 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


Poté, co si vyhledávač připraví databázi, ze které vytváří svůj index, následuje výdej výsledků. Při něm je důležité vybrat co nejvíce relevantní dokumenty a seřadit je tak, aby odpovídaly hledanému dotazu.
Před čtením tohoto článku doporučuji projít první dva díly o crawleru a indexování.
Když uživatel zadá vyhledávací dotaz do vyhledávače, vyhledávání výsledků probíhá v indexu, který je již předpřipravený, jak bylo popsáno v předchozím článku.
V prvním kroku je nutné, aby vyhledávač pochopil, co dotaz znamená. V praxi jde především o rozklad víceslovných dotazů na jednoslovné – pro ty jsou vybudované rejstříky/indexy. Pokud například do vyhledávače zadám „fakulta informatiky“, vyhledávač rozloží dotaz na „fakulta AND informatiky“. Z toho vyplývá, že dotaz je nutné hledat ve dvou indexech – pro slovo fakulta a pro slovo informatika.
V těchto indexech se poté vyhledají dokumenty, kde se nacházejí obě slova – z matematického pohledu se provede průnik těchto dvou indexů. U vybraných dokumentů je následně potřeba spočítat relevanci a na jejím základě dokumenty seřadit. Relevanci počítá každý vyhledávač podle utajených algoritmů.
Které faktory jsou pro jednotlivé vyhledávače důležité a v jaké míře, lze zjistit pouze pomocí testování a zkoumáním výsledků vyhledávání. Tímto postupem se vždy ale propracujeme pouze ke korelacím jednotlivých faktorů. Na jejich základě nelze jednoznačně prohlásit, který faktor se podílí na hodnocení v určité míře. Nejde tedy o kauzalitu.
Části výdeje výsledků
Vyhledávačům se dotazy zadávají přes webové rozhraní. To následně komunikuje s dalšími komponentami, které rozkládají dotaz a provádějí samotné hledání a řazení. Jednou z těchto komponent je MetaSearch (jde o termín z českého Seznam.cz, Google tuto komponentu označuje jako Root), který rozkládá dotazy a také si výsledky vyhledávání ukládá do mezipaměti/cache.
Díky tomu se zrychluje výdej stejných dotazů; je však nutné zajistit, aby byla cache stále aktuální. V případě vyhledávače Seznam.cz je možné poskytovat výsledky z cache až u 80 % dotazů.
Další komponentou je agregátor, který rozkládá zátěž na jednotlivé počítače, kterých má vyhledávač ve výdeji z důvodu výkonu více. Tyto počítače, označované jako BaseSearch, mají vždy část z celého indexu, je tedy nutné poslat dotaz na všechny zároveň.
Rozdělování databáze/indexu na několik horizontálních částí se označuje jako shardování. BaseSearch vrací vyhledané a seřazené výsledky ze své části indexu. Agregátor s MetaSearchem poté tyto agregované výsledky znovu seřadí. Dále zde existuje komponenta, která vytváří úryvky výsledků vyhledávání, tzv. snippety (titulek, URL adresu a krátký text) – titulkovač (v případě Seznam.cz) nebo Content Server (v případě Googlu).
Na titulkovač zasílá MetaSearch dotazy pro konkrétní dokumenty. Titulkovač má databázi distribuovanou na několik počítačů (podobně jako MetaSearch) z důvodu zvýšení rychlosti výdeje výsledků. MetaSearch poté z těchto dat sestaví stránku s výsledky vyhledávání (anglicky Search Engine Result Page – zkratka SERP) a vrátí ji webové komponentě, jež ji zobrazí uživateli.
Schéma architektury výdeje výsledků je zobrazeno na následujícím obrázku. Fulltextové vyhledávače mají v praxi výdejových serverů více z důvodu rozložení zátěže.
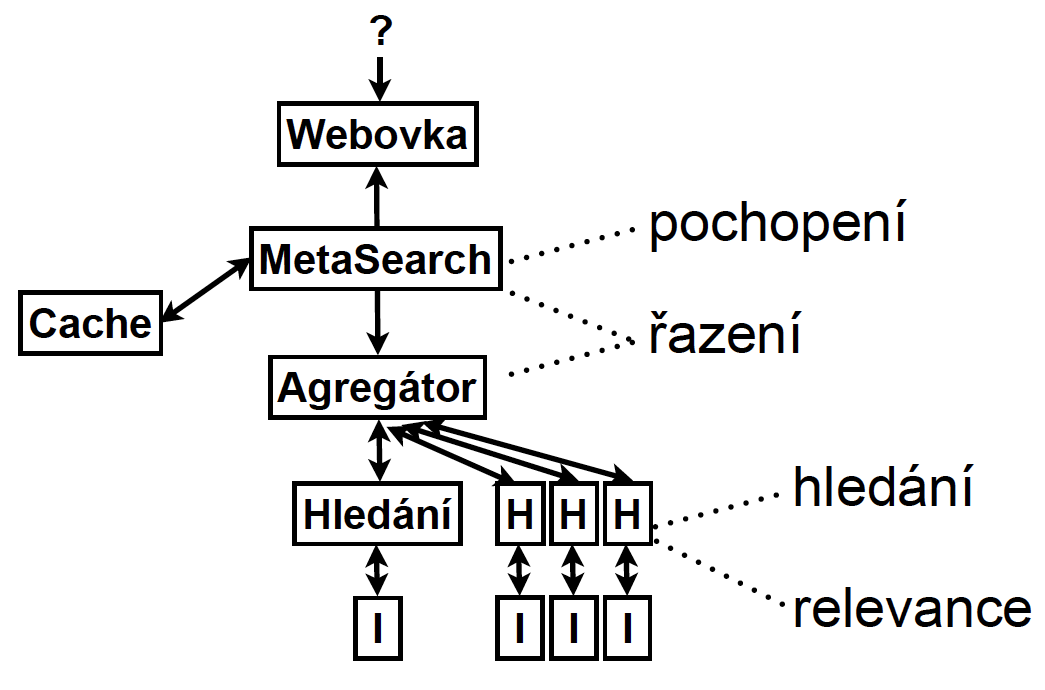
Architektura výdeje výsledků vyhledávání, autor Tomáš Hlucháň ze Seznam.cz
Personalizace při výdeji výsledků
Vyhledávače se snaží pochopit, co chce uživatel nalézt. Děje se tak při rozkladu položeného dotazu. Google jde však ještě dále, kdy si uchovává o každém uživateli určité informace, které následně používá při výdeji výsledků. Pomocí nich upravuje SERP tak, aby byl více relevantní konkrétnímu uživateli.
Informace si Google ukládá jednak do cookies (s platností 180 dnů), ale také do historie webového vyhledávání, pokud je uživatel přihlášen do svého Google účtu. Personalizované vyhledávání na Googlu je dostupné jak pro přihlášené, tak pro nepřihlášené uživatele od 4. prosince 2009. V obou případech lze personalizaci vypnout.
Personalizace na základě vyhledávací historie je založena na tom, že Google upřednostňuje weby, na které již uživatel ve výsledcích vyhledávání klikl. Pokud často vyhledávám například „programování v c++“ a většinou se prokliknu na programujte.com, Google tento web při dalších vyhledávání upřednostní.
Google používá při řazení výsledků také geolokaci uživatele. Jiné výsledky tedy dostane uživatel hledající z Brna a jiné uživatel z Prahy.
Díky personalizaci tedy nelze pozice ve výsledcích vyhledávání Google změřit s naprostou přesností. Průměrnou pozici dané stránky lze zjistit v nástroji Google Webmaster Tools.
Český vyhledávač Seznam.cz personalizaci nyní nepoužívá.
Zdroje a další informace
Toto je poslední ze série tří článků o principu fungování fulltextových vyhledávačů. Dále se můžete podívat na videa Dušana Yuhů Janovského, ze kterých tento článek také čerpá:



