 TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
TIP: Přetáhni ikonu na hlavní panel pro připnutí webu
#2 hlucheucho
Čistě teoreticky, horní limit účinnosti tepelného stroje je dán účinností Carnotova stroje a ta je závislá na poměru teplot, mezi kterými stroj pracuje
Příspěvky odeslané z IP adresy 46.13.186.–
Pavel
Pavel
#3 Thomas_Kr
Prostě AttributeError: 'Namespace' object has no attribute 'p_dataset_config' je prostě bug a "produkčním" kódu by se to stávat nemělo. Nelze pracovat s atributem, který v momentě používání neexistuje.
V query.py se ta hodnota nastavuje v if __name__ == '__main__': bloku, tedy pouze pokud je query.py spouštěn přímo, pokud se pouze importuje, tak ten kód neběží. Proto si myslím, že by to v tom initu mělo být.
Pavel
#1 Marek
Protože čísla indexuješ podle x, a ne podle i nebo b
Sub main()
Dim cisla(100) As Integer
Dim i As Integer
Dim hledaneC As Integer
Dim pocVys As Integer
Dim b As Byte
i = 0
pocVys = 0
Do
cisla(i) = InputBox("Zadavejte cisla, ukoncete 0")
i = i + 1
Loop While cisla(i-1) <> 0
hledaneC = InputBox("Zadejte hledane cislo")
For b = 0 To i
If cisla(b) = hledaneC Then
pocVys = pocVys + 1
End If
Next
MsgBox "Pocet vyskytu cisla bylo " + Str(pocVys)
End SubPavel
#1 Thomas_Kr
Co tak zběžně koukám, tak args.p_dataset_config, se nastavuje pouze pokud se spouští skripty train.py a query.py přímo a to se v scripts/pixelpick-dl-cv.sh neděje, děje se tak v případě těch dvou zbylých .sh.
Potom je ta chyba jasná, není to tím že by byla splněna ta podmínka, ale tím, že args nemá položku p_dataset_config. Myslím si, že byl v args.py v __init__ měla být nastavena výchozí hodnota, která tam není, tj. něco jako parser.add_argument("--p_dataset_config"), který pokud není dodán, je jako výchozí None.
Pavel
Domácí úkoly se neřeší tím, že pošleš zadání na několik fór a budeš čekat, kdo ti to udělá.
https://www.itnetwork.cz/…357e58256381
Pavel
Třeba takto, ale nevidím důvod, proč nepracovat přímo s polem hodnot.
import string
## import data
with open('file.txt', 'r') as f:
data = [list(map(int, line.split(', '))) for line in f.readlines()]
## assign to variables
row = 0
for i, val in enumerate(data[row]):
try:
exec(f'{string.ascii_lowercase[i]}={val}')
except(IndexError):
break
print(a, b, c ,d, e)Pavel
#100 BDS
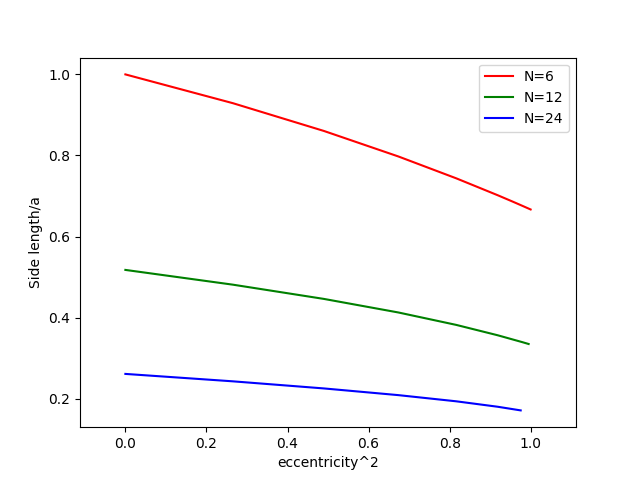
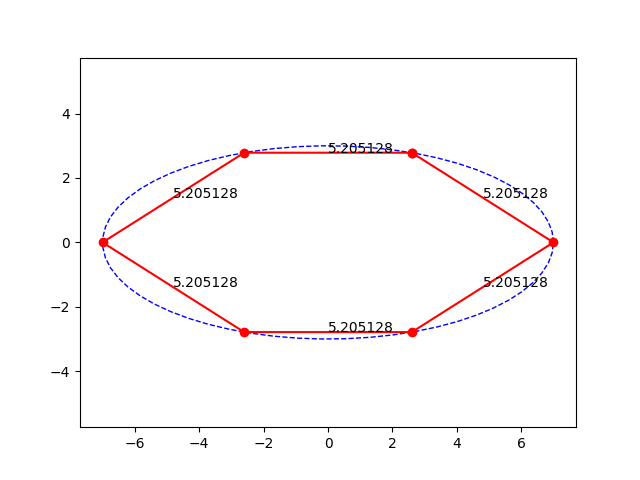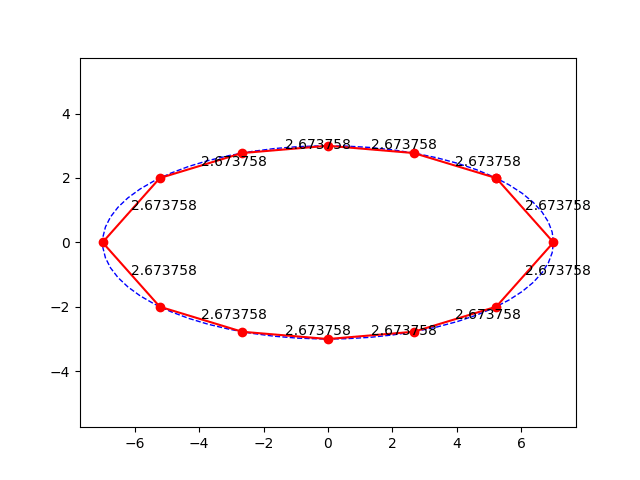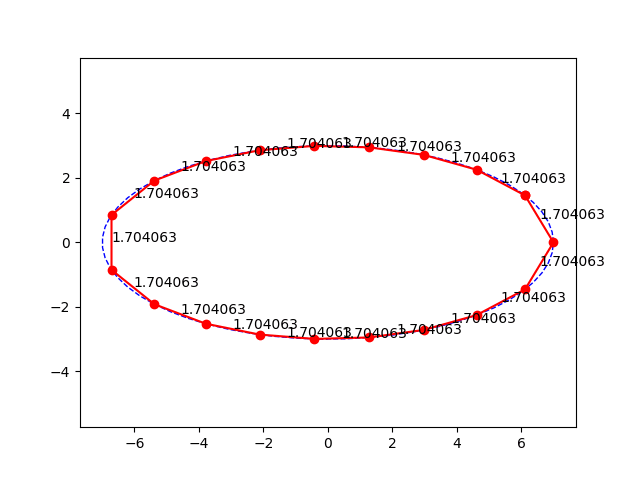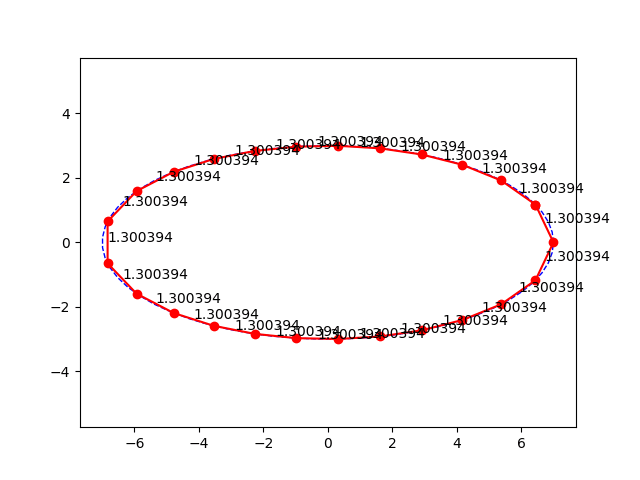
Postup je celkem primocary, zvolil jsem pocatecni bod na elipse, nastrelil jsem vzdalenost mezi body jakozto polomer kruznice a hledal pruseciky. Pak jsem na konci hledal, jestli jsem za nebo pred pocatecnim bodem a upravil jsem nastrel polomeru metodou puleni intervalu. Ale jak rikam, je to strasne citlive na nastrely. Samotny vypocet (delam to v Pythonu) trva asi 0.2s. Vychazi pekne grafy, asi by se dal udelat nejaky fit na vypocet delky strany primo. Nicmene, jsem jenom delnik, nerad bych zbytecne popichoval analyticke matematiky.
Pavel
Zkoušel jsem pro Jerryho tupý numerický přístup hledejme body na elipse, které jsou požadovaně daleko od sebe. Jsem jenom dělník a na základce jsme matematickou analýzu neměli. Nicméně, je to strašně citlivé na "zploštělost elipsy" a na počáteční nástřely. Někdy to funguje, ale je to zajímavý problém, přitom taková blbost.
Pavel
#74 Jerry
Jako že když jedna strana je 5 a druhá 4,3, tak je to jako malá chybka? Dyť je to 14%, a jeto dáno právě tím že to není kruh, takže to nelze řešit rovnoměrným dělením obvodu.
Asi by se dala hledat kružnice o vhodném poloměru, kterou budu cestovat po elipse a protínat ji, tak abych se na konci potkal ve stejném bodě, ale nebude to úplně sranda.
Pavel
#70 Jerry
Tak obrázek no:
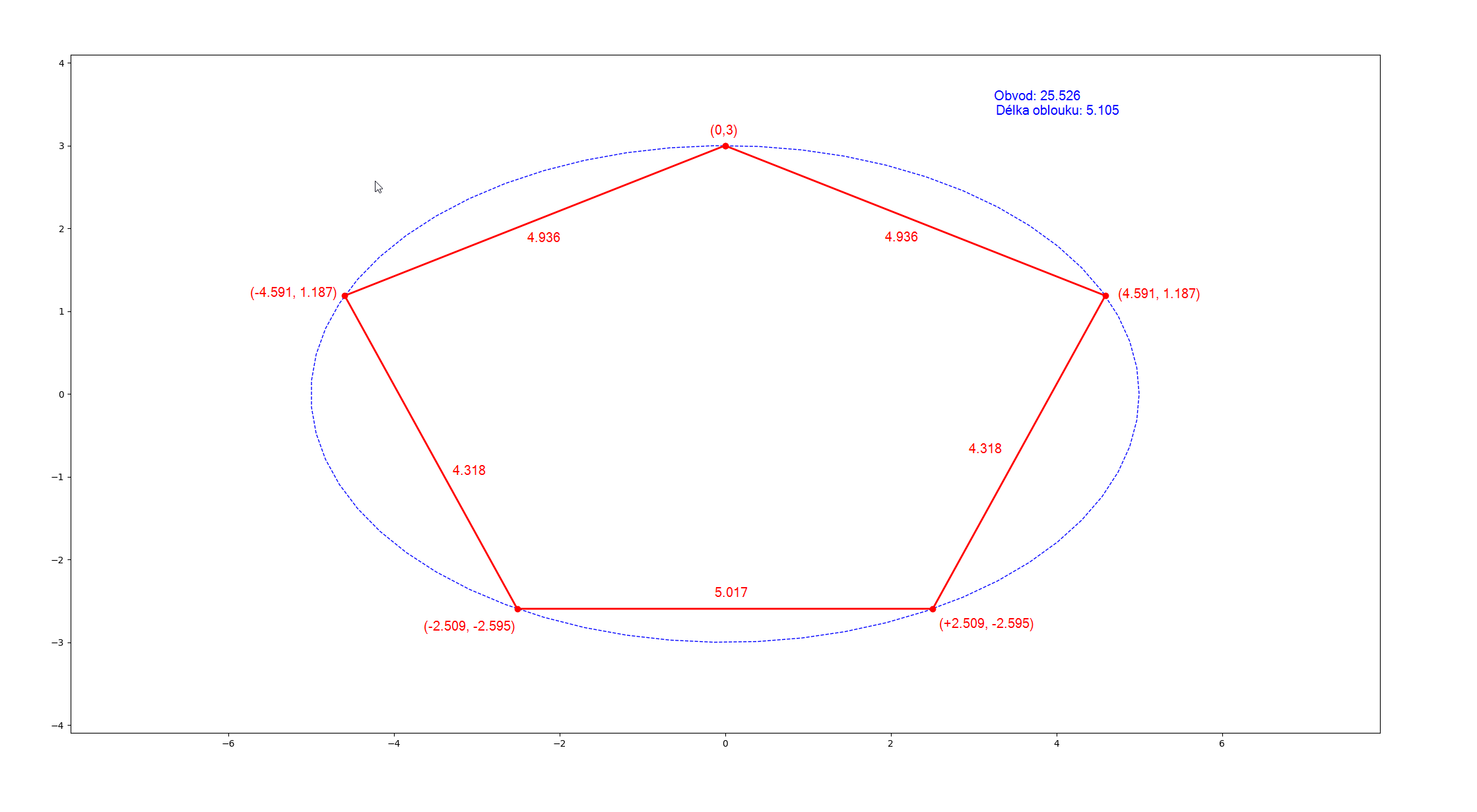
Pavel
#62 Jerry
Ano, eliptický integrál se počítá pomocí nekonečné řady (případ pythonu a knihovy SciPy), Ramanujana nechme stranou. Tudíž, když spočeteš integrál s přesností na 5 desetiných míst, ale délky sečen se liší +- 0,5 pro malé polygony (s rostoucím počtem hran ta chyba klesá). Tak to není chybou aproximace ale tím, že stejně dlouhý segment neznamená stejně dlouhou sečnu, protože ta elipsa je splácnutá. Kdyby sis to místo opakování toho samého napsal, a pak sem dal obrázek a nějaké výsledky, tzn. délku oblouku pro daný počet stran, třeba 5-úhelník a pak délku jednotlivých stran.
Pavel
#48 JerryM
Já to chápu, ale když bude délka toho "eliptického oblouku" stejná, vezmeš souřadnice těch bodů a pythagorovou větou spočteš vzdálenosti mezi nimi (délky sečen), tak nebudou všechny stejné.
Když jsem si to udělal stejně jako tady, spočítal obvod elipsy a rozdělil na N bodů, tak ačkoliv byly segmenty stejně dlouhé, délka sečen nikoliv.
https://math.stackexchange.com/…-ellipse-arc
Pavel
#44 JerryM
Rozdělením obvodu na N bodů, rozdělíš elipsu na N stejně dlouhých segmentů, ale propojením těch bodů úsečkami nevznikne pravidelný n-úhelník, protože každý segment je jinak křivý. Pokud chce BDS pravidelný polygon, tak tohle není cesta. Proto jsem se ptal.
Pavel
Nejspíš dost vytrvalý troll, píše souběžně na dvě fóra, https://forum.zive.cz/viewtopic.php?f=922&t=1320923&st=0&sk=t&sd=a&start=1140
Pavel
Budeš si muset najít někoho jiného, já domácí úkoly nikomu nepíšu ani za peníze.
Pavel
A na co se ptáš?
Pavel
#1 AshiaToka
1) Určitě to nemá reálné řešení, ta funkce představuje horní polovinu kružnice o poloměru 1
2) Nevím, co je otázkou. Jinak y´=1 ti říká, že je to derivace nějaké lineární funkce se směrnicí 1, tj. integrálem je nějaká přímka rostoucí pod úhlem 45 ° (je jich nekonečně mnoho), totéž u té druhé derivace, jen tam to bude klesat. Pokud si to všechno vyplotuješ, tak zjistíš, že ty derivace jsou v 0 nespojité, tudíž existují jenom jednostranné derivace a protože se nerovnají, tak ta funkce logicky nemá derivaci v 0, není hladká.
Pavel
A ten mesh_rectangle je funkce odkud, to neni matlabovska knihovni funkce.
Jinak pokud je Scilab odvozeny z Matlabu, tak jenom budes prepisovat prikaz za prikaz aby sedel vysledek.
Pavel
#1 fanda
Pokud chceš, aby ti to někdo dělal jako "zakázku", tak to dej do inzerce a odměnu dej někde mezi 5 - 10 násobekem toho, co máš teď ve variantě +.
S tímhle postupem se ti ta výuka docela prodraží a tvá použitelnost bude strmě klesat, ale když myslíš, že se ti zrovna domácí úkoly vyplatí outsourcovat.
Pavel
Jeste mi doslo, ze to samozrejme bude najde i hodnotu a placeholder v inputu. Takze po ulozeni hodnoty do promene je treba input "vycistit".
<script>
function checkInput() {
try {
var inputEL = document.getElementById('search')
var query = inputEL.value;
inputEL.value='';
inputEL.placeholder='';
if (window.find(query, false, true) || window.find(query, false, false)){
alert(query + " found");
}
else{
alert('Not found');
}
}
catch (e) {
alert(e);
}
inputEL.placeholder="Meno...";
}
</script>Pavel
#4 Pavel
<form action="" id="form2">
<div>
<input type="text" id="search" autocomplete="off" maxlength="8" placeholder="Meno...">
<input type="button" id="submit_form" onclick="checkInput()" value="HĽADAŤ">
</div>
</form>
<script>
function checkInput() {
try {
var query = document.getElementById('search').value;
if (window.find(query, false, true) || window.find(query, false, false)){
alert(query + " found");
}
else{
alert('Not found');
}
}
catch (e) {
alert(e);
}
}
</script>Pavel
OK, to jsem spatne pochopil. Nicmene window.find vraci true pokud nalezne a false pokud ne.
Ve vychozim nastaveni bere ohled na mala a velka pismena a hleda smerem dolu.
Pozn, Zbavil bych se tech eventu v inputu a prendal bych je do js pres addEventListener.
Jinak tohle by melo hledat spravne:
Pavel
http://kod.djpw.cz/sfbd
Pavel
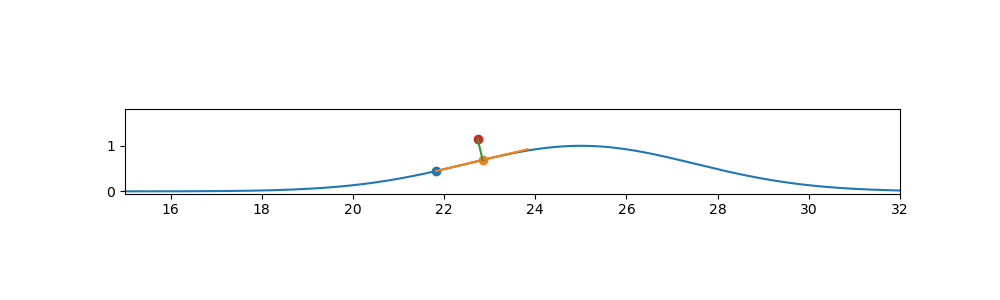
Pavel
Tak tak kolmice nemuze byt kolma, protoze je spatne spocitana.
P1 = (x[-C-l], y_tan[-C-l])
ax.scatter(*P1)
b = (x[-C], y_tan[-C]) # druhy bod musis taky brat z tecny
ax.scatter(x[-C], y_tan[-C])
u = [b[0] - P1[0], b[1] - P1[1]] # tady jsi odecital spatne
plt.scatter(*u)
u_per = (-u[1], u[0]) # tady musis prehodit znamenko
shorten = 0.45
P_per = (b[0] + shorten * u_per[0], b[1] + shorten * u_per[1])
plt.scatter(*P_per)
plt.plot([b[0], P_per[0]], [b[1], P_per[1]])
ax.set_aspect('equal', 'box') # tohle ti zajisti stejny meritko
plt.show()
Jinak pocitat tecnu na 1000 bodu je trosku overkill. kdyz staci 2.
Pavel
Tohle jsou mozne varianty.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib as mpl
fig, ax = plt.subplots(figsize=(10,3))
x = [0.3,0.6,.5,.4]
y = [0.7,0.7,0.9,0.9]
coords = list(zip(x,y))
trapezoid = patches.Polygon(coords, fill=False)
trapezoid2 = patches.Polygon(coords, color="red", fill=False)
trapezoid3 = patches.Polygon(coords, color="blue", fill=False)
t2 = mpl.transforms.Affine2D().rotate_deg_around(*coords[0], -45) + ax.transData
t3 = mpl.transforms.Affine2D().rotate_deg(-45) + ax.transData
trapezoid2.set_transform(t2)
trapezoid3.set_transform(t3)
ax.add_patch(trapezoid)
ax.add_patch(trapezoid2)
ax.add_patch(trapezoid3)
ax.axis('equal')
plt.show()Pavel
def merge(lst):
L = range(len(lst))
for i in L:
# stejne po sobe jdouci hodnoty
if i < L[-1] and lst[i] == lst[i + 1]:
lst[i] = lst[i] + lst[i + 1]
lst[i + 1] = 0
# hodnoty s 0 mezi
elif i < L[-2] and lst[i + 1] == 0:
lst[i] = lst[i] + lst[i + 2]
lst[i + 2] = 0Pavel
Stejneho vysledku, pokud chceme mit seznam unikatni cisel o dane delce, lze dostahnout i takto:
import random
pocet = 6
voted = list(range(1, pocet + 1)) # [1, 2, 3, 4, 5, 6]
random.shuffle(voted) # in-place zamichani seznamu
print(voted) # zamichany listPavel
import random
voted = []
while len(voted) < 6: # chceme 6 cisel
number = random.randint(1, 6) # vygenerujeme nahodny int v rozsahu 1 az 6
if number not in voted: # zkontrolujeme jestli cislo neni v seznamu
voted.append(number) # pridame cislo do seznamu
print(voted) # vypiseme seznamPavel
V linuxu se .py skript spouští tuším: python3 /home/asus-josef/Plocha/prime.py
Pavel
% je modulo operátor, tedy vrací zbytek po dělení, pokud platí numberToCheck % x == 0, znamená to že dané číslo je dělitelné x beze zbytku, a tedy není prvočíslo, tudíž vracíš/return False.
Pokud ve vnitřním for cyklu nevrátíš False, tedy žádné x v intervalu <2, cislo) není dělitelem toho čísla, narazil jsi na prvočíslo a vracíš True.
Pavel
Časově úspornější varianta:
from math import isqrt # isqrt, Python 3.8
def is_prime(number):
if number < 2:
return False
for x in range(2, isqrt(number) + 1):
if not number % x:
return False
return TruePavel
def is_prime(number):
for x in range(2, number):
if (number % x == 0):
return False
return TruePavel
Krom toho odsazení, bys měl ošetřit vstup čísel 0 a 1, které nejsou prvočísla.
Ještě taková drobnost, tenhle algoritmus funguje OK, ale prochází zbytečně mnoho hodnot.
Nakonec, a tohle už je trochu hnidopišství, doporučuju se podívat na https://www.python.org/dev/peps/pep-0008/
Karel
Problem je v materialu, mas tam leskly material s nulovou hrubosti a svetlo kolmo na model, zadne pozadi, takze dokonaly odlesk splyva s pozadim.
Karel
Pokud to neni tajne, tak to muzes nekde nasdilet, takhle me dochazeji napady.
Karel
Jak mas nastavenou kameru
- je v perspektivnim modu?
- neni prilis daleko vzhledem k ohniskove vzdalenosti, tam by potom mohl hrat roli i clipping, tj. text se pri otoceni dostane pres hranici, ktera je u kamery nastavena
Jinak verze 2.79, je dnes uz zastarala, doporucuju prejit na aktualni verzi 2.90.
Karel
Aby mel text hloubku je treba ho prevest na mesh a pak extrudovat v kolmem smeru.
Karel
#1 Bohumil
Změň re.match na re.search.
Z dokumentace:
Pattern.match(string[, pos[, endpos]])
If zero or more characters at the beginning of string match this regular expression, return a corresponding match object. Return None if the string does not match the pattern; note that this is different from a zero-length match.
Pattern.search(string[, pos[, endpos]])
Scan through string looking for the first location where this regular expression produces a match, and return a corresponding match object.
Karel
Karel
https://pypi.org/project/pywin32/
Karel
Jeste se muzes zkusit jestli to neni tady
Karel
Tak v tom blenderu otevri Desktop, na to obrazku jsi teda o slozku vys
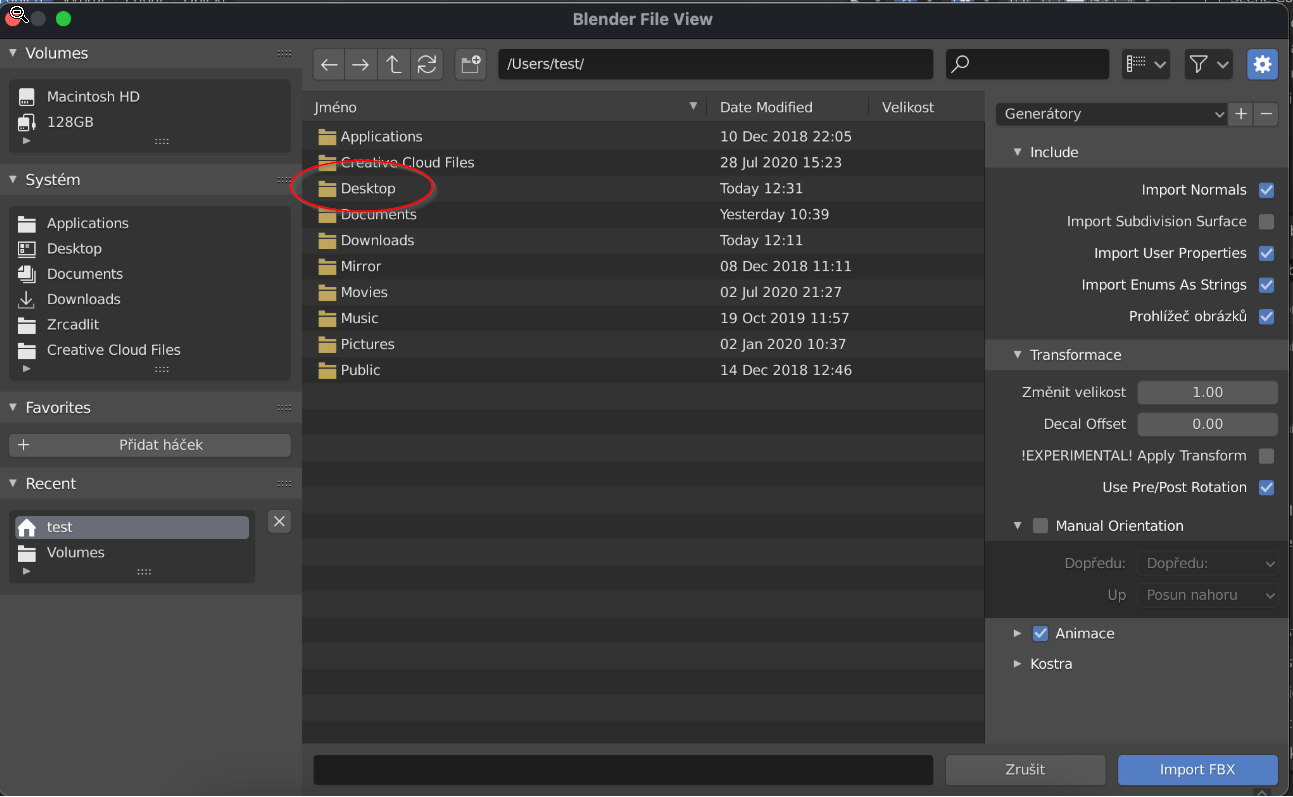
Karel
Na Macu jsem nikdy nedal, ale kdyz si v linuxu otevres terminal (to muzes i na Macu) a podivas se do Users/test/
das vypis slozky (ls), vidis tam ten soubor a tu slozku?
Karel
#10 padikcz
Jeste me napada, kdyz se po importu podivate v blenderu do konsole (Window/Toggle System Console)
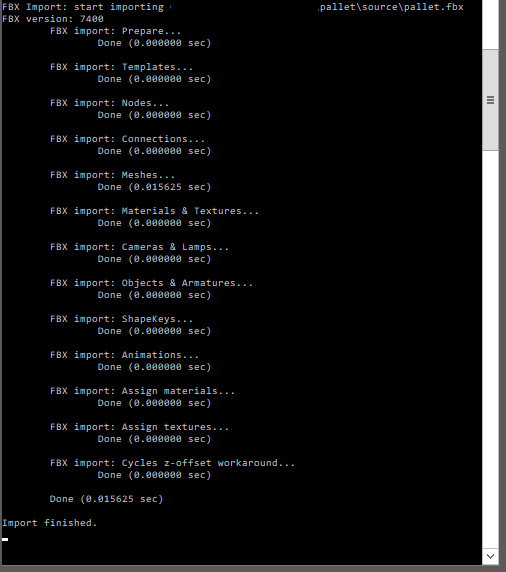
Pokud tam je nejaka chyba, tak by bylo dobre to nahlasit.
Karel
Tady je blend s pridanymi texturami
Karel
#7 padikcz
Model jsem stahnul ve formatu fbx, stazeny zip rozbalil, a pres import v blenderu naimportoval palet.fbx v ..\pallet\source. Model se korektne naimportoval.
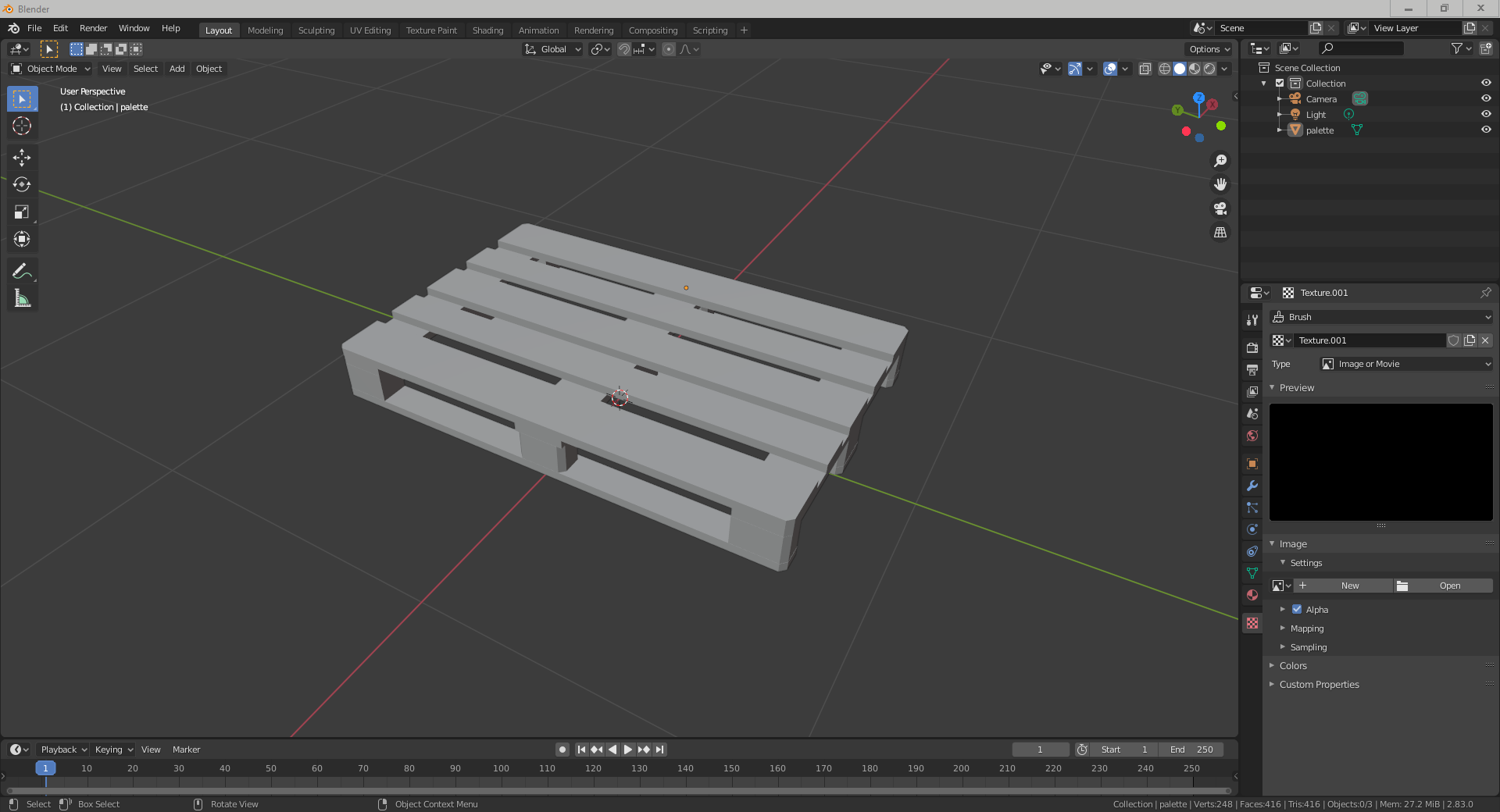
Karel
#3 padikcz
Blender zobrazí složky prázdné pokud neobsahují žádný soubor s příponou .blend. To je výchozí nastavení filtru (ikona trychtýře) v dialogu pro otevření souboru. Pokud zrušíš zaškrtnutí u všech filtrovaných položek uvidíš celý obsah složky. Pokud chceš importovat jiný typ souboru, použij import v nabídce file.
Karel
V této fázi mohu nabídnout pouze morální podporu.
Adam, do toho!!!
Adam, do toho!!!
Adam, do toho!!!
Pavel
Je tam par syntaktickych chyb (import, uvozovky) a ten kod urcite nic "nevyhvezdickuje".
timhle dosadis tak akorat za kazdou hvezdicku cislo
c = str(number)
line += c Pavel
#12 Pavel
A ještě obrázek.
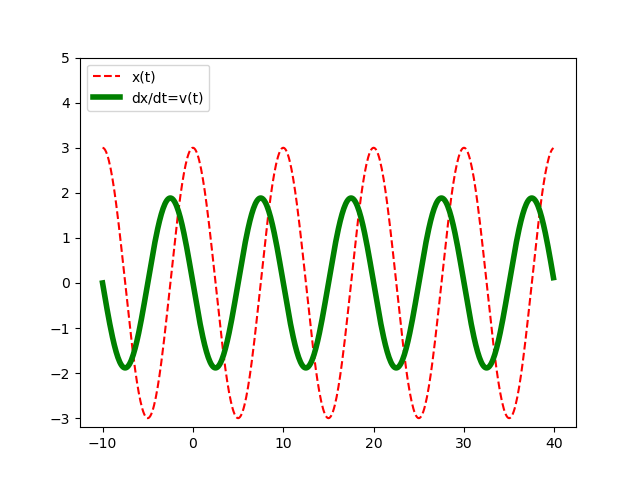
Pavel
Pokud je to předpis pro výchylku, tak rychlost by měla být jeho derivací podle času tudíž amplituda vyjde +-3*2*pi/10, tj +-1,884
