jedná se o informace o obchodních partnerech, produktech, vlastních pracovnících. Objednávky, faktury, účetní zápisy do této oblasti nespadají.
Zvláštní oblastí master dat jsou referenční data (česky číselníky). Referenční data představují povolené hodnoty v polích jiných dat. Například stav objednávky, typ zákazníka, kategorie produktu atd. Povolené hodnoty číselníků jsou pak základními řídícími daty informačního systému, který je pro nás modelem naší business reality.
Pokud dnes data pořizujete v různých systémech, s různou kvalitou a nekonzistentními atributy, pak vám právě Master Data Management pomůže data sjednotit a zajistit jejich propagaci napříč organizací.
Při zavádění procesu Master Data Management nejprve zmapujeme danou oblasti a vyjasníme odpovědnosti. To již samo o sobě představuje zlepšení situace. Následně se budeme moci rozhodnout, jak daný systém vylepšit.
1.Identifikace zdrojů kmenových dat
Sepíšeme si jednotlivé aplikace, které s těmito daty pracují.
2.Klasifikace zdrojů
Aplikace si rozdělíme na producenty (data v nich vznikají) a konzumenty (data získávají odjinud). Každá aplikace může být pro některá master data producentem, pro jiná konzumentem a jiná data se jí netýkají.
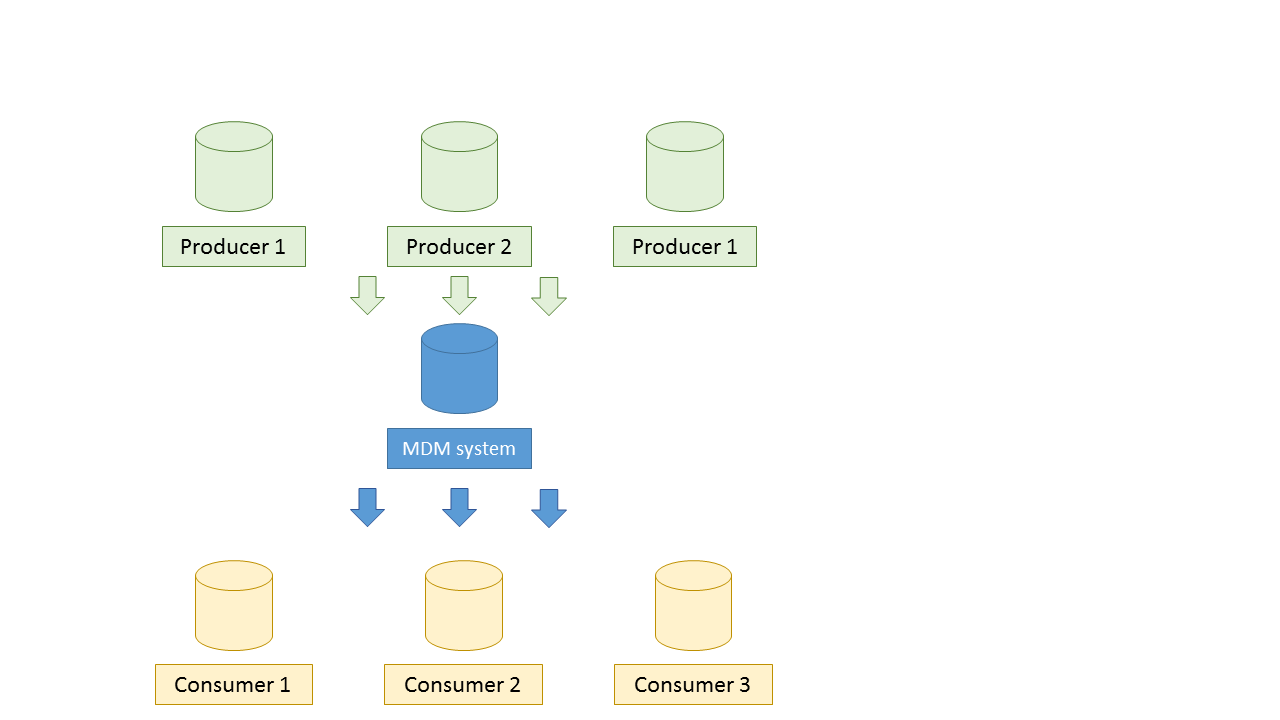
Obrázek 1: Rozdělení systémů na producenty a konzumenty (vždy z pohledu konkrétní datové entity)
3.Zmapování toků dat
Detailněji si popíšeme výměnu dat. Z jakého zdrojového systému do jakého cílového systémupřenášíme jaká data, jak často, jakou technologií, v jakém formátu. Ve chvíli, kdy budeme mít zmapovaný stávající stav, budeme schopni formulovat možnosti zlepšení a způsob přechodu na cílový stav.
4.Stanovení zodpovědností
Je třeba stanovit, kdo je zodpovědný za jaká data. Vlastník dat je zodpovědný za kvalitu dat a měl by to být někdo z managementu společnosti. Datový stevard spravuje data, jejich strukturu a pravidla dle rozhodnutí vlastníka. Různá data mohou mít vlastníky a datové stevardy v různých týmech.
5.Vytvoření datového modelu kmenových dat
Kmenová data nejsou izolovanými tabulkami. Je důležité znát jejich strukturu a vazbu na další data. Datový model ve formě Entity Relationship Diagramunám všechny tyto vztahy přehledně zachytí.
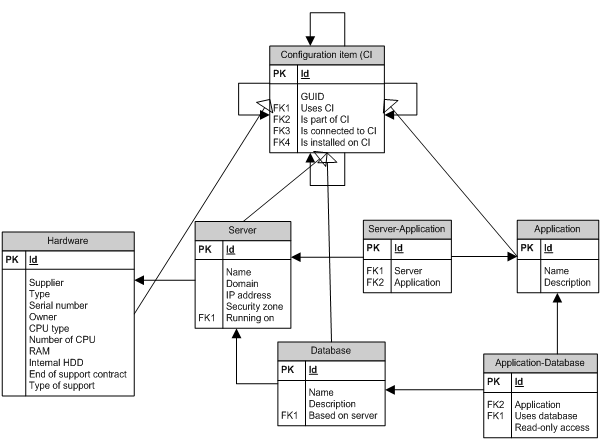
Obrázek 2: Příklad Entity Relationship Diagramu
6.Architektura master dat, pravidla a plán jejího naplňování, proces práce s master daty
Existuje několik konceptů práce s master daty. Jedním z nich je pořizování a správa všech master dat v jednom k tomu určeném systému a distribuce dat do všech dalších. Tento koncept jednoho místa pravdy nám totiž krásně řeší předchozí problém. Z pragmatických důvodů ale volíme různé přístupy. Přechod na tento systém totiž vyžaduje úpravu aplikací, v nichž data nově nemají být zadávána, ale které je mají odebírat z centrálního systému. U některých aplikací by jejich úprava byla velmi náročná, a tak budeme muset akceptovat, že například některá data budou i nadále pořizována v původním systému a do d centrálního MDM systému se budou pouze přenášet.
7.Výběr technologií
Podle zvolené architektury a strategie vybereme konkrétní technologie, které nám práci s master daty usnadní.
8.Přechod k cílové architektuře master dat a každodenní správa
Přechod k cílové architektuře závisí na vstupních podmínkách firmy. Organizace, která si důležitost master dat uvědomuje na začátku budování systémů, je na tom jinak než firma, v níž docházelo k překotnému rozvoji informačních systémů a která má v této oblasti určitý dluh. Postupnou aplikací pravidel, postupně začneme data zkvalitňovat a řešit stávající problémy. To, že to bude v případě již rozvinutého informačního systému běh na delší trať, je třeba brát jako realitu a nezaleknout se toho. Přínosy začneme vidět již brzy a hlavně začneme pokládat základy zdravého systému a toto úsilí se nám v budoucnosti vrátí.
V čem nám toto řešení pomůže?
- Správná a přesná data umožní správná rozhodování.
- Data konzistentní napříč systémy budou mít potřebnou věrohodnost a uživatelé tak s nimi budou ochotni pracovat.
- Pokud nebudete mít problémy s daty, zvýší se efektivita a rychlost procesů. Uživatelé už nebudou muset čekat, než IT opraví data.
- Sníží se náklady na další IT projekty i každodenní provoz IT, protože už nebude třeba řešit opravy dat a složité napojování na nekonsolidovaná data.
Pokud vás problematika Master Dat zaujala, více informací můžete získat v podrobném článku.



