#4 MilanL
Dík.
Tím stavem buňek se rozumí co?
 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
Převod obrazu na elektrický signál u kamery pro strojové vidění s CCD nebo CMOS
Můžu poprosit co je tím myšleno nechápu to.
Po vytvoření obrazu začne probíhat jeho postupné převádění na elektrický signál a jeho číselnou interpretaci A/D převodníkem, k čemuž je potřeba určitého časového intervalu. Po dobu zpracování vytvořeného obrazu snímaného objektuje potřeba, aby nebyl čip osvětlován. Proto je nutné čip opatřit mechanickou závěrkou, která řídí jeho osvětlování a generování obrazu snímané scény.
kontakt: jann789456123@seznam.cz
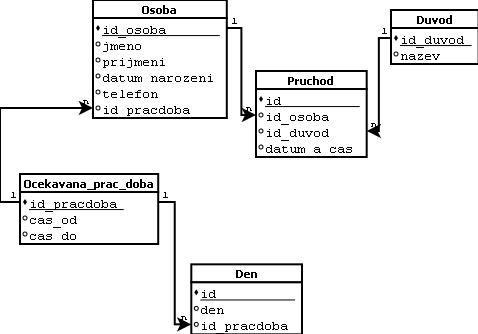
Dobrý den, prosím o radu jak by měl vypadat SQL příkaz na zjištění přesčasů / podčasů k aktuální databázi (viz. obrázek).
Napadá mě tento postup, který nevím jak bych měl správně zapsat v SQL příkazu(ech).
datum_a_cas v tabulce Pruchod oříznout nějakou agregační funkcí a získat jenom TIME a TIME při id_duvod 2 (odchod) odečíst zase ořízlý TIME od datum_a_cas při id_duvod 1 (příchod)
a od toho celého potom odečíst (cas_do mínus cas_od v tabulce ocekavana_prac_doba )
#2 Kit
Myslím array (anglický název). Značí se [ ]. A nevím kdy se použije ty [ ] [ ] x [ ] ?
Tady se něco řeší ne? http://programujte.com/…dmienkou-if/ . Prosím o vykopírování toho pole sem abych si to mohl nějak představit.
Dobrý podvečer. Můžu poprosit Co to je A k čemu slouží funkční analýza u databáze?
Dobrý den, můžu poprosit o vysvětlení věcí kolem php.
Co to je pole?
K čemu to je dobré?
A proč je tolik druhů, jako 1-rozměrné, 2-rozměrné, vícedimenzionální? A jsou rozdíly mezi nimy?
Výhody pole?
Nevýhody pole?
V jakém případě je vhodné to použít, lze u databází a jaký druh u databází?
Existuje nějaká alternativa k poli?
Dobrý večer. Můžu poprosit o někoho jestli by mi prosím vysvětlil rozdíl mezi SQL a DBMS jako MySQL, MSSQL, atd.? A DBMS je synonymum k databázovému serveru a k databázi?
#6 Kit
Můžu tě poprosit o rozdíly mezi těmito enginy a k čemu jsou výhodné oproti tabulce bez enginu? A vytváří se ENGINE také u databáze nebo pouze u tabulek?
AUTO_INCREMENT=6 znamená, že po importu bude mít další vkládaný záznam ID=6
(A proč mám v A.I. hodnotu 6 když v korespondujícím okně zobrazující příkazovou podobu je VALUE 1? Bug nebo mám něco do nastavit? )
Proč sem se ptal, protože tam nemám žádný záznam a automaticky mi to tam hází tu 6, ale já chci jedničku nebo něco jiného, jak jsem psal dříve, tak v příkazovém okně PHPMyAdmin tam je 1 ale v GUI PHPMyAdmin, tak tam je 6. Bug nebo něco jiného?
Zkus na takový záznam UPDATE - změní se i sloupec typu TIMESTAMP.
Celý sloupec nebo jenom příslušný řádek se změní na aktuální datum a čas?
A takže, u toho datetime CURRENT_TIMESTAMP se mi při UPDATU to nezmění na aktuální čas, jestli jsem to dobře pochopil?
-- jsou komentáře, při exportu mají speciální význam pro přechod mezi verzemi.
Ale kdyby to byly komentáře, tak by se ten SQL dotaz (příkaz) nemohl provést při importu nebo se mýlím? A ještě já myslel, že koment je /* */ ?
Dobrý večer. Můžu se ještě zeptat, když budu mít tabulku jmena (id, jmeno, prijmeni, ....) a budou se tam opakovat třeba 5x stejná jména jako Jan Novák, Jan Novák, Jan Mladý, Jan Starý, Jan Synek?
Má se vytvořit pro opakující se údaje další tabulku či to může zůstat v této jedné tabulce - z hlediska 1 - 3.NF?
#4 Kit
Ale u DATETIME se taky automaticky aktualizuje -
viz. priklad z CRETE TABLE ..... `datum_a_cas` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
? Je to tak nebo já pod pojmem automaticky aktualizuje myslím automaticky vkládá a ty myslíš něco jiného,
A ještě mě zajímá, co znamená při exportu z PHPMyAdmin do .sql ty dvě -- (viz. níže)?
`table`--CREATE TABLE IF NOT EXISTS `table`
(
)
ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_czech_ci AUTO_INCREMENT=6 ;
A ještě jedna otázka, k čemu je dobrý ten ENGINE InnoDB, existují i další? Jsou mezi nimi rozdíly?
A proč mám v A.I. hodnotu 6 když v korespondujícím okně zobrazující příkazovou podobu je VALUE 1? Bug nebo mám něco do nastavit?
Jaký je rozdíl mezi datovými typy DATETIME a TIMESTAMP?
Když mám datový typ TIME v jedné tabulce a jinde v druhé tabulce mám DATETIME nebo TIMESTAMP, můžu provádět operace s tou částí kterou potřebuji a to s časem, podobně jako u DATE je parametr / vlastnost MONTH? Například když budu chtít odečíst TIME od DATETIME, jde to? Nebo pracovat třeba jenom s datum a provádět různé operace, apod.
#26 MilanL
Ppprosím tě, o zodpovězení dotazů, jsem to všecko nepochopil.
Person_WTime: ID, ID_Person, ID_expected_time, Begin_date, End_date.
Není tady zbytečné ty sloupečky to begin_date a end_date, když už je to v tom Expected Work Time?
U definice směn je několik možností, bud se nadefinuje model směny Ranní, Noční a program to pak indikuje na základě časů příchodu a odchodu. Nebo se nadefinujou přímo plány směn a pracovníkovi se přidělý daný plán 1 plán vždy pro více pracovníků.
Model, Modely a plány tím se myslí 1 tabulka?
A tím indikuje, jako že do tabulky Ranní se vloží záznam o příchodu daného zaměstnance ráno automaticky dle času příchodu?
A plány směn přímo - 1 tabulka s časy (datum by tam nešel, protože by ta časová doba pak platila pro jeden den a druhý den ranní by pak taky nešla přiřadit té samé osobě, že jo/ne)?
#22 Kit
Kite můžu ještě poprosit o radu.
Na relaci 1 : N tabulka Expected k tabulka Person. Na tomto mi nesedí, když budu mít např. datum_a_cas 1.1.2019 8:00 a to bude přiřazeno N osobám, tak už 2.1.2019 8:00 nemůžu přiřadit té samé osobě a z toho vyplívá, že by mohla pracovat jenom jeden den daná osoba. Je to tak, nebo to chápu špatně?
Prosím o návrh jak to vyřešit.
#20 Kit
Zajímavé, díky.
Jenom, můžu prosit ještě o vysvětlení, jak to, že i když je mezi těmi dvěma tabulkami ta prostřední tabulka (propojovací, vazební), tak existuje na to nějaké pravidlo / standard, že se z vazební tabulky přestává být vazební tabulka se složeným primární klíčem a může se použít jenom id propojovací tabulky? Tohle jde vždycky i v jiném případě udělat, že se složený prim. klíč vazební tabulky nahradí id prim. klíč vazební (propojovací) tabulky?
#15 Kit
Radši to ještě doplním (promiň asi jsem to napsal špatně, mělo to být například).
- osoba 1 důvod 1, potřebuji i důvod 2, 4, 5, atd. (každý reason v určitý date and time)
- osoba 1 důvod 1 v určitý dat. a čas den 2
- osoba 2 důvod 1 v dat. a čas den 1
- osoba 2 důvod 2 v dat. a čas den 1
- osoba 2 důvod 1 v dat. a a čas den 2
A pak si podle mě myslím budu možná potřebovat trojitý PK nebo jaký v Entry (vazební tabulka). Nevím. Prosím o radu. Jinak díky za předchozí odpovědi.
Oprava předchozího obrázku
Mám toto schéma dobře (viz. obrázek)?
OPRAVA K MINULÉMU PŘÍSPĚVKU:
Ano, myslel jsem složený klíč. Mám to dobře?
A tím id_work jsem myslel id_work_time.
Je to potom také dobře, nebo mi tam ještě něco chybí?
-
Dobrý pozdní večer. Prosím o zkouknutí těchto tabulek databáze v textové podobě, zda odpovídají správné normalizaci do 3. Normální datové formy a nemám tam nějaké chyby, nejsem si jist, že je to zcela správně.
# = Primary KEY , FK = Cizí klíč
Tabulky níže s atributy v závorkách
person (#id_person, first name, last name, date of birth, telephone, FK id_work)
person_reason (id, #id_person, #id_reason, date & time)
reason (#id_reason, name)
expected work time (#id_work, date_and_time from, date_and_time_to, id_person, day of week)
#4 Kit
Dovolím si nesouhlasit s tvým tvrzením. 3. NF "Every non-prime attribute of R is non-transitively dependent on every key of R. " viz. https://en.wikipedia.org/wiki/Third_normal_form
A 2. NF (https://en.wikipedia.org/…_normal_form) " (2) not have any non-prime attribute that is dependent on any proper subset of any candidate key of the relation. "
Takže, jestli jsem to pochopil, tak 2. NF je o té redundanci (opakování) stejného konkrétního slova v sloupečku tabulky u vícero záznamů (řádků)?
Prosím někoho o vysvětlení 3. NF (Normální Formy).
Z jednoho zdroje mám, že se jedná o odstranění redundance. A z jiného zdroje, že se jedná o tranzitivní závislost a její odstranění.
Kde / Co je tedy pravda?
#2 Kit
Díky.
Mohl by jsem si to vyhledat nebo v učebnici najít, ale tam to bývá takovou nic neříkající učebnicovou ("abstraktní") řečí a proto mám radši polopatické vysvětlení od někoho kdo tomu aspoň trošku rozumí než nějaké složité odborné termíny, věty, které stejnak nepochopím.
Můžeš mi prosím uvést ještě příklady k těm omezení abych si to dokázal představit, co to vlastně je.
Dobrý den. Co znamenají tyto pojmy: Integritní omezení, Doménová omezení, Referenční integritní omezení?
Datový model a Databázové schéma to jsou dva stejné pojmy nebo vyjadřují něco jiného?
#2 Kit
Ale mě jde o to, že tam píší Logical ERD is a detailed version of a Conceptual ERD. A že by se tam zmínili, že to má být relační schéma, tak to ne. A ještě, že v Physical data model reprezentují návrh vzhledově dle Relačního schématu, který má datové typy a typy atributů jako primární a cizí klíč.
Mají to tam zcela správně ne?
Dobrý den. Můžu se zeptat proč tady
(
https://www.visual-paradigm.com/guide/data-modeling/what-is-entity-relationship-diagram/?fbclid=IwAR1h7xr6IY34W8zeJKsqGclobaxFhuMHmYjxat7yWn2GLbDKsvJ3ua9Evhs#erd-data-models-logical
)
uvádí na všech 3 úrovních modelování databáze - koncepční, logické, fyzické ER diagram, když ten patří jenom do koncepčního modelu a logický model je už Relační schéma (model). A fyzický model to nevím vůbec co by tam patřilo a jak vlastně vypadá? Jaká je věcná správnost výše uvedeného odkazu, respektive informací tam (co je dobře, a co špatně)?