 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


V předcházejícím článku bylo vysvětleno, proč a jak si fulltextové vyhledávače připravují databázi pomocí crawleru. Dnes si popíšeme proces vytváření invertovaného seznamu (indexu), ve kterém se následně vyhledává, a také to, jak se index aktualizuje.
Tento článek navazuje na předcházející díl, který se věnuje crawleru a vytváření databáze vyhledávače.
Indexace je proces vytváření datové struktury, která se v souvislosti s vyhledávači nazývá index. Jde o invertovaný seznam — někdy také označovaný jako fulltextový index — kde jsou klíčem slova, která se vyskytují v jednotlivých dokumentech.
Ke každému slovu jsou v indexu přiřazeny dokumenty, které toto slovo obsahují, a pozice daného slova v dokumentu (případně další informace podle konkrétní implementace). Index si lze jednoduše představit jako rejstřík v knize, viz následující obrázek. Pro každé slovo, které má vyhledávač zaindexované, existuje jeden takový index.
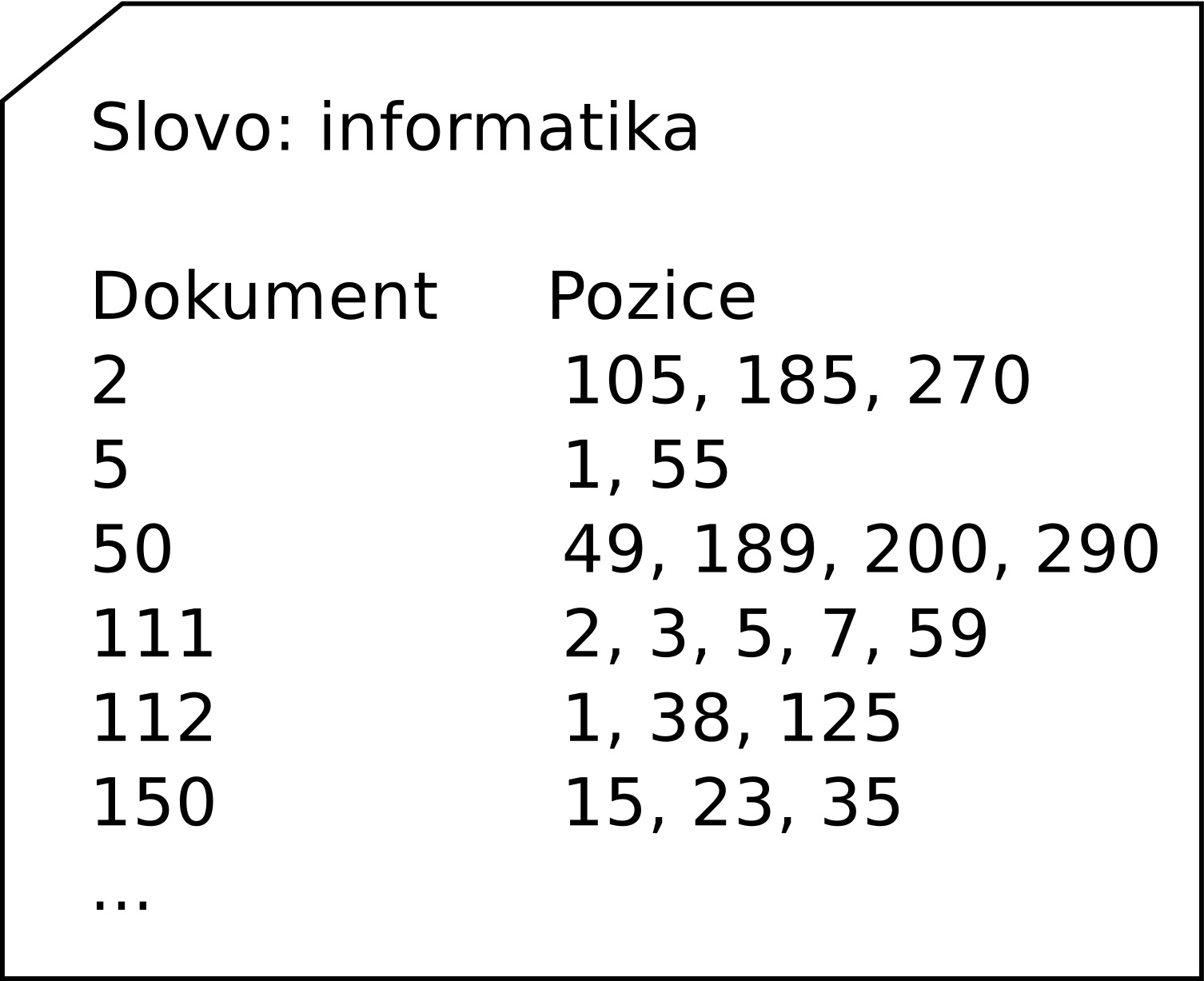
Ukázka indexu/invertovaného seznamu vyhledávače pro slovo "informatika"
Crawler ukládá data do databáze vyhledávače. Data v ní jsou vstupem při indexaci. Stejně jako u crawlování, tak i u indexace se využívá výběrové funkce, která určuje, zda se daný dokument z databáze bude zařazovat do indexu. To, že je dokument v databázi vyhledávače, tedy neznamená, že se nutně musí vyskytnout také v indexu. Výběrová funkce zohledňuje především to, zda již v indexu není podobný nebo stejný dokument.
Při vytváření indexu se ukládají důležité informace, které následně slouží pro rozhodování, které dokumenty se zobrazí ve výsledcích vyhledávání a na které pozici. Jde především o následující data:
- holý text (plain text) rozložený na slova – pro každé slovo má vyhledávač vlastní index,
- téma dokumentu,
- zpětné odkazy, které míří na dokument, a k nim například text odkazu (anchor text), titulek, téma odkazující stránky apod.,
- ranky stránky (PageRank, S-rank apod.),
- jazyk dokumentu,
- typ dokumentu,
- informace o doméně, na které je dokument umístěn.
Pokud se na tato data podíváme z jiného pohledu, lze je také rozdělit na on-page faktory (ty, které se nachází přímo v daném dokumentu) a off-page faktory (mimo dokument – zpětné odkazy apod.).
Stop slova
Čím častěji se slovo vyskytuje v daném jazyce, tím delší bude také příslušný rejstřík/index. Vyhledávače proto často nevytvářejí indexy pro tzv. stop slova. Jde o slova, která nemají samy o sobě žádný význam – spojky, předložky apod.
Kde se index udržuje
Ve vytvořeném indexu se poté již přímo vyhledávají dotazy, které uživatelé zadávají vyhledávačům. S tím souvisí fakt, že vyhledávání musí být velice rychlé – standardně v řádech setin až desetin sekundy.
Z tohoto důvodu je důležité udržovat celý index v operační paměti, která umožňuje rychlý přístup. Operační paměti jsou řádově dražší než pevné disky, ve kterých je uložena databáze vyhledávače. Do indexu se tedy musí ukládat pouze nezbytně nutné informace dostatečné k tomu, aby výsledky vyhledávání zobrazovaly relevantní dokumenty vzhledem k položenému dotazu.
Výstupem z indexace jsou také vypočítané off-page faktory (metadata, zpětné odkazy na další stránky, hashe apod.) daných stránek. Tyto informace se ukládají zpět do databáze vyhledávače a pracuje se s nimi při další iteraci indexace.
Aktualizace indexu
Crawler se v čase jednak vrací na již dříve navštívené stránky, ale také stahuje stránky nové. Z toho plyne, že se musí aktualizovat také index, jinak by vyhledávače nemohly nabízet nejnovější stránky, které crawler právě stáhl.
Obecně může aktualizace probíhat dvěma způsoby:
- přírůstkově,
- hromadně.
Přírůstková aktualizace
Přírůstková metoda je založena na tom, že se nová data z databáze vyhledávače přidávají do současného indexu. V tomto případě je však nutné data zařadit na správné místo v indexu.
Hromadná aktualizace
U hromadné metody se zkontroluje, které dokumenty přibyly v databázi vyhledávače. Z nich se vytvoří nový menší index a nahraje se na výdejový server. Ke spojení těchto indexů tedy dochází až během samotného vyhledávání.
Na tento typ aktualizace indexu musí být správně nakonfigurován výdejový server, aby uměl vyhledávat ve více indexech. V praxi se to řeší často tak, že jednou za časové období (například měsíc) se vytvoří velký kompletní index a dále jsou na výdejovém serveru menší indexy (týdenní, denní, hodinové apod.). Podle Dušana Janovského je hromadná metoda efektivnější pro velké vyhledávače.
Jednou za čas je nutné vystavit nový index a nahradit ten stávající na výdejových serverech. Během nahrazování starého indexu novým je nutné zajistit dostupnost. V praxi je často výdejových serverů více, a proto se výměna indexů provádí postupně na každém stroji.
Nyní by mělo být jasné, proč a jak vyhledávače stahují stránky pomocí crawleru (viz první díl série) a jak z předpřipravené databáze vytvářejí index. V posledním článku se podíváme na to, jak se vydávají výsledky.
Zdroje a další informace
Můžete se podívat na videa Dušana Yuhů Janovského, ze kterých tento článek také čerpá:



