 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu


Používáte Twitter? A znáte The Archivist? Vývojáři poodhalili postup, jakým vytvářeli architekturu aplikace – od prototypu, přes přesun do cloudu na Windows Azure, změny v databázích, opuštění SQL až po finální podobu. Článek ukazuje i to, jaká úskalí může mít nasazení škálovatelné webové aplikace v prostředí Azure.
Úvod
Microsoft se ve svých softwarových laboratořích poslední dobou zaměřuje na spolupráci se sociálními sítěmi (viz například Docs, které využívají Facebook). The Archivist je produkt MIX Labs a slouží, jak název napovídá, k archivování zpráv zasílaných na Twitter (tzv. tweetů), jejich analýze a exportu výsledků. Neumí se vrátit zpět do minulosti, ale jakmile mu zadáte, že má sledovat určitý termín (v dalším textu je tato akce označována jako "hledání"), bude sbírat data a nechá vás prohlížet výsledky v podobě líbivých grafů.
Na adrese http://archivist.visitmix.com/deeedx/5 si můžete prohlédnout archiv, který jsem vytvořil nedávno. Týká se akce Programujte.com - Hledám Auroru a sleduje hashtag #hledamauroru.
Tento článek je volným překladem originálu Architecture Of The Archivist, který napsal Karsten Januszewski. Text jsem navíc doplnil vysvětleními některých pojmů (odstavce kurzívou).
http://www.visitmix.com/LabNotes/The-Archivist-Architecture
The Archivist Architecture
Při tvorbě aplikace jsme narazili na několik architektonických překážek, jejichž řešení si vyžádalo změny návrhu v několika iteracích a došlo i na několik pokusů a omylů. Archivist má tři hlavní funkce – archivaci, analýzu a export – a ačkoliv mohou na první pohled vypadat jednoduše, zvládnout je s ohledem na velké zatížení je docela náročný úkol. Tento článek ukazuje cestu, kterou jsme se při tvorbě architektury vydali.
Architektura první - prototyp
Nejprve bylo třeba zjistit, zda je celá aplikace vůbec realizovatelná. Proto byl velmi rychle navržen prototyp, na němž byla vidět základní myšlenka. Databáze stála na SQL Express a obsahovala čtyři tabulky: Uživatelé (Users), Tweety (Tweets), Hledání (Search) a Archiv (Archive).
Každé hledání bylo propojeno na tabulku tweetů a obsahovalo mimo jiné hledaný výraz, poslední aktualizaci a informaci, zda je aktivní. Tabulka Archiv spojila hledání a uživatele a zabránila redundanci, protože v situaci, kdy dva uživatelé zadají stejný výraz, by jinak došlo ke zbytečnému duplikování dat. Celá databáze vypadala takto:

Tweety vytažené přímo z Twitteru se serializovaly do databázových objektů (vytvořených pomocí LINQ to SQL) a následně ukládaly do databáze. Pro analýzu se naopak data z SQL vybírala do CLR objektů, na kterých se přímo za běhu spouštěly dotazy LINQ. Z těchto objektů bylo možné tvořit různé grafy a přehledy nebo je převést na textové soubory s informacemi oddělenými tabulátory a exportovat do Excelu (opět za běhu).
Ve vývojovém prostředí s jedním uživatelem, jedním hledáním a 100 tweety to fungovalo bezvadně.

Dalším krokem bylo tuhle architekturu zprovoznit v Azure. Role Web se postarala o UI a role Worker zajistila dotazování Twitteru.
Doplnění: Každá služba hostovaná ve Windows Azure je založena na oddělených komponentách, kterým se říká role. V tuto chvíli jsou podporovány dva typy: Web role, která je uzpůsobena pro programování webových aplikací ve stylu ASP.NET, a Worker role, která může na pozadí vykonávat nějakou činnost pro Web role.
Při jednoduchých testech výkonu a zatížení vyšlo najevo, že aplikace se začala plazit až se skoro zastavila. Kde bylo úzké hrdlo? Na dvou místech – za prvé byly neskutečně pomalé „on demand“ dotazy LINQ a spolu s nimi i export do Excelu a jako druhé překvapivě zpomalovalo ukládání tweetů do databáze, které ve vývojovém prostředí vůbec nebylo vidět.
Kromě výkonu se ukázal další problém – databáze se plnila příliš rychle. Tři archivy, obsahující 500 000 tweetů, byly schopné zaplnit úložiště SQL Azure o kapacitě 1 GB.
Nezbylo než se vrátit ke kreslicímu prknu...
Architektura druhá - zaměřeno na SQL
Vždycky jsem byl znepokojen agregačními dotazy LINQ volanými při každém požadavku a očekával jsem, že se budou špatně škálovat. Proto jsem je převedl na SQL Server do podoby uložených procedur. Výkonu to sice pomohlo, ale pořád to nestačilo na zobrazení všech šesti vizualizací, které jsou na úvodní straně. Zkusil jsem tedy převést uložené procedury na indexované pohledy (Indexed Views) a předpokládal, že to problémy vyřeší.
Pak přišla na řadu další potíž, a to velikost SQL databází. První nápad – vytvořit několik databází v distribuované struktuře – provázela skepse, protože nároky Archivistu na škálovatelnost stále rostly. Tohle řešení bylo příliš komplexní a náchylné k chybám. Kromě toho jsem mohl dopadnout tak, že bych musel spravovat třeba 100 SQL serverů. V cloudu... Nic moc.
A ještě jsem měl výkonové problémy při vkládání do SQL Azure. Částečně je to vinou replikačního modelu, který každý insert nedělá jednou, ale třikrát. Pro vložení jednoho záznamu to není problém, ale u hromadných insertů to není úpně nejlepší.
Takže SQL mohlo vyřešit mé analytické problémy, ale už si nedokázalo poradit s úložištěm. A to byla chvíle, kdy jsem se setkal s Joshuou Allenem a Davidem Aikenem a dali jsme dohromady novou architekturu.
Architektura třetí - žádné SQL (resp. méně SQL)
Ti rafinovanější z vás už to nejspíš vytušili: vykašlali jsme se na SQL a začali ukládat tweety do úložiště binárních objektů (blobů). Takže místo abych tweety serializoval do objektů CLR a pak na ně aplikoval LINQ to SQL, jednoduše jsem zapsal informace z Twitter Search API ve formátu JSON do blob storage. Tabulka Tweet přestala existovat.
Doplnění: Akronym BLOB znamená „binary large object“, česky rozsáhlý binární objekt, a jedná se o datový typ, který se používá pro ukládání blíže nespecifikovaných dat. Na rozdíl od třeba čísel nebo řetězců nemá databáze žádné informace, o jaká data jde (nejčastěji se jedná o obrázky nebo zvuky), a vrací je v čistě binární podobě tak, jak byla uložena. V tomto textu bude dále úložiště binárních objektů označováno jako „blob storage“.
Nejprve jsem zvažoval přesun ostatních tabulek do tabulkového uložiště, ale jejich kód fungoval a nezpůsoboval žádné potíže. Navíc informace v nich obsažené zabírají minimum místa a vše je propojeno přes primární klíče. Takže se žádný přesun nekonal a ani nikdy nebyl potřeba – Archivist má nakonec hybridní úložiště: polovina blob storage a polovina SQL Server.
Nabízí se otázka – jak vyřešit sladění obou úložišť? Řešení je prosté: každé hledání má v SQL své unikátní ID, které se používá jako název kontejneru v blob storage. A právě do tohoto kontejneru se ukládají všechny tweety, které jsou relevantní k danému hledání.
Přesun do blob storage zabil dvě archivační mouchy jednou ranou: už nebylo potřeba se zabývat strukturou a řízením všech těch SQL serverů a zcela zmizely potíže s výkonem insertů. Stále však přetrvávaly nedostatky analýzy a exportu. Na velkých sadách dat si braly obě operace příliš velkou daň na to, aby se daly vykonávat za běhu pomocí LINQ.
Nastal čas na další setkání s Joshuou a Davidem. Přichází další Worker roles a fronty Azure (Azure Queues).
Architektura čtvrtá - fronty
Ve snaze vyřešit oba problémy jsem vytvořil v Azure další role typu Worker, které jsem propojil frontami. Pak jsem na ně přesunul zpracování každého z archivů (což zahrnovalo spouštění agregačních dotazů a generování souborů pro export).
K roli Hledání jsem tedy přidal další dvě: jednu pro přidávání a druhou pro agregaci. Fungovalo to následovně:

Role Hledání se zeptala tabulky Hledání na všechny dotazy, které nebyly aktualizovány během poslední půl hodiny. Pokud kontrola dotazu vrátila nové tweety, Hledání přidalo zprávu do fronty roli Přidávání.
Doplnění: Fronty Azure se primárně používají pro přeposílání malých bloků dat (nazývaných zprávy – messages) mezi rolemi. Zprávy jsou ve formátu XML a mohou dosahovat velikosti nejvýše 8 KB.
Role Přidávání vzala zprávu z fronty a přidala nové tweety do hlavního archivu (který byl uložen v podobě textového souboru s daty oddělenými tabulátory). Fajn, to vyřešilo problém s výkonem při získávání správného formátu pro export, protože data v něm byla teď uložena nativně a byla dostupná ke stažení kdykoliv přímo z úložiště.
Když skončilo přidávání, byla vložena zpráva tentokrát do fronty Agregátoru. Tato role deserializovala archiv do objektů pomocí mého vlastního engine.
Jakmile jsem měl grafy objektů, spustil jsem dotazy LINQ. Výsledek každého agregačního dotazu byl pak uložen do blob storage ve formátu JSON. Výborně! V tuto chvíli všechny agregační dotazy, jejichž zpracování někdy trvalo třeba až pět minut, byly UI k dispozici takřka okamžitě. (To je důvod, proč je výkon u grafů obrovských archivů tak zrádný.) Tyto JSON objekty jsem navíc mohl poskytnout vývojářům jako API.
Doplnění: Pojem „graf“ v tomto případě neslouží k vizualizaci dat (jako například grafy v Excelu), ale blíží se spíš teorii grafů, protože představuje několik objektů propojených vazbami.
Architektura fungovala nějakou dobu a tvářila se jako dobrý kandidát na finální nasazení.
Než se objevil další problém.
Potíž byla tentokrát v tom, že agregační dotazy se začaly hromadit. Pro archivy, jejichž velikost rostla k 500 000 tweetů, se agregace projevila jako úzké hrdlo, protože doba zpracování jediného archivu se mohla vyšplhat až k pěti minutám. Archivy se navíc aktualizovaly každou půlhodinu a neustále jich přibývalo, takže čas potřebný pro běh agregačních dotazů se nasčítal. Možným řešením by bylo poslat na dotazy více instancí, lepší ale bylo od aplikace poněkud odstoupit a podívat se pořádně, co vlastně děláme. Jsou opravdu potřeba všechny ty agregace? Zabíraly nejen čas, ale i cykly CPU, což byl parametr, který nebylo možné přehlédnout vzhledem k tomu, že Azure se účtovalo od hodiny práce CPU (CPU-hour).
Doposud se agregační dotazy spouštěly každou půlhodinu znovu na každý archiv, který obsahoval nové tweety. Celý smysl agregačních dotazů měl ale být v získání přehledu o tom, co se s daty dělo v průběhu času. Změnily se výsledky dotazů tak moc mezi archivem s 300 000 a archivem s 301 000 tweety? Ani ne. A vedle toho se všechno zpracovávání mnohdy dělalo pro archiv, který si někdo prohlédl třeba jednou denně, pokud vůbec. Smyslem Archivistu není hledání v reálném čase, ale sledování trendů a analýza.
Pak mě to napadlo: opravdu musím spouštět dotazy každou půlhodinu?
Architektura pátá - žádné fronty
Rozhodli jsme se (docela pozdě) spouštět agregační dotazy pouze jednou za 24 hodin. Změnil jsem agregační roli tak, že místo používání front se spouštěla podle časovače stejně jako role Hledání. Pak jsem rozdělil práci role Přidávání a přesunul její logiku do Hledání a Agregace.
Na téhle architektuře je hezká jedna věc – úplně se zbavila front. Ve finále to znamená, že celá aplikace je jednodušší, a v softwaru platí: čím méně koleček, tím lépe. Poslední architektura tedy vypadala takto:
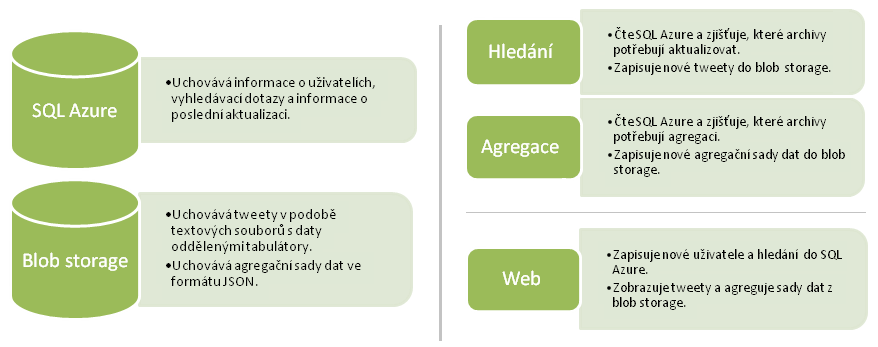
Hledání i Agregace jsou zapouzdřeny v dynamických knihovnách (DLL), takže se dají volat přímo z role Web (když uživatel do databáze zadá první dotaz) nebo pracovní role (když je archiv aktualizován). Obě pracovní role se tedy spouští na základě časovače.
Celkem pozdě v průběhu návrhu jsme museli udělat další změnu ve fungování Hledání. Role totiž posílala dotazy na Twitter každou půlhodinu pro každý z archivů, což se nám zdálo jako kanón na vrabce (obzvlášť u archivů, které neměly tolik tweetů). Bylo zřejmé, že bude nutné zbytečné dotazování přepracovat, protože Twitter Search API definuje konečný počet žádostí za hodinu.
Řešením byl dotazovací algoritmus s pružným degradováním (elastic degrading polling algorithm). Když to řekneme jednoduše, znamená to, že na základě množství tweetů, které hledání vrací, se snažíme určit, jak „žhavý“ daný archiv je. Detailně se algoritmem zabývá zvláštní článek.
Závěr
Archivist byl opravdovou výzvou a tento článek se ani nepřiblížil k dalším věcem, které jsme museli v průběhu vývoje řešit (zprovoznění grafů ASP.NET pod Azure, deduplikaci a Twitter Search API, čtení a zápis do blob storage, nepříjemnosti deserializace formátu JSON, rozdíly výchozích DateTime mezi SQL Serverem a .NET, nesnáze při snaze o debug v Azure a mnoho dalšího). Ale podařilo se!
Mnohem zajímavější ale nejspíš je, že veškerý zdrojový kód The Archivist je k dispozici jako open-source, takže svou vlastní instanci může provozovat kdokoliv.



